本文最后更新于:2023年12月7日 下午
论文笔记 Exploring Temporal Concurrency for Video-Language Representation Learning
论文链接:ICCV 2023 Open Access Repository (thecvf.com)
代码链接(暂为空库):https://github.com/hengRUC/TCP
人大高瓴人工智能学院+京东的一篇ICCV23,23.9月发布,与同团队的一篇CVPR2023 HIghlight前作联系紧密,本文也会进行介绍。这篇文章主要提出了两个Loss,分别探索长视频模态间的时序共现性和模态内部的动态演变性,从而进行更好的多模态表征学习。
额外参考:
同团队前作(CVPR23 Highlight):Modeling Video as Stochastic Processes for Fine-Grained Video Representation Learning
同团队数据集前作:Long-Form Video-Language Pre-Training with Multimodal Temporal Contrastive Learning
借鉴的NLP领域原作(ICLR22 Oral):Language Modeling via Stochastic Processes
借鉴的李飞飞原作(CVPR19):D3TW: Discriminative Differentiable Dynamic Time Warping for Weakly Supervised Action Alignment and Segmentation
研究思路
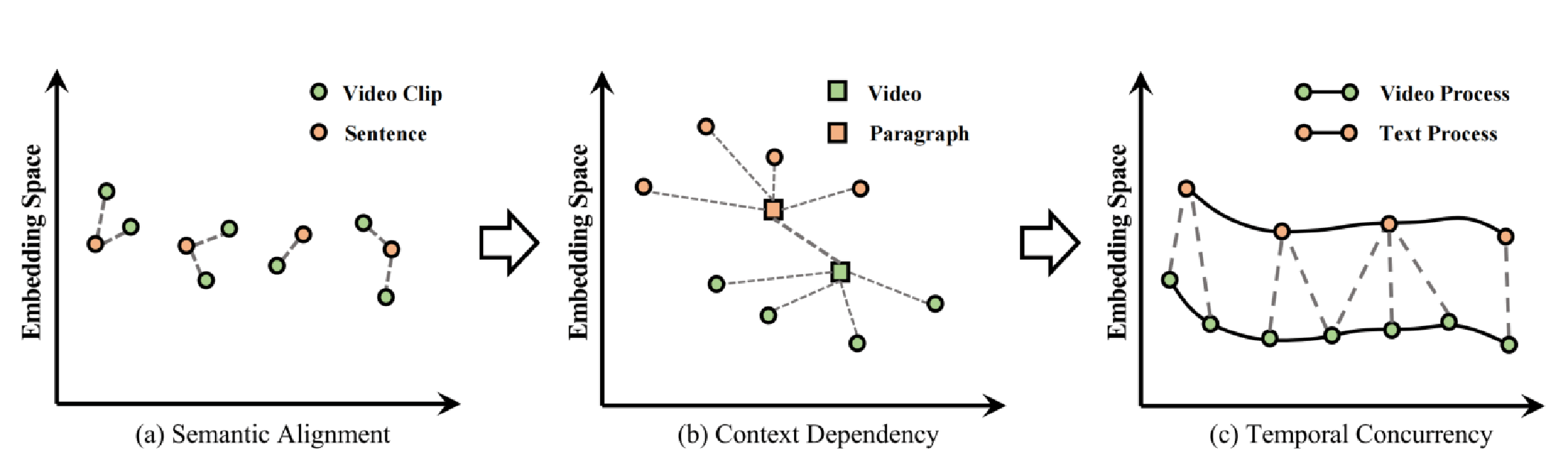
如上图所示,目前的Video-Language模型一部分像(a)那样,进行离散的跨模态对齐,处理短视频【类似CLIP、HERO、Frozen】。它们没有充分利用时序信息(短视频时序性不强)。另一部分像(b)那样,利用了长视频的时序信息,但是添加了额外的时序模块来获得全局表征,然后进行跨模态对齐【HD-VILA、MERLOT】。它们虽然考虑到了时序信息,但是没有考虑到两个模态序列的一致性或共现性(concurrency)。
这篇文章认为VL学习需要考虑模态内的时序信息以及模态间的时序对齐,提出了Temporal Concurrent Processes(TCP)的方法,即将两个模态建模为一种具有时序相似性的过程。视频在播放的时候显然是有时序性的,视频的进行是有一种内在的逻辑的,比如一个炒鸡蛋的教程视频,会先打碎鸡蛋,然后再将鸡蛋放到锅里炒,最后盛出。同样,视频对应的语言也有时序性,比如教程视频中,旁白一步步的介绍步骤。而且,两个模态的时序性还是相互关联的,其演变顺序是相同的,不可能视频是打碎鸡蛋->炒鸡蛋->盛出鸡蛋,而文本是打碎鸡蛋<-炒鸡蛋<-盛出鸡蛋。
这篇文章对于模态间和模态内分别提出了基于soft-dynamic time warping(soft-DTW)的损失函数和Process-wised Regularization Term(PRT)损失函数。其中,PRT是其前作CVPR23 Highlight提出的Modeling Videos as Stochastic Process(VSP),其思路如下:
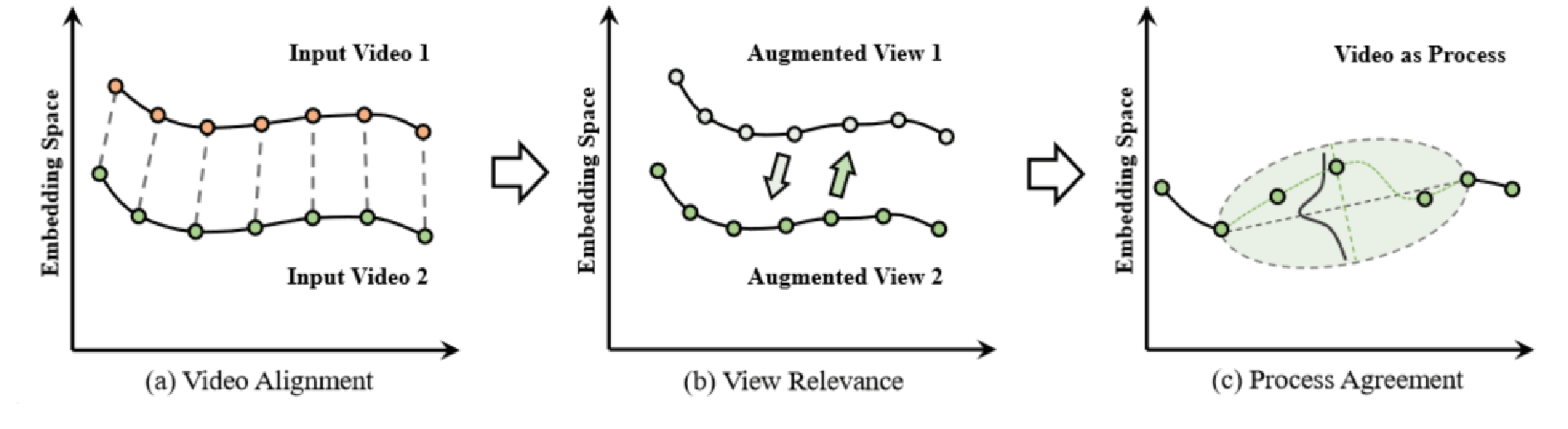
对于细粒度的视频表征学习来说,有的进行Video Alignment任务的方法如(a)所示,对于两个视频的相同时间的特征进行匹配,需要特定的数据集(比如同一个动作,有多个视角的视频);有的如(b)所示,对于同一个视频的不同数据增强view进行对齐(图像上如SimCLR、MoCo)。这篇文章认为其他方法忽视了视频内在的动态过程特点,所以本文将视频建模为一种随机过程(如©所示),具体来说是布朗桥过程(Brownian bridge),并使用基于过程的对比学习损失来进行表征学习。
方法
基础框架
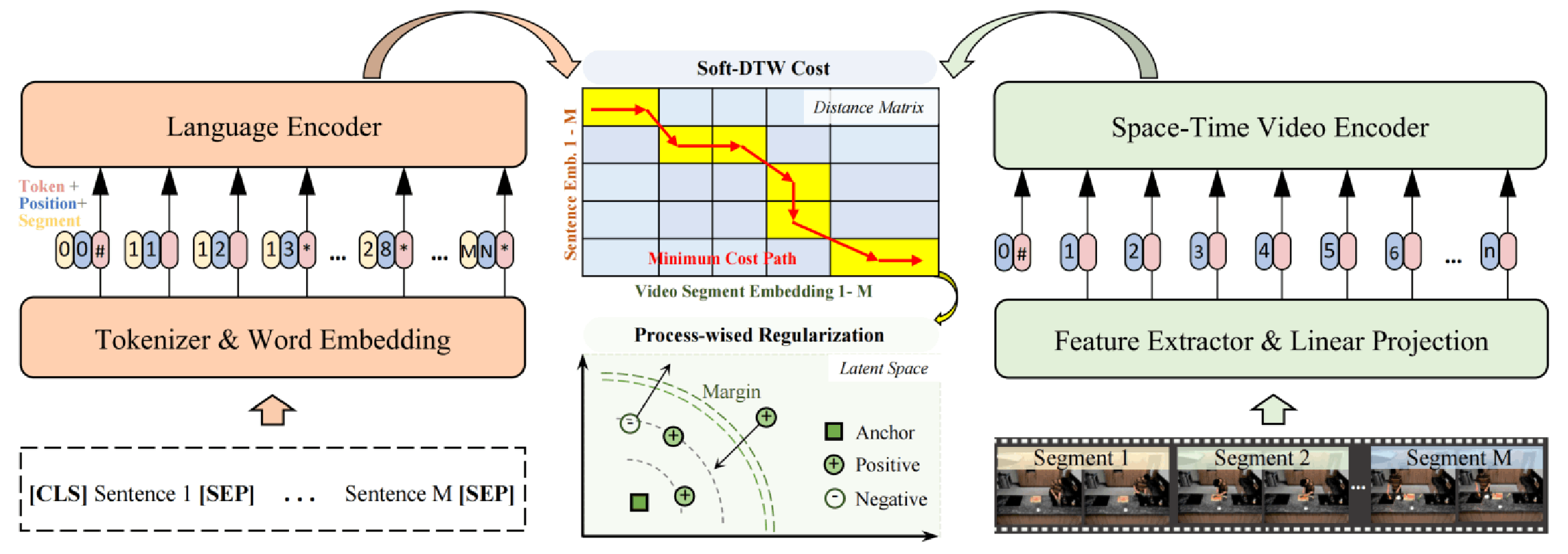
如图所示是这篇文章的基础框架,Language Encoder是BERT-base,Video Encoder是Swin Transformer(IN21K预训练)+AvgPooling,输入数据是平均120s的长视频和对应的有多个句子的段落文本。
在论文叙述中,应该是video包含segment,而segment包含clip,一个clip包含多帧,多帧的swin特征通过avgpool得到C维的clip级特征;文本则是Paragraph包括多个sentence,每个sentence都有对应的一个特征。但是实际上,貌似直接用的是segment的特征,没说怎么通过clip级别特征得到的。
锐评这个框架的话,其实对时序没做什么特殊的处理,感觉是一个比较弱的baseline。
Soft-DTW
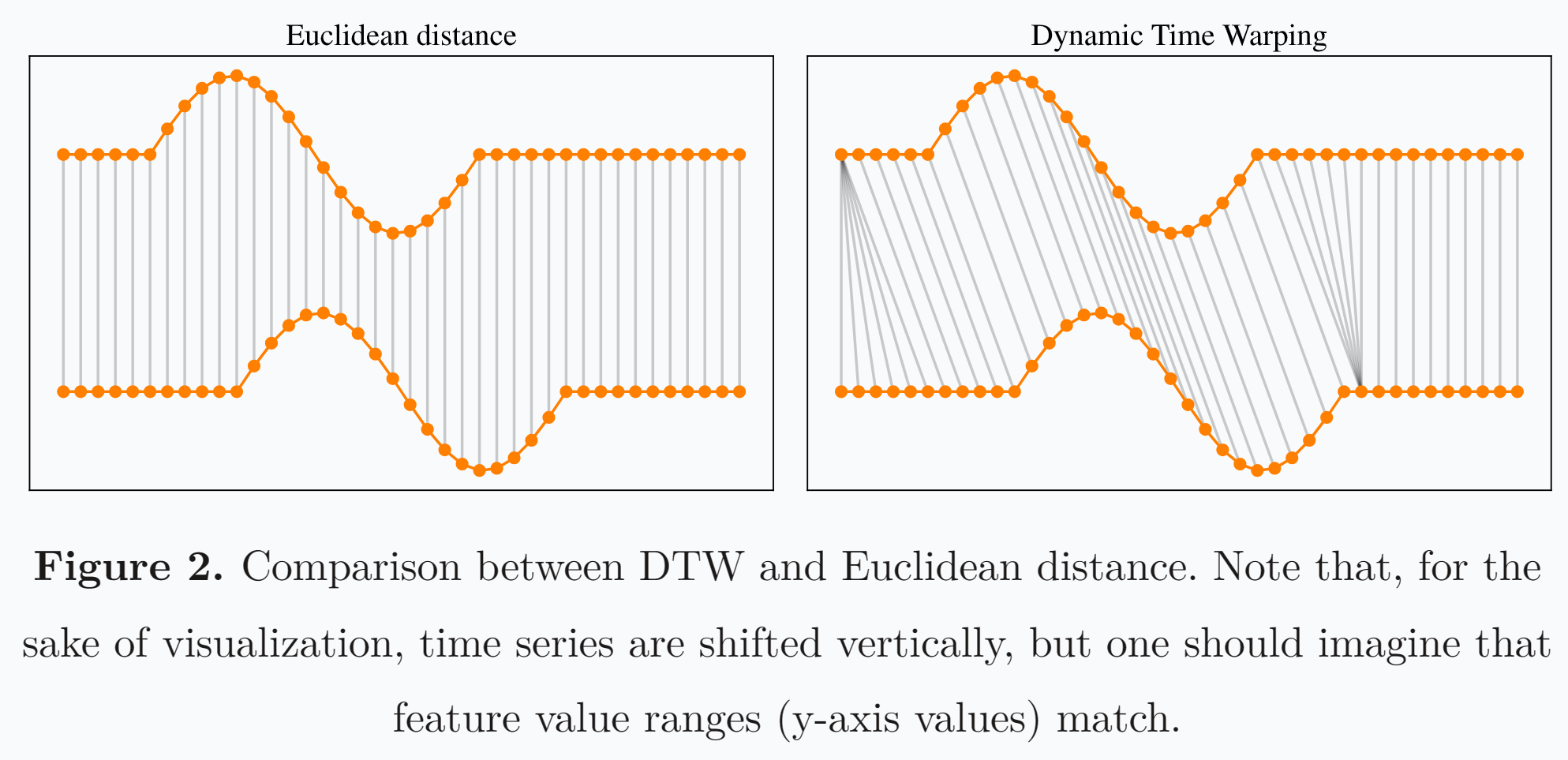
DTW算法最早用来识别两段语音是否为同一个单词,如下图所示,上下两条波形非常相似,但是假如使用欧几里得距离来计算,由于没有对齐,结果相似度并不会很高,而假如使用DTW算法,使一个点能对应另一段语音里的多个点,那么就会使波形对齐,从而使相似度的计算更加合理。
之后,李飞飞将DTW拓展到了深度学习视频领域(D3TW: Discriminative Differentiable Dynamic Time Warping for Weakly Supervised Action Alignment and Segmentation),进行Weakly Supervised Action Alignment任务。
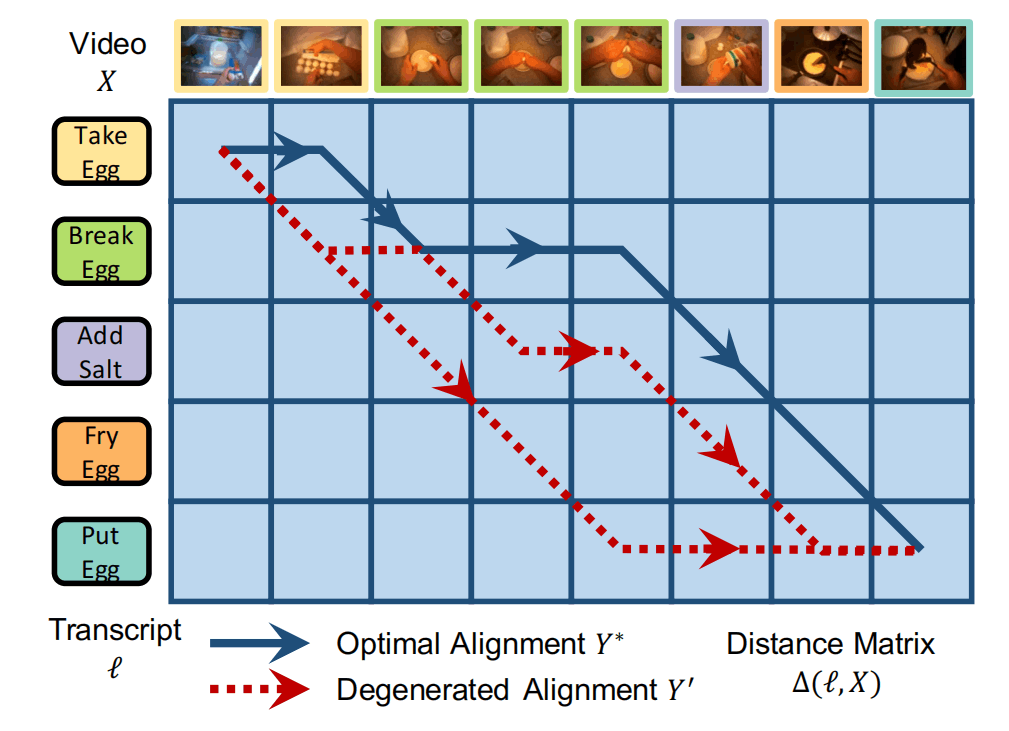
Weakly Supervised Action Alignment就是给你一个长视频,还有按照顺序排布的过程标签,需要模型求出每个标签对应的视频时间段,并且符合时间段并集是整个视频、没有交集的条件。这种情况的两个序列长度不同,并且提取出的特征可以计算相似度,所以应用DTW算法如下:
- 首先确定一个距离矩阵(不需要全部计算),表示标签与帧的距离,并令第一个标签与第一帧对齐。
- 之后根据更近的距离,选择↘️或➡️方向走,直到走到最右下角,就确定好了一条路径。
如图蓝色路径就是最终确定的路径,通过这个方法,就能从粗粒度的两个序列中获得更细粒度的自监督信号。然而,在深度学习中,“选择更近的距离”蕴含了min操作,而min是不可微分的,所以李飞飞论文使用了soft-minimum操作,如下所示,使用这个公式,在λ→0的时候,结果就会接近于序列最小值,而且这个操作有利于梯度的传递。
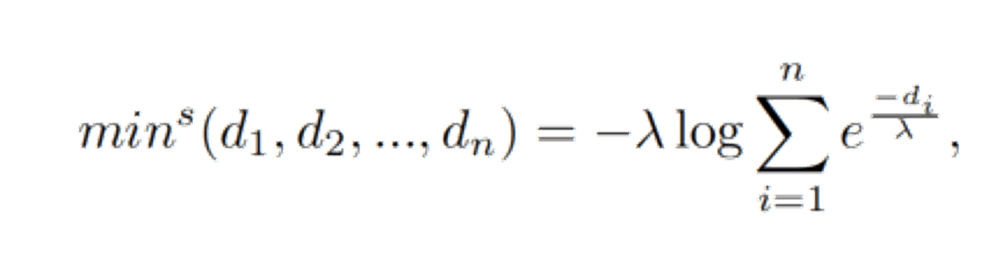
具体的推导可见下面这个pdf:https://www.johndcook.com/soft_maximum.pdf