论文笔记 LanguageBind Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment
本文最后更新于:2023年12月5日 中午
论文笔记 LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment
北大主做的一个ImageBind的升级版,论文最早在23年10月挂载Arxiv上,并在之后有持续的更新。论文解决的问题与ImageBind类似,就是通过类似CLIP的方式,进行N种模态的对比学习,将不同模态统一到同一个语义空间。
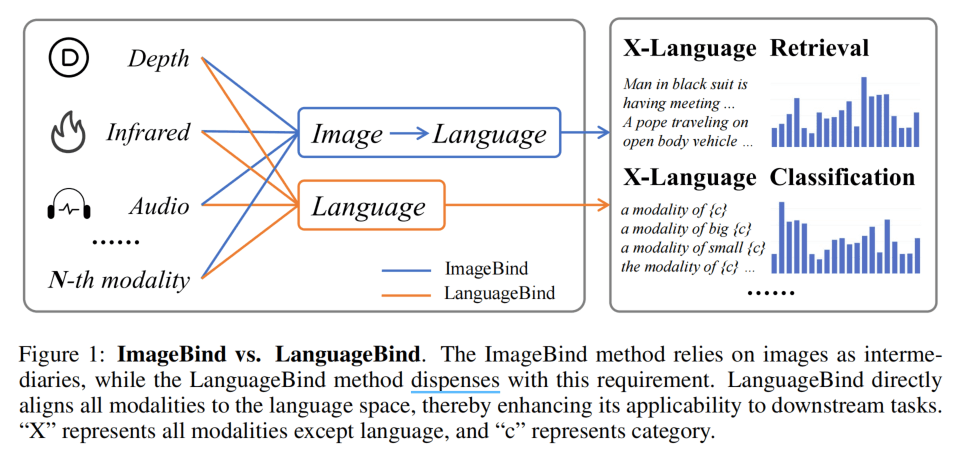
ImageBind用Image进行Bind是因为存在图像这种公共的模态,而这篇文章使用Language进行Bind就是解决了数据上的问题,提出了VIDAL-10M数据集,包含视频、热力、深度、音频以及它们对应的文本数据集。数据集的构建很大程度借助了目前的基于AI的生成网络。结果就是获得了更优秀的Zero-shot能力,并且代码开源做的不错,Issue回复也很积极。
方法
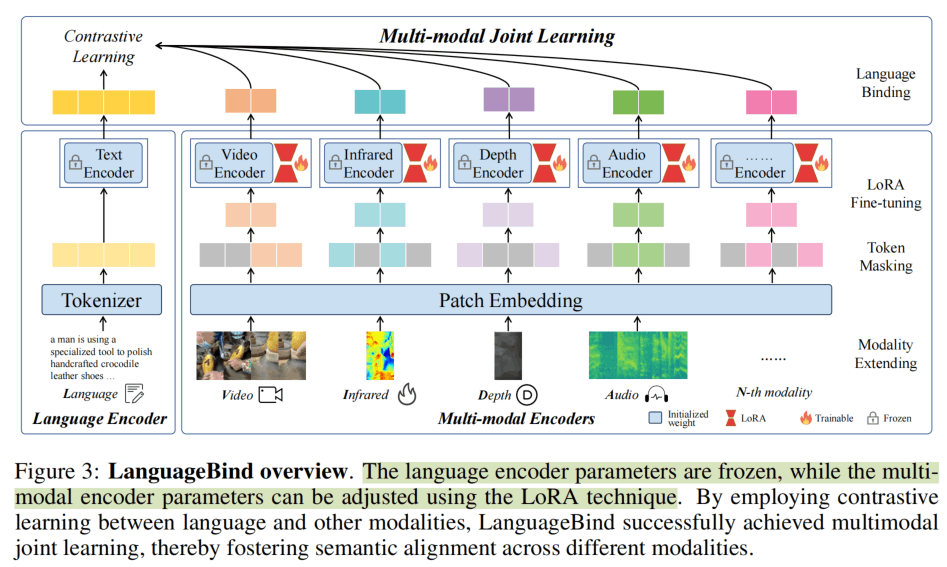
LanguageBind的方法与ImageBind一样简洁,甚至形式上更加对称和美观。如上图所示,除了语言以外的模态的Encoder都是24层1024维patch14的ViT(ViT-L/14),并且继承OpenCLIP-Large的权重。为了保持对称,数据上会进行一些适配,单通道的热力图和深度图会复制到三个通道;音频也同样变成10s的梅尔频谱,同时也复制到三个通道上。文本模态则是12层768维的小一点的接近BERT-base的编码器,使用BPE tokenizer。
与ImageBind相比,LanguageBind的参数量低了一个级别。
训练上,可能是国内算力没那么富裕,所以使用LoRA进行微调,并且使用类似MAE的方式进行Token Masking,即Patch Embedding之后根据比例丢弃50%的token,使训练加速到原来的4倍。
这里Patch Masking的表示很简洁,马克一下:
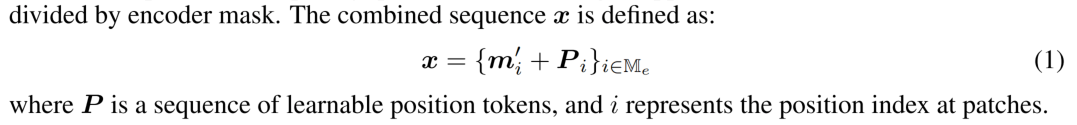
训练的方法和CLIP、ImageBind类似,但是其他所有的模态都和Language进行对比学习,Language Encoder的参数保持不变。
数据集:VIDAL-10M
这篇文章的数据集也是重要贡献点之一,VIDAL-10M数据集包括3M 视频-语言、3M 热力-语言、3M 深度-语言和1M音频-语言数据,加起来一共10M。
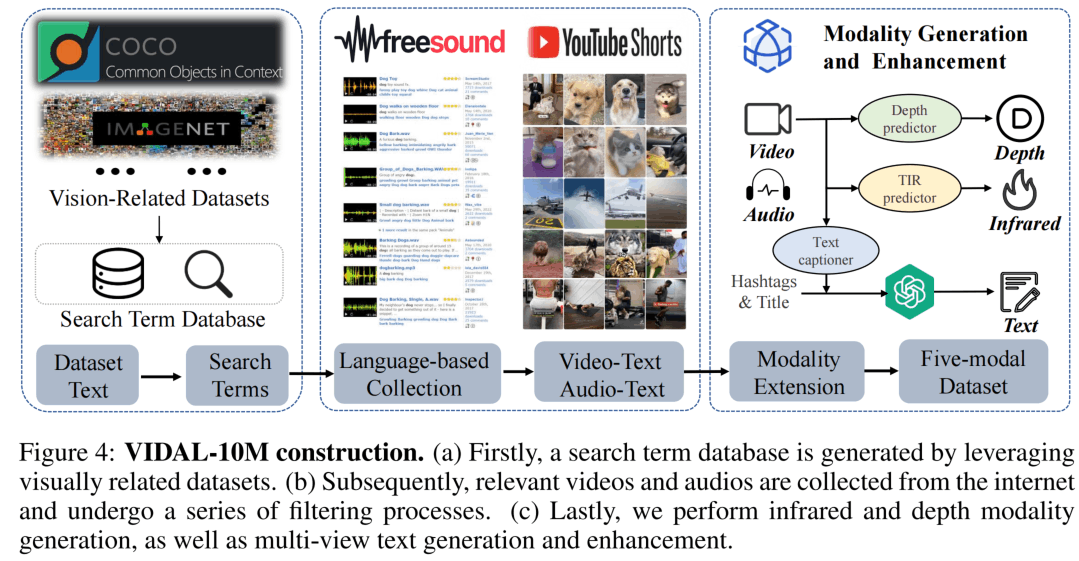
数据集的构建如上所示,首先从COCO、ImageNet、MSR-VTT数据源的文本中通过动词和名词的词频分析,获得100K个搜索项(Table9),然后通过这些词去Freesound(音频网站)和YouTube Shorts(短视频网站)上进行搜索、爬取和过滤,得到视频和音频的数据。这里在短视频网站爬取是因为作者认为短视频的语义更加集中明确,效果更加好。
之后,使用sRGB-TIR模型来生成视频的热力图数据,使用GLPN模型生成视频的深度图数据。这里依赖的是深度估计和热力估计领域的SOTA模型。
对于视频对应的文本,采取下图这种方式进行生成。首先视频抽取关键帧使用一个SOTA的Image-Captioning模型OFA来获得静态的caption。之后,利用一个多模态的LLM mPLUG-owl来综合利用视频标题、标签和Image caption得到视频的caption,最后再用ChatGPT进行一波润色。对于音频对应的文本,文中好像没怎么说,应该是爬取下来就有对应的文本了。
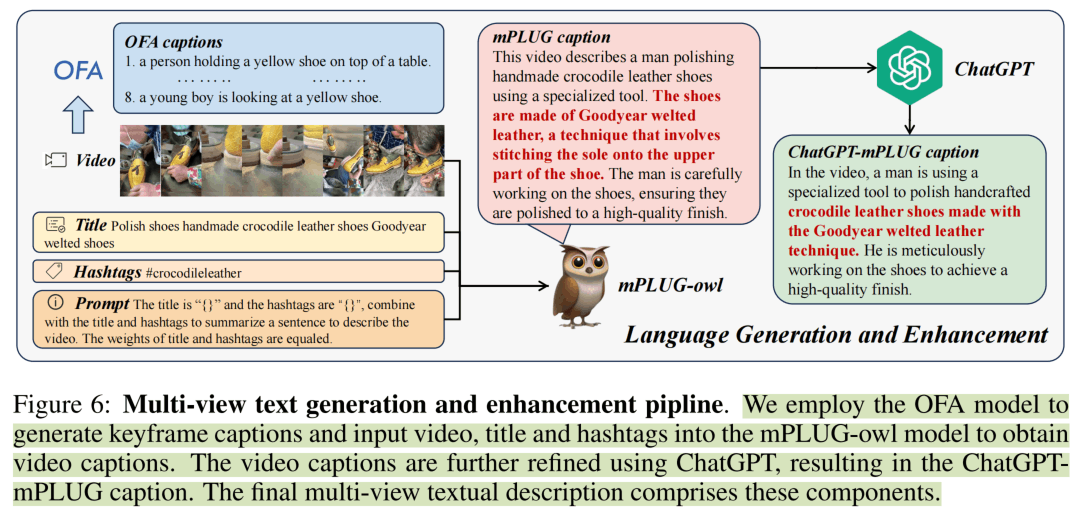
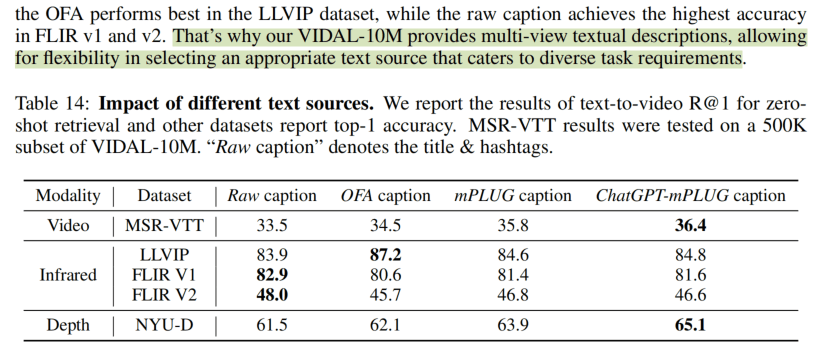
然而,在这里看一个附录中的实验,发现热力图数据集用那些title&hashtag作为文本训练效果反而好,文章没有探究为什么,但是数据集提供了所有阶段的文本。
此外,文中对视频数据进行分析,因为是从短视频平台爬的,所以基本都是竖屏的数据,不是横屏的。
目前数据发布情况:
视频ID和各个阶段文本标注以及发出来了,有百度网盘和Google网盘的链接,比较友好。但是很奇怪没有找到Hashtags。
热力图和深度图作者说有20T,正在努力整理发布。
实验
实验太多啦,选择个人感兴趣的一些来展示和分析。主要的下游应用如下图所示,可以用语言来检索任一模态,可以对任一模态进行Zero-shot的分类。
发现LanguageBind的效果真的很不错,在Zero-shot Video retrieval上,做了更多数据集的比较,同时使用的数据量也不是特别多。与最接近的ImageBind相比高了不少。
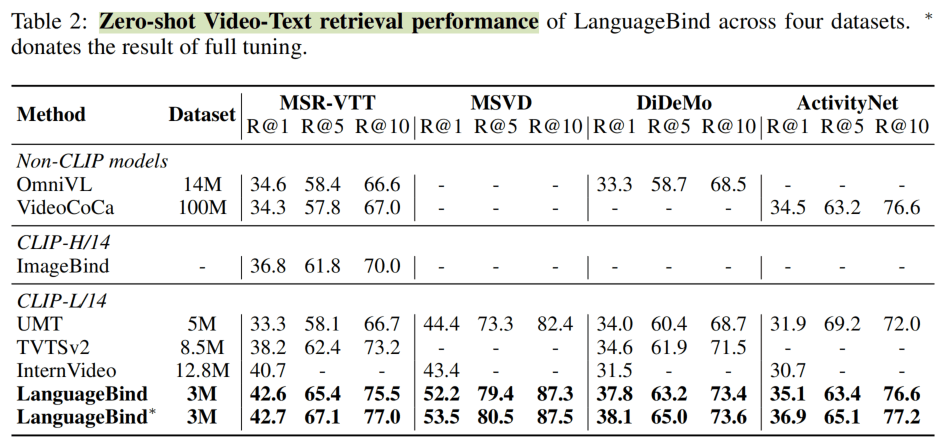
Table3则展示了数据集的优越性,使用CLIP4Clip这个baseline,把HowTo100M替换成VIDAl之后,各种指标都有上升。

Table4则是做分类的结果,这里ImageBind的Video的50.0其实不算是它的结果,因为就完全没有训练,应该算OpenCLIP的Zero-shot结果,而这个表的OpenCLIP则是经过了multi-view/crop的trick的结果。LanguageBind对于视频编码器进行了微调,效果也应该好一些点,这个比较我觉得没什么意外(甚至觉得低了一点点)。
Depth的结果,其实也不能算是一个fair的比较,因为ImageBind是做emergent zero-shot,即没有利用深度-文本进行训练,但是这里还是可以比较的,结果发现效果好了很多。同样,在热力图上也是ImageBind由于做Emergent,性能低了一些。总的来说,这里想说的应该是构造配对的数据比依赖emergent的效果好。

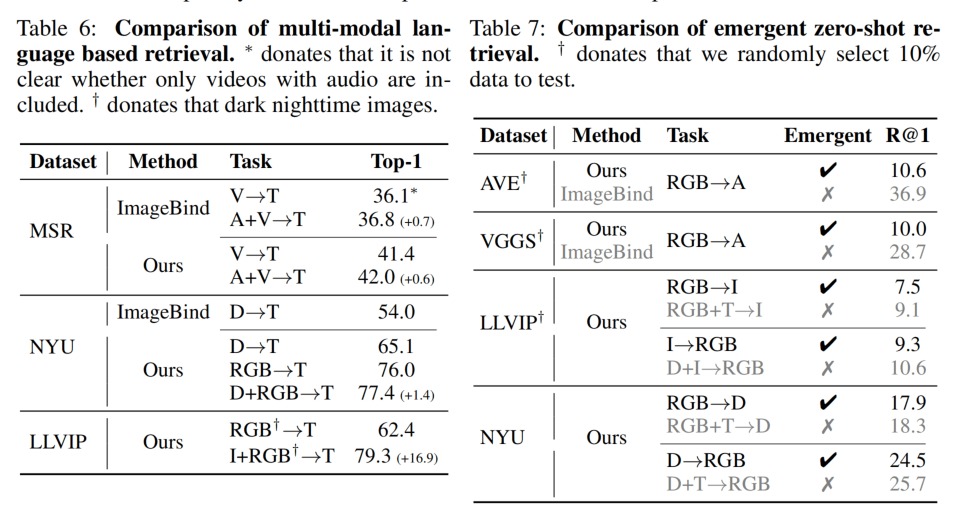
Table6展示了在多模态检索上的性能的提升,Table7则是展示了LanguageBind的Emergent能力。由于ImageBind做了RGB与音频的对比学习,所以性能好一大截。下面两个数据集的比较则是发现Emergent的效果接近不Emergent的效果。
论文在训练超参上进行了消融,这个其实也看不出什么东西,我就直接说结论。它们发现full tuning的效果不如LoRA,且LoRA能减少一般的显存和时间(0.8h训练?没看懂是在哪里训练的?)LoRA的rank设置为了2,比较低。MAE的Mask ratio基本为0.5,符合FLIP论文的假设。
结论
The limits of language are the limits of my world. 语言的界限就是我世界的界限。
Ludwig Wittgenstein 维特根斯坦
著名哲学家维特根斯坦的观念在这篇论文里得到了实践,把所有模态知识统一到语言的语义空间中,在那个语义空间里,就蕴含着智慧。
有14个作者的论文,比ImageBind的7个作者多了一倍,也是有许多科研机构的参与,但是算力消耗貌似也没有那么大,期待scale的结果。文章通过数据集的构建,把所有模态都弄到了语言的语义空间,也为其它下游应用带来了更多的可能性。(这里是语言的语义空间吗?那个Text Encoder貌似是CLIP训练的结果,应该算是CLIP那种视觉-文本的语义空间吧,但是论文标题这么说了也没办法)。
比起模型,这里数据集的构建流程我还是很感兴趣的,希望它们之后能够开源整套流程(目前开源的是模型)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!