论文笔记 Open-Vocabulary Video Anomaly Detection
本文最后更新于:2024年1月2日 中午
论文笔记 Open-Vocabulary Video Anomaly Detection
论文链接:Open-Vocabulary Video Anomaly Detection (arxiv.org)
西北工业大学吴鹏在视频异常检测的又一篇论文,23年12月挂在Arxiv上。这篇文章如图所示实现了一种Open-vocabulary的视频异常检测,即能够检测视频的异常片段,并对片段进行open-vocab的分类。
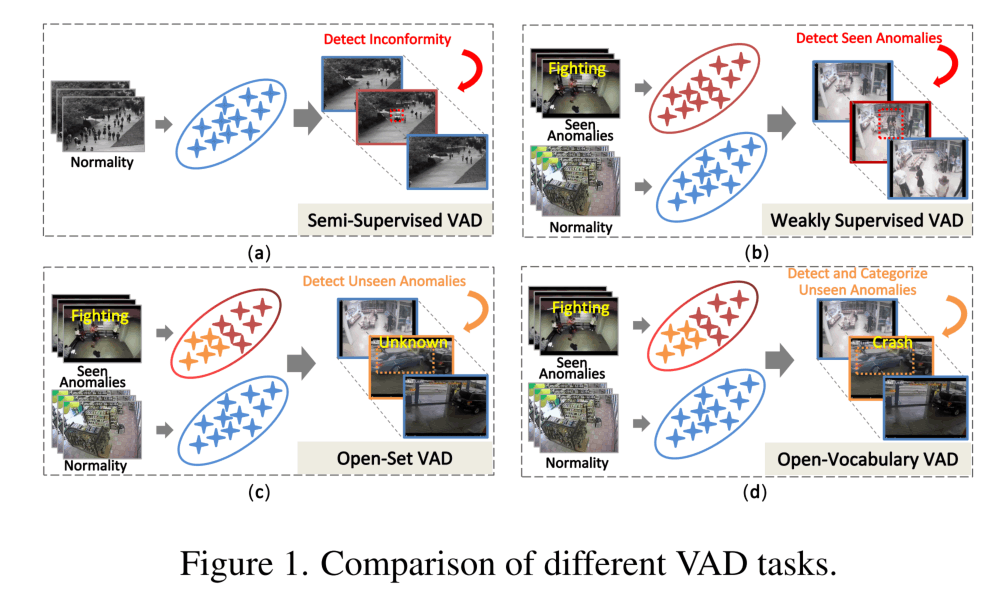
思路如上图所示,(a)是one-class的学习,即训练时只给正常样本,然后预测时表征偏离正常样本过多的就是异常样本;(b)是比较常见的弱监督VAD,在训练只有视频级别的标签,有正常和异常视频,预测的时候需要帧级别的标签;©是更新一点的open-set的问题,关注“如何预测的时候检测到训练类别以外的异常事件”的问题;(d)这篇文章更进一步,定义了OVVAD任务,不仅在预测阶段要检测出未见过的新类别,还要对类别进行OV的分类。
方法
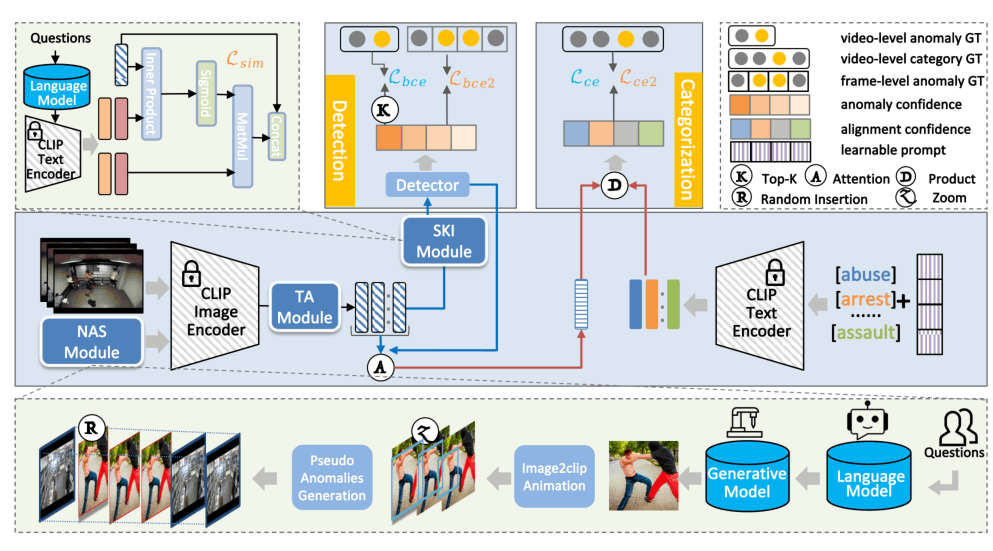
模型整体架构图如上所示,画的有点迷惑人,实际上蓝色背景是模型的主要框架,绿色背景是SKI Module和NAS Module放大的结构。本质上这个方法是CLIP提特征+时序编码+语义注入增强进行二元分类,然后异常的embedding与预先定义的类别的CLIP文本embedding计算余弦相似度,取最近的作为标签,从而实现Open-vocabulary(和目标检测的OV如出一辙)。
Temporal Adapter(TA)
非常简单的一个模块,使用尽量少的参数来使CLIP的特征具有时序的信息:
H是根据相邻位置得到的邻接矩阵,相距越远值越小(负数),然后进行一个softmax的加权求和,最后LayerNorm,参数仅在LN里头。
Semantic Knowledge Injection(SKI)
这个方法也很简单,首先构建一些包含异常的短语(杀人放火等),然后提取CLIP文本特征,然后
就是根据异常文本对于特征的相似度来进行一个加权求和,得到视觉加权的文本特征,并于原来的视觉特征拼接送进二元分类器。
Novel Anomaly Synthesis(NAS)
更加简单的一个模块了,通过LLM得到关于异常场景的prompt,然后送进Diffusion模型生成异常图像,再通过Image2clip这个能让图片变成动态的模型生成异常视频,然后这个异常视频插入进正常视频作为新生成的数据。
这个模块设计真的是槽点满满,首先论文里给出的生成效果就非常的差劲,人脸都糊了,手也是一团浆糊,别直接用LLM生成prompt了,手工设计一点吧……
其次,先生成图,再动起来也很奇怪,和正常的异常数据完全不一样。
最后,居然是把生成的这个直接插入进别的正常视频吗??怎么感觉无论插入什么都应该算作是异常啊……
损失函数
异常检测用的比较常规,把top-k的帧特征作为表征,然后计算和视频级别标签的BCE损失。分类损失使用简单的概率加权得到全局特征,然后计算交叉熵。额外地,这里使用了CoOp来微调CLIP的文本编码器。对于SKI,额外添加一个损失项,写的不是很清楚,大概就是也通过top-k的策略,令文本与视频对齐。
上面是训练阶段,使用数据集的数据,接下来再进行一个微调阶段,使用NAS的数据,由于NAS有帧级别标签,所以可以使用帧级别的BCE损失函数。
生成数据用来微调???不应该用数据集数据微调吗?或许是为了泛化性?
实验
他们汇报一张3090就能完成实验,具体没什么看的,但是感觉没有选最SOTA的模型比较,比如UCF上SOTA已经是87.24,这篇文章汇报是86.4,其它两个数据集就更离谱了,XD的SOTA是85.67,本文只有66.53,UBnormal的SOTA是79.2,本文只有62.94?
这篇文章还在三个数据集上都做了模块级别的消融实验,都很理想,每个模块都能稳定加一点点……
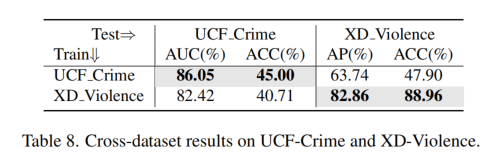
Tab8汇报了一个跨数据集的验证,为啥这里汇报XD上能有82.86了????SOTA的表写自己都只有66.53啊?
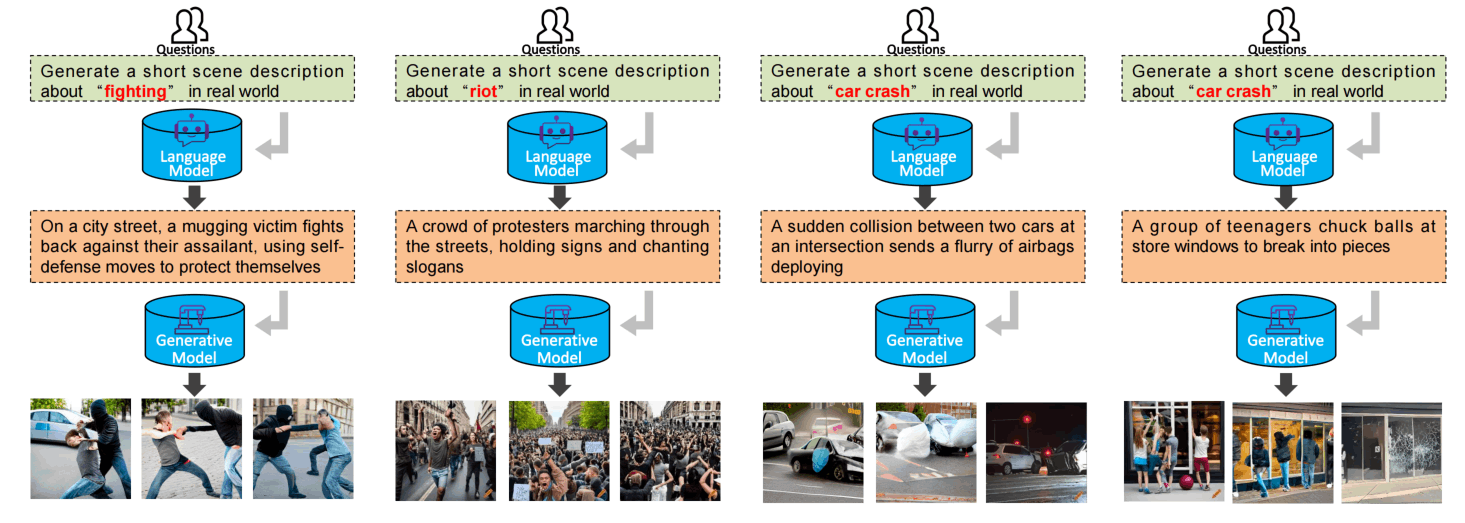
上面的Fig7是生成数据的示例,ummm,质量很差,扩散模型好像不是这么写prompt的吧哈哈哈。
结论
完全的占坑之作,论文撰写混乱,方法也不够新颖,留有很多未解之谜,可能是赶工出来的,感觉这个版本发表不出来。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!