论文笔记 ImageBind One Embedding Space To Bind Them All
本文最后更新于:2023年12月5日 上午
论文笔记 ImageBind: One Embedding Space To Bind Them All
论文链接:CVPR 2023 Open Access Repository (thecvf.com)
代码链接:facebookresearch/ImageBind: ImageBind One Embedding Space to Bind Them All (github.com)
官方网站:ImageBind by Meta AI (metademolab.com)
Meta的FAIR出的一篇CVPR2023 Highlight,在当时一出就受到广泛的关注,现在在大半年之后我才开始认真看一下hhhh。基本来说,这篇论文提出了一个基于对比学习的、CLIP架构的多模态模型,统一了Image、Video、Text、Audio、Depth、Thermal、IMU七种模态,并涌现了Zero-shot的能力。
方法

上图是ImageBind的网络图,乍一看都不像是个网络架构的图,但其精华都在其中。
首先左边绝大一部分都是在说使用的模态数据源,包括图像-文本对(CLIP的训练数据)、深度传感数据(不清楚,当时应该都有对应的图像)、热力数据(RGB图像+热力图)、视频(图像序列+音频)、第一人称视频(视频+IMU运动传感数据)。可以发现,目前涉及到的其他模态,都能够通过视觉的图像或者图像序列连接在一起,所以这也就带来了本篇文章的标题,使用Image来bing所有模态。
再捋一遍,为什么是ImageBind?因为数据!数据都能通过Image,bind在一起。
由于前人CLIP将图像和语言的语义捆绑在一起的工作做的非常好,所以这篇文章也是采取了基本相同的手法,每种模态使用基于ViT的编码器得到N维的一个特征向量,然后使用InfoNCE损失函数进行优化。在训练过程中,图像和文本编码器由于已经学的很好了,不会更新参数,其余编码器使用CLIP或者OpenCLIP来初始化。
| 模态 | 编码器 | 适配方法 |
|---|---|---|
| 图像 | OpenCLIP ViT-H 630M | - |
| 视频 | 同上 | I3D方法拓展ViT,切成2s |
| 文本 | OpenCLIP ViT-H 302M | - |
| 音频 | ViT-B | 2s的梅尔频谱 |
| 热力图 | ViT-S | 单通道图像 |
| 深度图 | ViT-S | 单通道图像 |
ImageBind对不同数据集进行训练,得到训练好的各个模态的编码器之后,就可以做Zero-shot和Emergent Zero-shot的实验,后者是将原来没有数据相连的模态进行实验。比如使用了“图像-文本”和“视频-音频”的数据分别训练,最后却可以进行“音频-文本”的Zero-shot实验。
实验

上图图像和视频就是OpenCLIP的结果,蓝色背景的其他模态就是这篇文章的结果。最下一行就是包括监督学习、集成学习等等在内的最高分,也就是目前的上限。第三行的热力图是直接当作灰度图做CLIP的,音频是一个不算Zero-shot的用了文本的结果。因为实在比的太少了,所以没什么可比性,但是至少比随机高了很多,距离监督学习倒还是有差距。
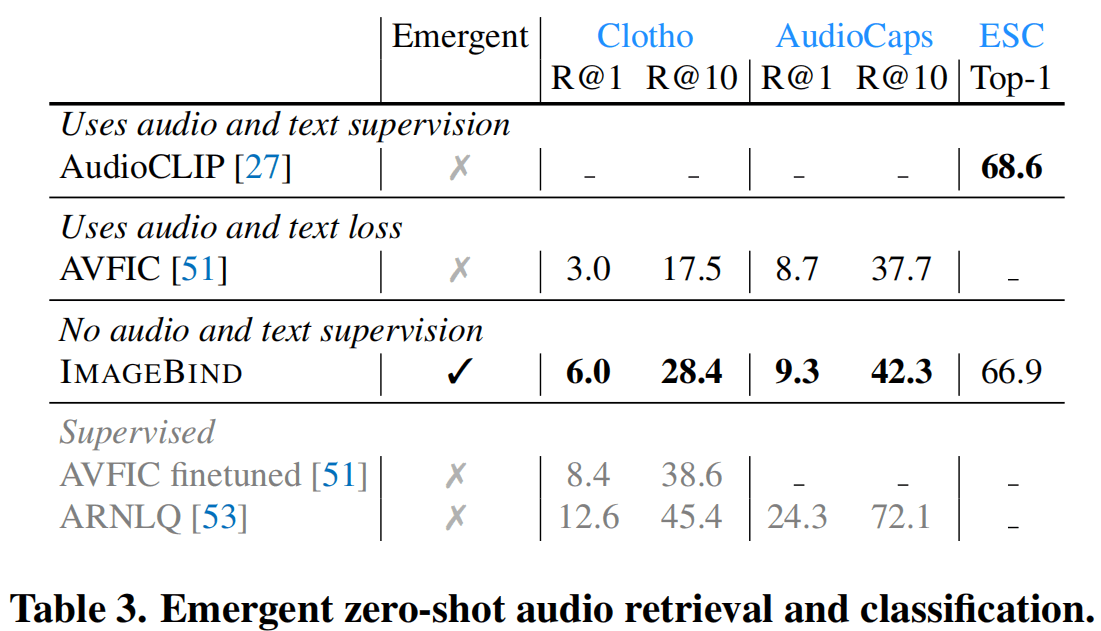
这张图的三个数据集是有Audio-Text的标注的,但是ImageBind做的只是视觉-音频和视觉-文本的学习,然后Emergent Zero-shot到音频-文本上,发现表现还不错,虽然也是离监督学习和不Emergent的AudioCLIP有差距。
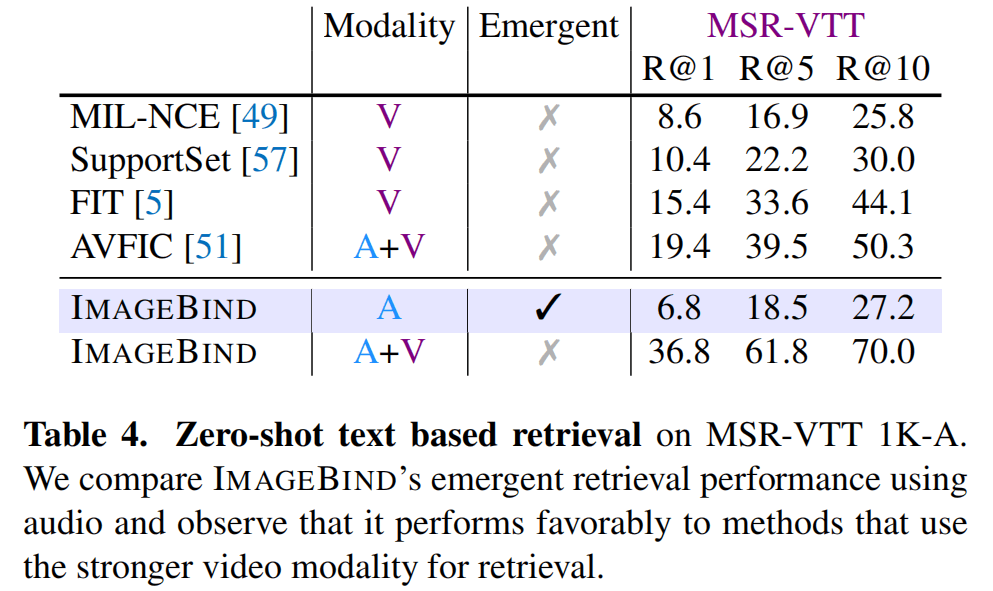
在视频检索上,MSR-VTT只用音频的效果不尽如人意,但是居然还比MIL-NCE好,在加上视觉模态后,更是在Zero-shot上超出其它一大截。

消融实验证明,这个方法是可以继续Scale的。
其它实验去看论文吧~这里不一一分析了。
应用

论文放在摘要前面的第一张图,阐述了ImageBind的可能性。
首先是做任意模态之间的检索,用音频检索文字、用音频检索深度图等等。
其次是做一些可解释性的算术,这个在ZeroCap模型里也探索过(也可以看我的博客[基于梯度下降算法的Zero-shot Captioning方法 - Kamino’s Blog](https://blog.kamino.link/2023/09/08/Grad Guided ZeroShot Captioning/)),下面还有一些例子:

比如水果+鸟叫声=树上的水果,家里墙上的挂钟+教堂钟声=教堂的钟的图,路牌+雷声=打雷时的路牌。
最后,还有结合DALLE-2的生成模型,可以用其他模态的特征来生成图像,比如图中所示的音频生成图像。
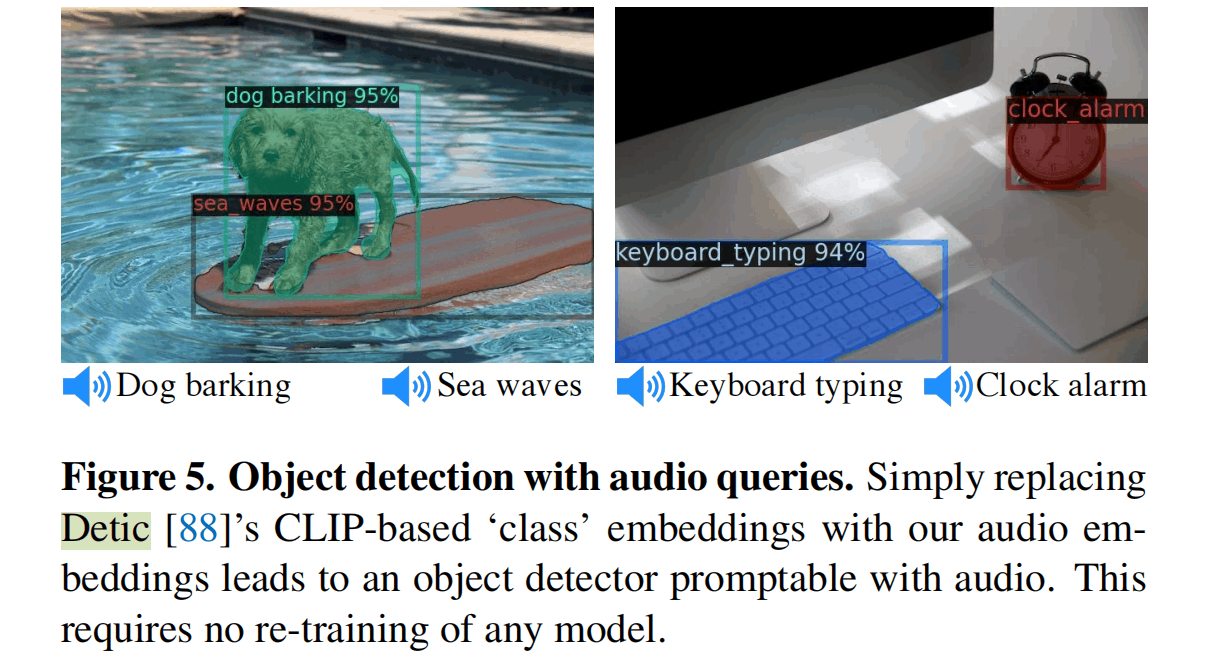
论文里还放了一个使用音频进行目标检测的例子,Detic是Meta在ECCV2022提出的一个Open-vocabulary的目标检测模型(我也写过博客[博客 - Kamino’s Blog](https://blog.kamino.link/2022/11/16/Detic and Object Detection Review/)),可以将任意文本的特征作为候选类,来进行目标检测。这里将文本特征替换为音频特征,就可以实现用音频来进行目标检测。
结论
ImageBind给多模态的融合带来了一个崭新的Backbone,由于缺乏比较,其性能不一定好,但是至少是一个开始。ImageBind利用了多种数据源的特点,使用Image来作为中间表示,联合多种数据,定义了Emergent Zero-shot的范式。总的来说,ImageBind是一个很好的工作,是一个崭新的开始。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!