论文笔记 Video Event Restoration Based on Keyframes for Video Anomaly Detection
本文最后更新于:2023年11月21日 下午
论文笔记 Video Event Restoration Based on Keyframes for Video Anomaly Detection
论文链接:CVPR 2023 Open Access Repository (thecvf.com)
西北工业大学吴鹏组和西电的一篇CVPR2023论文,做无监督的视频异常检测。文章提出了一种Video Event Restoration的训练方式,并提出了以Swin+U-Net为主的USTN-DSC网络,在Ped2、Avenue、ShanghaiTech上获得优秀的成绩。
研究故事~
无监督VAD基本基于reconstruction或者prediction。
前者通常使用一个AutoEncoder来学习视频数据库,预测时那些重构误差大的帧就认为是异常帧。
后者则是使用一个网络来预测未来的帧,但预测的误差大时,就被认为是异常。
然而,基于重构的容易学习到低级表征而不是高级语义,基于预测的则会由于相邻帧的差距即使是异常事件也不大而效果不好。
所以这篇文章探索了Video Event Restoration的范式,利用了视频编码的原理。首先,视频编码一般分为I、P、B帧(Intra, Predictive, Bi-directional interpolated prediction),其中I帧是关键帧,包含了一帧完整的信息;而P帧包含与前一帧画面差别的数据,这篇文章认为P帧蕴含运动误差信息;B帧也类似,包含了两个方向的运动误差信息。
所以,作者认为通过I帧来预测P、B帧的信息是可行的,从而提出了video event restoration的方法来进行异常检测。要预测出缺失的帧是一个困难的任务,所以偏离假设的就被认为是异常帧。

锐评:讲得那么高大上,不就是mask掉一些中间帧然后预测他们吗hhhhh。这个在预训练的模型中应该也有尝试过了。而且,这个和视频编解码的关系貌似也不是很大,因为预测出的也是RGB的帧,而不是具体的运动信息。但是CVPR不愧是CVPR,故事讲得还是挺好的。
方法
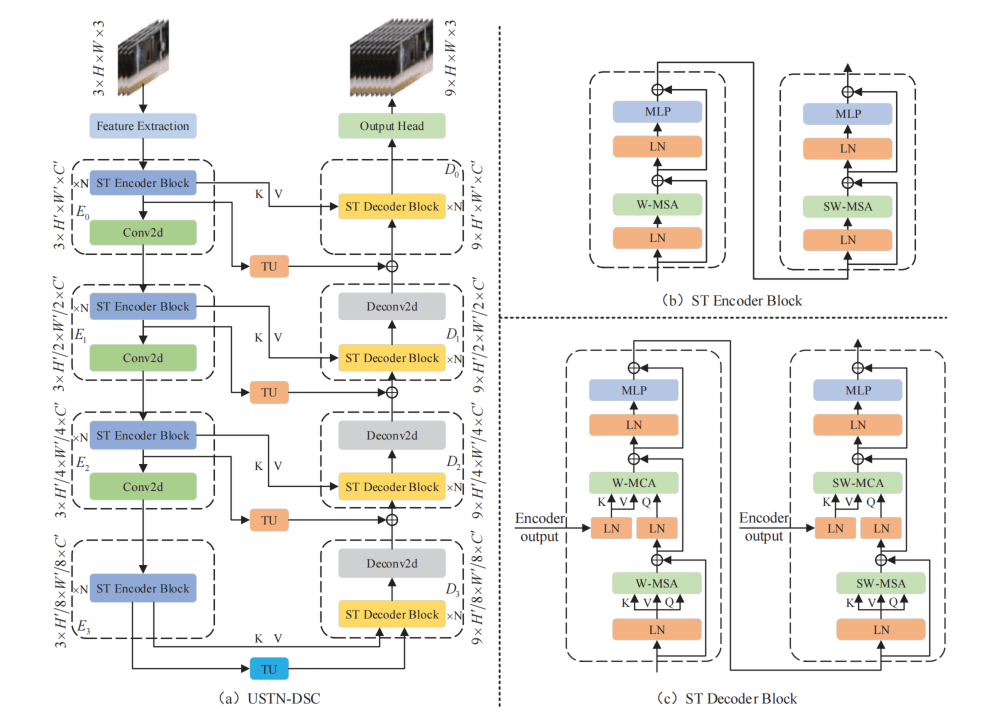
提出的模型叫做USTN-DSC,是基于Swin-Transofrmer和U-Net的一个网络,作者在文中写了很多,这里就简单介绍一下。
首先,编码器由Swin的Block和卷积组成,Swin就是由window和shift-window的ViT,每一个stage通过Conv2d进行一个下采样,分辨率变为1/2,要注意的是一开始特征提取的时候会首先降一次分辨率。解码器基本是对称的架构,但是由于要接受编码器传过来的skip-connection,所以swin block加上了CrossAttention,并且额外也做了与传统一样的相加的skip-conn,文章把这个创新点叫做Dual Skip-Connection。并且,如Figure1所示,训练的输入是3帧,输出则是每两帧之间添加了3帧,最终是9帧的输出,所以要通过TU(temporal upsampling)来上采样时间维。同样,下采样的卷积也变成了上采样的反卷积,如下图所示。
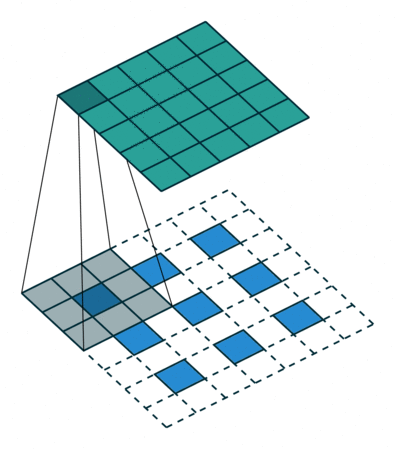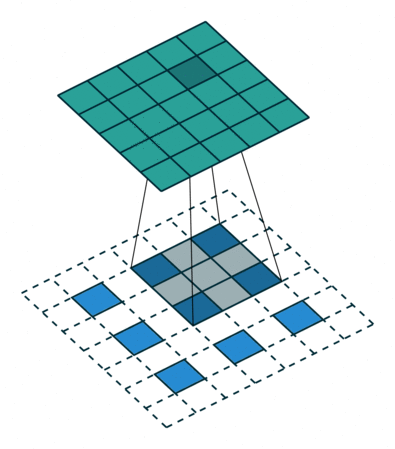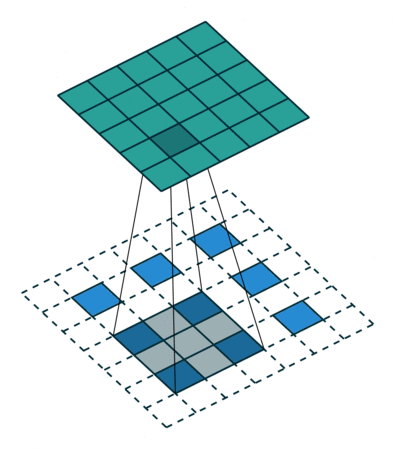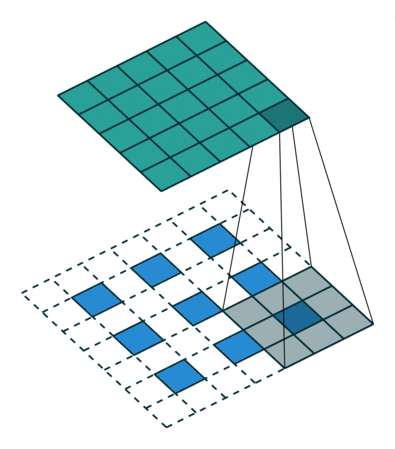
TU的涉及是3D-DeConv,黄色的TU共享权重,蓝色的bottleneck单独有个权重。
训练损失函数
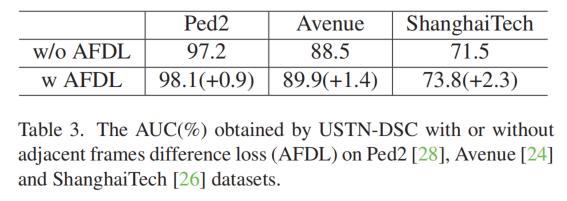
损失包含charbonnier损失( Fast and accurate image super-resolution with deep laplacian pyramid networks)和AFD损失(没给引用,没解释什么是AFD)。
Charbonnier如下,衡量RGB差值加一个极小值
AFD如下,衡量预测和真实的“帧的相邻差”的相似度,作者认为与运动信息相关
推理流程
测试时,输入3帧,输出9帧,然后找到9帧中,预测和实际的差的平方最大的那一帧,然后计算PSNR:
分子是预测的这一帧的最大的像素,分母则是这一帧的MSE,然后用缩放一下。然后这9帧的异常分数就是PSNR值。然后,在视频预测完之后貌似是会做一个min-max的归一化,但是没有写清楚。
实验
在Ped2、Avenue、ShanghaiTech三个小数据集上做的,虽然小,但是也没什么办法。模型上,每个stage包含6个block,那么编码和解码总共6个stage就是36个block,基础维度是96。对比swin的话,Swin-Tiny是12层、Small/Base/Large都是24层,维度则Tiny和Small是96。模型整体复杂度相当于更深但是更窄的Base。
下面是与SOTA的比较,新的范式比reconstruction-based和prediction-based的效果都好,且没用光流信息。

Tab2是对DSC的消融,什么都不做的话是第一行,假如做了cross-attn的是第二行,假如做了传统那种的是第三行,都做是第四行。这个都比较理想。Tab4是对层数的消融,发现其实N=2的话效果也算还可以,N=4在Ped2效果最好已经是SOTA了,N=6反正就往上叠到了最好。
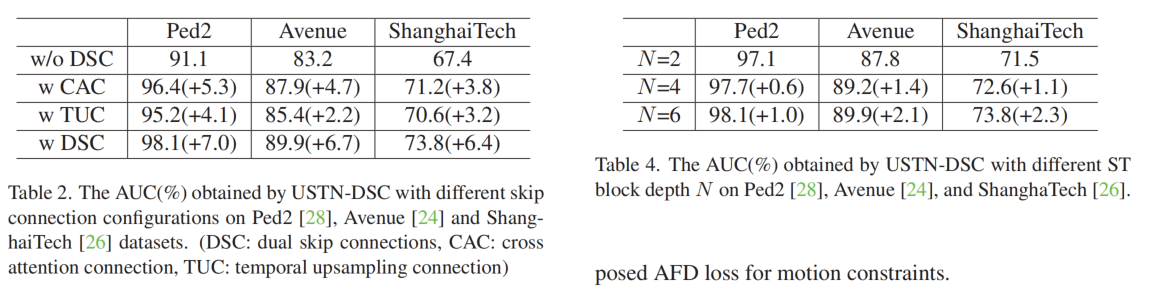
AFD这个损失的消融,比较理想。
supplementary material中补充了一些消融:
对T的消融,发现9最好,但是有一点点疑问,就是他们用一张3080训练的,batchsize=4,再往上的话,会不会显存不够了……然后导致性能下降?同时材料里也补充说效率是188FPS,但是没说batchsize。

针对假设的可视化,对于结果的重构方面,(b)和(c)代表以前的两类方法,发现对异常事件的重构也会很不错,但是(d)本文的不会。

第二行是重构,第三行是误差图,这个可视化做的挺不错。

总结
首先可惜代码没开源,而且看上去代码也不会开源了。其次模型架构的消融实验貌似不是很全面,居然没被审稿人问到?总之是研究故事讲得真不错。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!