论文笔记 UnLoc A Unified Framework for Video Localization Tasks
本文最后更新于:2023年11月6日 晚上
论文笔记 UnLoc: A Unified Framework for Video Localization Tasks
论文链接:UnLoc: A Unified Framework for Video Localization Tasks (arxiv.org)
代码链接:google-research/scenic 一个JAX库,非PyTorch,包含许多工作,但是目前还没有找到这篇论文的代码

Google的一篇ICCV 2023论文,除开共同一作的二作是VGG组的Arsha Nagrani。这篇论文提出了一个通用的单阶段的方法UnLoc,来做多种视频定位任务,包括片段检索、动作定位、动作分割,并且利用了CLIP的视觉和文本侧。
方法
三个任务
- Video Temporal Action Localization(TAL):给定某个动作标签,在视频中定位这个动作发生的时间段。
- Video Moment Retrieval(MR):给定任意自然语言,在视频中定位这句话描述的时间段。
- Video Action Segmantation(AS):为视频的每一帧分配一个某个动作标签或背景。
MR是TAL的open-vocab版本,AS则是密集预测的版本。
网络架构
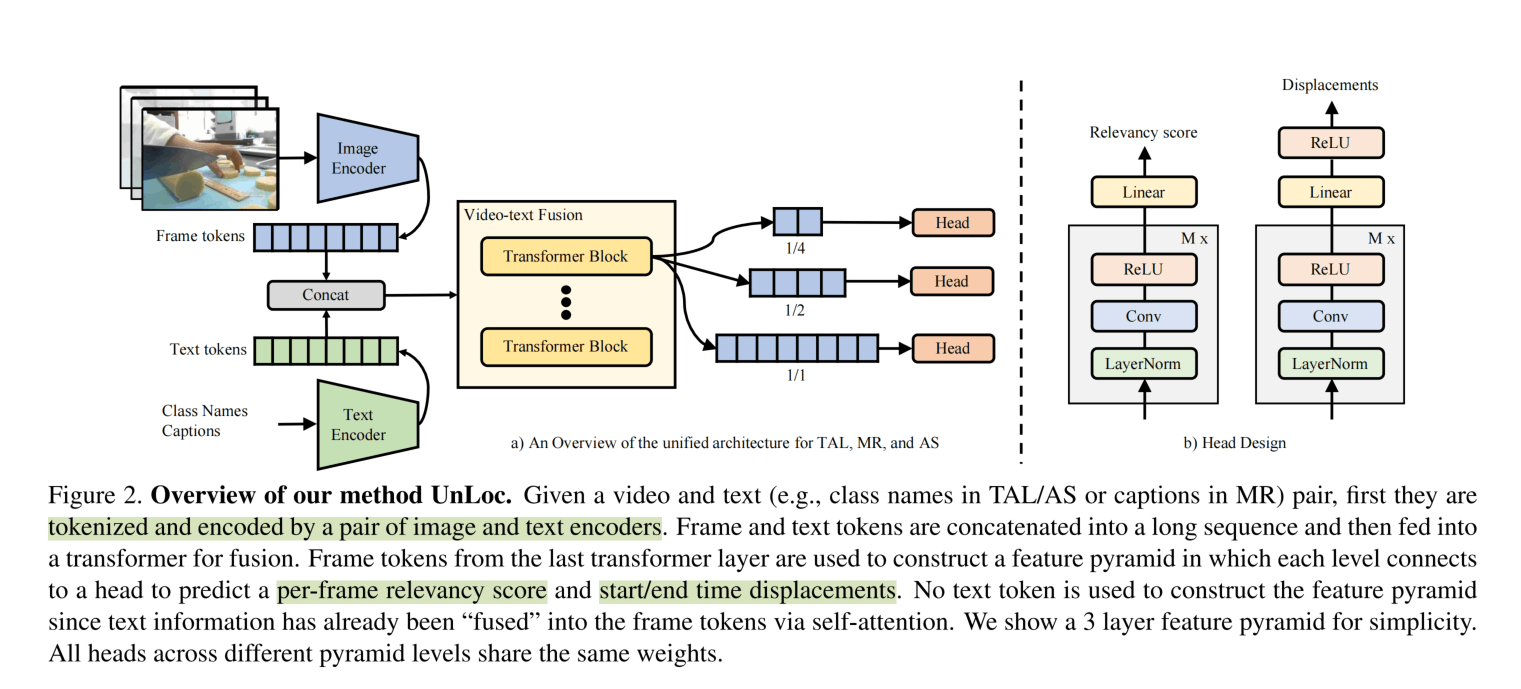
上图是UnLoc的整体架构,视频的输入帧使用CLIP得到Frame级别的Token,同时文本(或者被prompt的标签)使用CLIP也得到Token,两者拼接在一起,送入Transformer Encoder进行模态融合。融合后特征通过卷积形成特征金字塔,然后送入Head,得到每一个Token与文本的相关性分数以及位置偏移量。下面具体介绍其中的细节。
其实从视频/文本到融合模块结束都没什么好讲的,都是常规操作。在融合模块出来,这里使用了不同stride的卷积来得到不同尺度的特征,并且卷积操作只针对Frame Tokens。这一步可能就会得到个Token,其中是帧数量。
之后,每一个Token送入Head,Head则是比较轻量的卷积模块,其中一个Head比较常规,用Sigmoid激活得到Relevancy score,表示当前token与文本的相似度,相似度越高,就说明当前帧属于需要的某个动作。
另一个Head则是参照ECCV 2022的ActionFormer,假如某个token被认为属于文本描述的行为,那么随之而来还会预测两个由ReLU激活的值。而该行为的区间定义为。
也就是说,假如一个视频10s,以1fps编码,在5~8秒进行了投篮的动作,那么第6秒/帧的视频token应该有较高的relevancy score,并预测出,第8秒的token则是,第1秒的token则不预测。
Loss也包含了分类和回归两部分:
由于视频中positive的部分是远远少于negative的部分,所以分类使用了Focal Loss来应对imbalance。
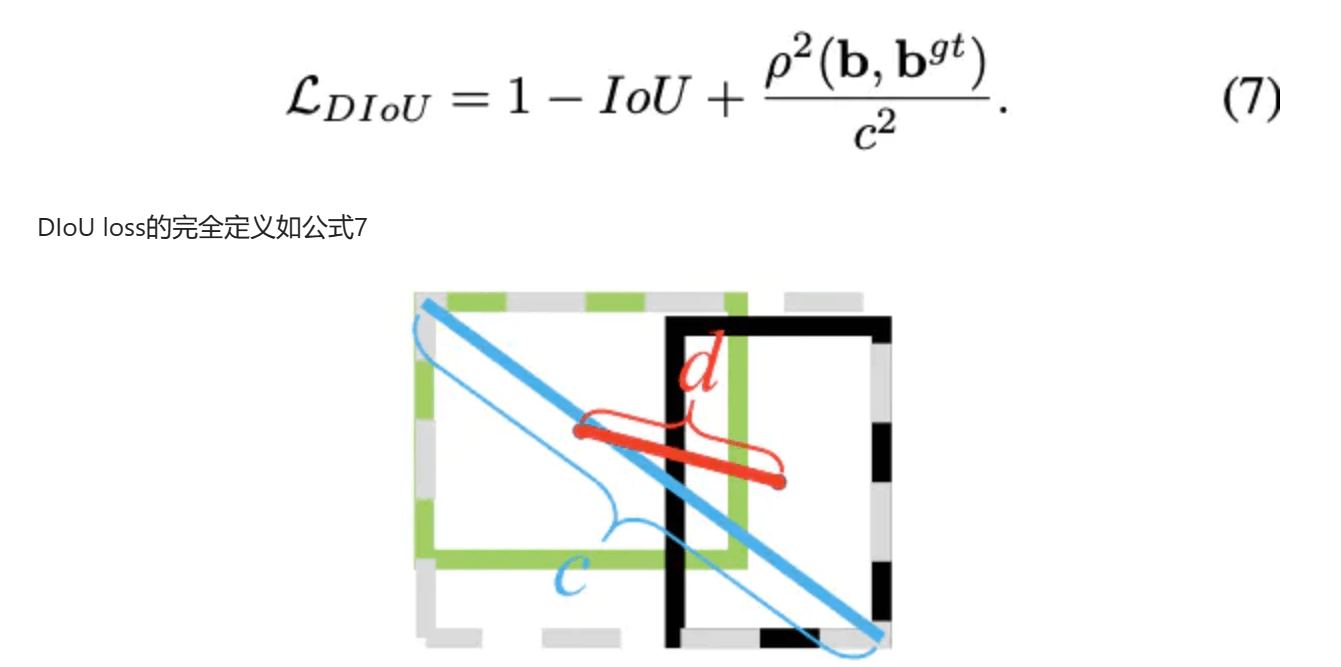
则使用回归损失,尝试了L1、IoU、DIoU、L1+IoU。其在目标检测计算如下。实际上就是让IoU越大,并让一个距离比越小。距离比是两个区间中心点的距离比上并集的两侧距离(但是后面发现L1好……)。
不同尺度进行回归时会跟随ActionFormer,置顶不同的Regression Range,这个概念两篇论文都没怎么详细说。对于最细粒度的长度为N的尺度,使用是regression range,对于的使用……,根据我的理解,这应该是限制不同尺度关注不同长度的事件,最细粒度的尺度的range比较小,关注短时的,而粗粒度尺度的range比较大,关注长时的。(这一段存疑)
预测的时候使用SoftNMS应对不同尺度带来的可能重叠的区间。
实验
搭建了UnLoc-B和UnLoc-L,融合模块都是6层Transformer,只是维度从512/2048变到了768/3072。特征金字塔搭建了4层,而不是图示的3层。
先使用K700或者K400进行了预训练,所有视频224分辨率,TAL和MR使用128帧,AS则2fps上限512帧。
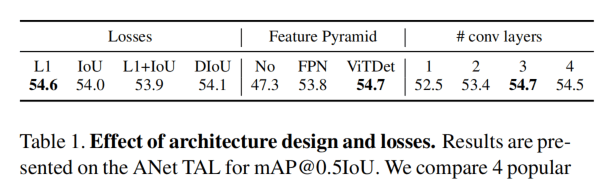
没有什么特殊的说明,就是L1效果好、ViTDet那种特征金字塔效果好、Head用3层卷积好。实验只在一个数据集(ActivityNet)上的一个任务(时序动作定位)做了。
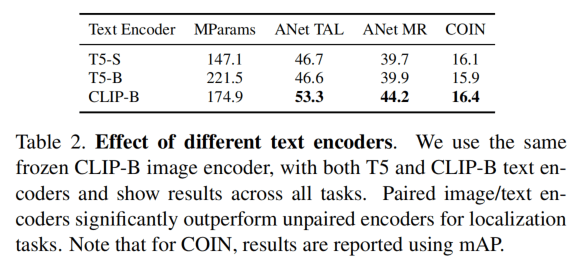
使用不对称的Encoder会影响结果,这个也是意料之中的。
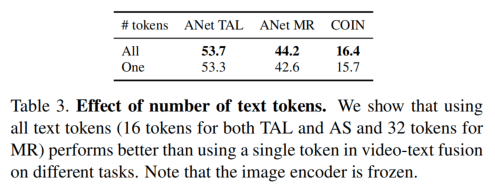
文本Token也是全部cat更好,而不是只是用CLS。
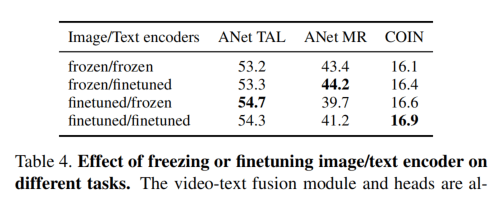
对图像进行微调在TAL和COIN上有提升,在MR上下降。对文本编码器进行微调则在MR和COIN上提升,在TAL上有升有降。这个其实的不出什么结论。而另一篇论文LiT([论文笔记 LiT Zero-Shot Transfer with Locked-image text Tuning - Kamino’s Blog](https://blog.kamino.link/2023/06/24/LiT Zero-Shot Transfer with Locked-image text Tuning论文笔记/))认为冻结图像编码器,只调文本更好。
与SOTA的比较没什么好看的,就不放在这里了。
结论
这篇论文让我觉得比较新奇的点其实不在于UnLoc,而是它借鉴较多的ActionFormer,包括多尺度的使用和结果的预测方式。这篇论文的核心创新就是把三个任务统一了,有了一个统一的框架,并且效果刷到了最好,方法也比较简洁。
有了统一框架,接下来当然就是大规模训练了,这也是作者在结尾说的Future work。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!