论文笔记 VidChapters-7M Video Chapters at Scale Video Captioning
本文最后更新于:2023年11月6日 中午
论文笔记 VidChapters-7M Video Chapters at Scale Video Captioning
论文链接:VidChapters-7M: Video Chapters at Scale (arxiv.org)
项目主页:VidChapters-7M: Video Chapters at Scale (antoyang.github.io)
代码链接:antoyang/VidChapters: NeurIPS 2023 D&BVidChapters-7M: Video Chapters at Scale (github.com)

VGG组的一篇NeurIPS 2023的Dataset&Benchmark赛道的论文,二作有过多个相关领域的重要工作。文章提出了一个新的大规模数据集VidChapters-7M,包含82万个视频和7M个视频章节,支持Video chapter generation、video chapter generation with ground-truth boundaries、video chapter grounding三个任务,其中第一个任务是最终的目标,即将长视频自动划分为多个章节,并给出章节名。
建立动机
人们观看视频的时候通过手动导航难以快速找到感兴趣的内容,通过连续、不重复、完全划分视频的Chapters就可以帮助人们找到。
目前的数据集大多关注于短视频,比如WebVid和VideoCC(10s),长视频的数据集则基本是通过ASR来得到的低质量标注,比如HowTo100M和YT-Temporal-1B。Moment retrieval与Dense video captioning比较接近,但是不符合Chapter的需求,并且数量较少。
数据集构建
收集
数据的收集分为两步,第一从YouTube收集一个庞大的视频数据候选库,第二从候选库中过滤出有用户章节标注的视频。
比如下图中右侧,但是这篇文章是下载非自动生成的章节。
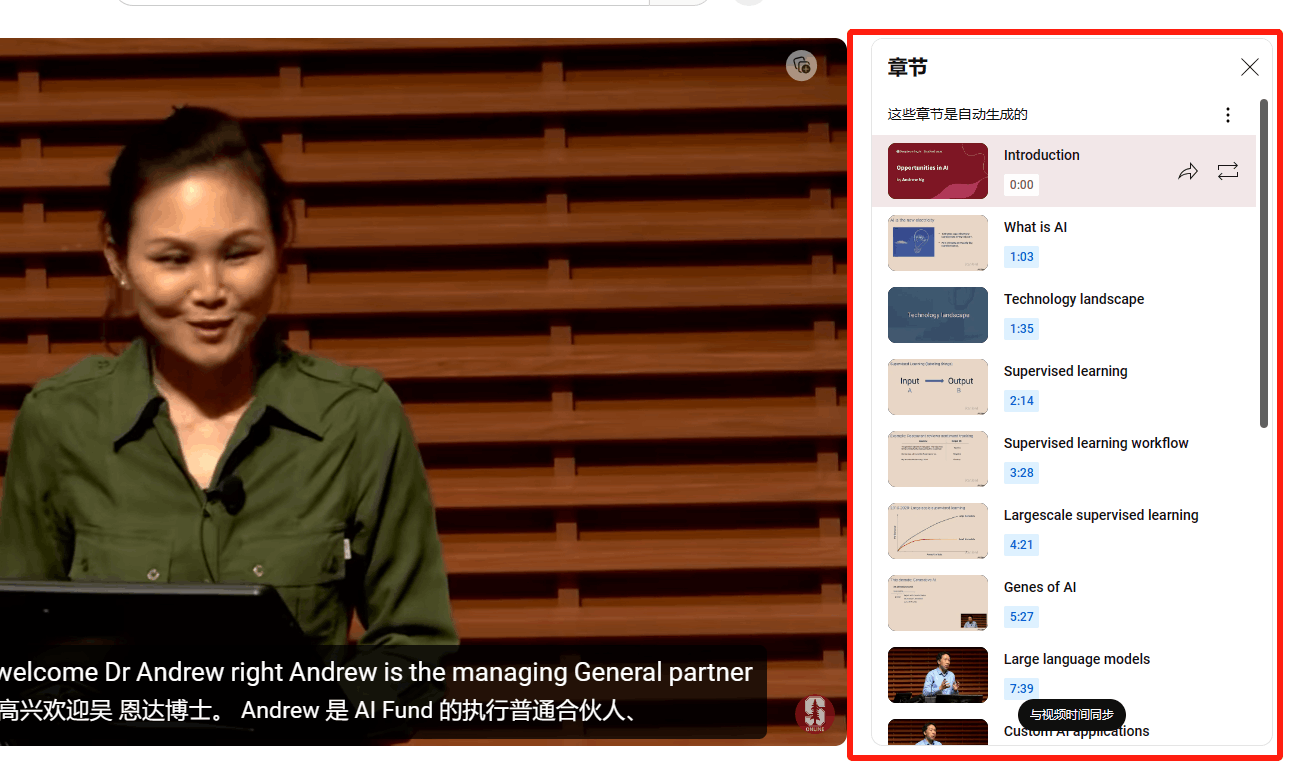
候选库直接使用YT-Temporal-180M数据集的候选库,包含92M个视频,然后其中用户标注的视频有817K个。
预处理
使用WhisperX+Whisper-Large-V2+faster-whisper来进行ASR与精确时序定位,得到每一句话的开始和结尾。
视觉特征使用老朋友CLIP ViT-L/14提取。
数据分析
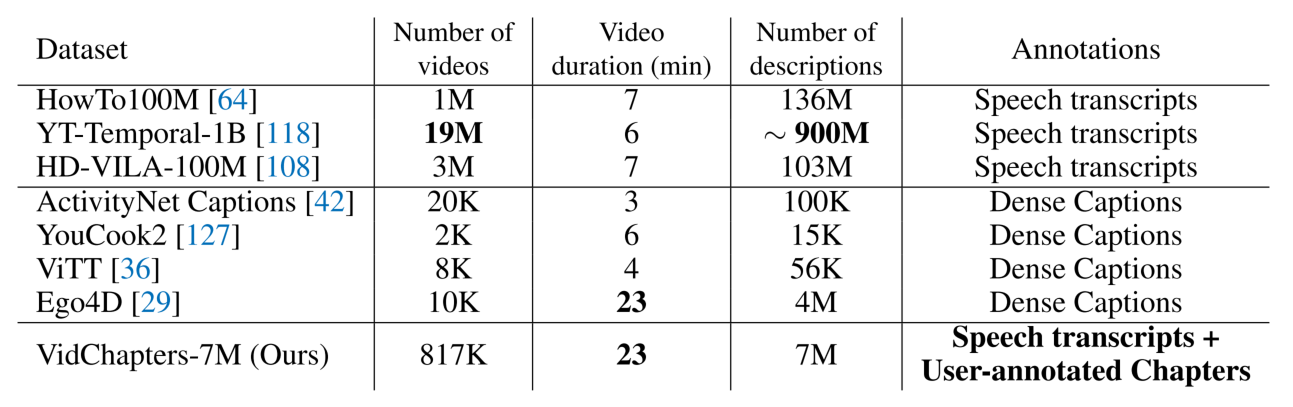
与其它数据集比较,这个数据集视频不算多,但是视频时长都比较长,平均23分钟。主要是数据集的标注比较特殊,是User-annotated Chapters。
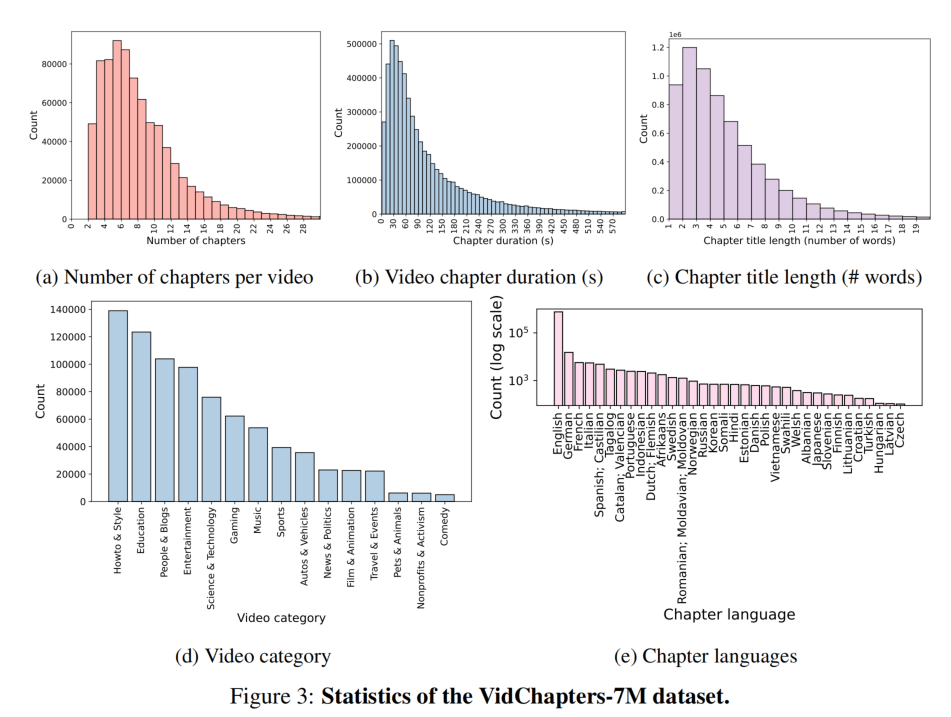
下面是一些分布。视频章节数量基本聚集于14章内,时长2分钟内的最多,章节标题字数不多,基本都在8个单词内。视频种类前三是教程类、教育类、Vlog类,这也是印象中会去标记章节的视频,标记语言也是以英语为主,中文没有入榜,注意(e)图是指数坐标轴。
此外,对于ASR的提取结果,97.3%的视频识别出了语音,比例还是很高的。对于AI的一些道德问题,作者报告了在chapter中大概是的女性:男性:中性词汇,在ASR中大概是。作者还使用了LAION-5B训练出的一个小分类器来检测NSFW信息,其中有0.7%的色色视频。作者还使用了文本上的有毒内容检测,在chapter有0.04%、在ASR有0.17%。这些比例不高,作者只是标记了它们,没有删掉。
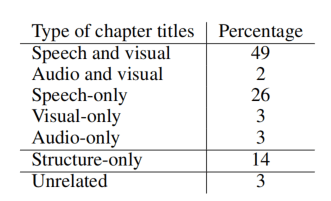
作者还手动分析了一些标题的质量,100个里面有14个是类似“步骤1、步骤2”这种标题,有3个是完全不相关的,剩下的83个基本都与视频内容(视频或者音频)有关。也就是说,基本上83%的数据才是有价值的,而只有50%的数据可以仅从视觉内容中得到,这也预示着利用Speech或Audio的重要性。
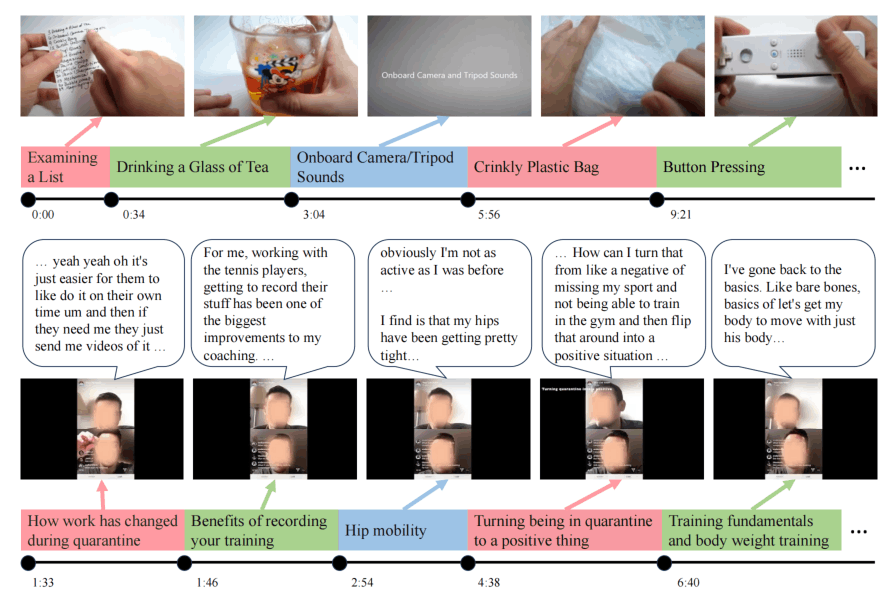
上面是一些实际的例子,有一些需要对视觉进行深刻的理解,有一些对Speech更重视。
实验
文章没有给出他们自己的一个模型作为Baseline,而是尝试了多个方法的组合。指标使用常规的B、C、M、R,定位使用R/P+IoU,综合使用SODA_c。
Recall:预测的章节中匹配上的数量 / 所有章节的数量
Precision:预测的章节中匹配上的数量 / 所有预测的数量
使用8张A100 80G就能训练起来~
Video Chapter Generation

使用的方法如下:
- Text tiling:纯自然语言方法,使用NLTK包,将ASR的文本分成几块,目标是找到文本的话题之间的分界点。(这个好像最近B站的“AI视频总结”就是这样)。分好ASR之后再利用每句话的时间戳来划分章节。
+LLaMA就是再用一个LLM来总结章节内的ASR。+Random就是随机选一句。 - Shot detect:视觉上的镜头切割,使用ffmpeg通过计算帧间相似度分割,
+BLIP-2就是预测镜头中间帧的caption。 - Vid2Seq:CVPR2023的方法,见我另一篇博客。这里没用原论文的YT预训练,而是用了HTM预训练的权重,其可以使用ASR+视频进行Dense Video Captioning的训练。
- PDVC:经常被用来比较的开源Dense VC方法,使用DETR-style的纯视觉方法。
分析如下:
对于Zero-shot的方法,生成文本质量低的可怜,基本用不了,C值最高也0.8。定位性能也不佳,在IoU一半的情况下,手工方法的也只能匹配上四分之一的章节,而基于深度学习的Vid2Seq更是低。
对于微调的方法。生成质量有了较大的提高,PDVC的C值可以达到35.8,属于是“有点像”的水准。而Vid2Seq的结果很有趣,发现对于视频来说,Speech模态更重要,仅用Speech就达到50.7的C值,仅用Visual只有20。在加上HTM预训练和双模态之后,C值达到了55.7,结果属于是还挺不错了。定位性能也有较大的提升,PDVC的P值领先,也就是说它预测的章节不多,且预测就比较准,在IoU0.5或5s的情况下能对一半。而Vid2Seq在R值上更领先,也许是预测的章节更多更碎,而不同模态的差距就没有那么大了。
Video Chapter Generation with Ground-truth Boundaries

对于这个更简单的任务,同样Zero-shot性能不佳,而微调后的Vid2Seq的C值居然超过了100,已经是效果极佳了。但是仅使用视觉效果还是很差。
Video Chapter Grounding

这个更简单的任务多使用了BERT、CLIP和Moment-DETR作为Baseline,分别代表纯用语言的方法、多模态的方法和基于Moment retrieval的方法。
Zero-shot的情况下,效果不是很好,相对CLIP效果最好。而微调之后,Moment-DETR的效果有很大提升,因为是专门做这个的。
此外,作者还考虑使用VidChapters作为预训练数据集,促进对于YouCook2和ViTT数据集进行Dense video captioning下游任务,这里不放表格了,但是效果挺好。这个Baseline就纯纯利用Vid2Seq这个模型,反正也是二作做的,拿过来跑估计就很方便。
定性分析
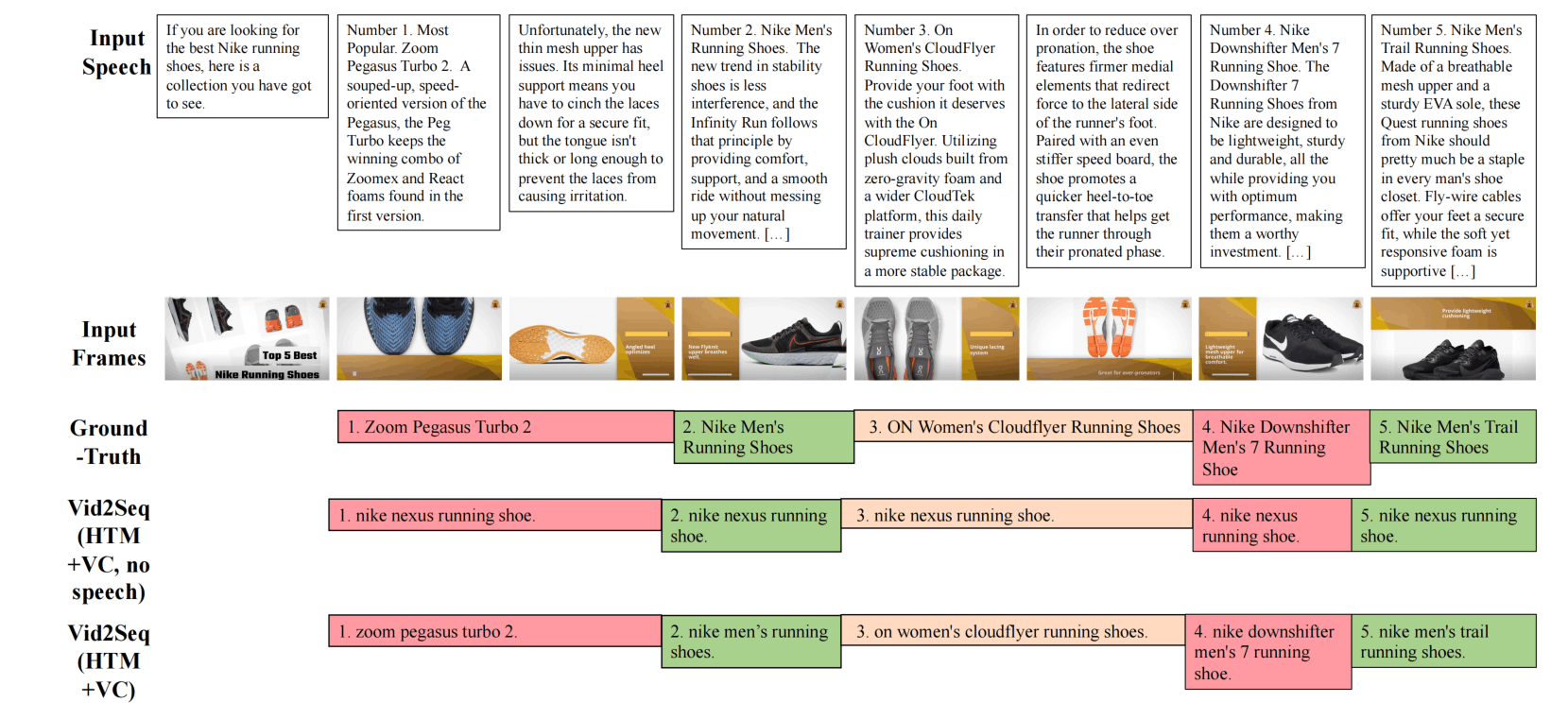
希望上图能看清……
这是一个广告视频,这个定位效果真的很好hhhhh,而且在加上speech之后,连鞋子的型号都能准确说出来。
总结
作者给出的Limitations是视频类别分布受限。作者给出的Societal Impacts说这个技术可能导致有害的下游任务,比如video surveillance。(可能西方人对隐私比较敏感?不是很清楚这里指的是什么)。同时还有老生常谈的偏见问题。
总的来说,这篇论文价值核心在于数据集的构建,大规模的数据集有了就更好进行训练和评价,同时我们也看到了Video Chapter Generation中Speech的重要性,这个重要性甚至超过了Visual,更别提视频的Motion了。所以B站才使用Language-only的方式搭建AI视频总结,同时B站的这个也可以划分章节,还能分更细致的章节,个人比较好奇B站的方式,不过可能就是prompt+LLM。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!