论文笔记 Vid2Seq Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
本文最后更新于:2023年11月6日 上午
论文笔记 Vid2Seq Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
论文链接:2302.14115.pdf (arxiv.org)
代码链接:scenic/scenic/projects/vid2seq at main · google-research/scenic (github.com)

Google的一篇CVPR2023论文,二作Arsha Nagrani长期研究视频领域,是从大名鼎鼎的VGG组出来的博士,比较著名的工作有Frozen in Time、Attention Bottlenecks for Multimodal Fusion、MV-GPT、VideoCC,另外最近我关注的AutoAD和AutoAD II(与国内上海交大谢伟迪组合作)也有她的名字。
返回到这篇论文,该文章提出了一个用来做Dense Video Captioning的通用大规模预训练模型Vid2Seq,如下图所示,走了模仿语言模型的路子,通过输出特殊的Token来同时预测事件时间范围以及事件描述。模型不大,但是在YT-Temporal-1B上使用ASR文本和视频预训练,然后在好几个下游任务上测试,测试的时候同时输入视频和语音转录文本,输出带有时间戳的文本。

方法
初衷基本就是看到目前做Dense Video Captioning的基本都是在小数据集上训练,无法利用噪声较多的大数据集,并且很多方法是二阶段的(事件定位->事件描述),不利于利用两个任务的相关性。所以它们提出了一种能够适配大数据集(视频+ASR转录文本)的模型,并使用一个阶段同时进行事件定位与描述。
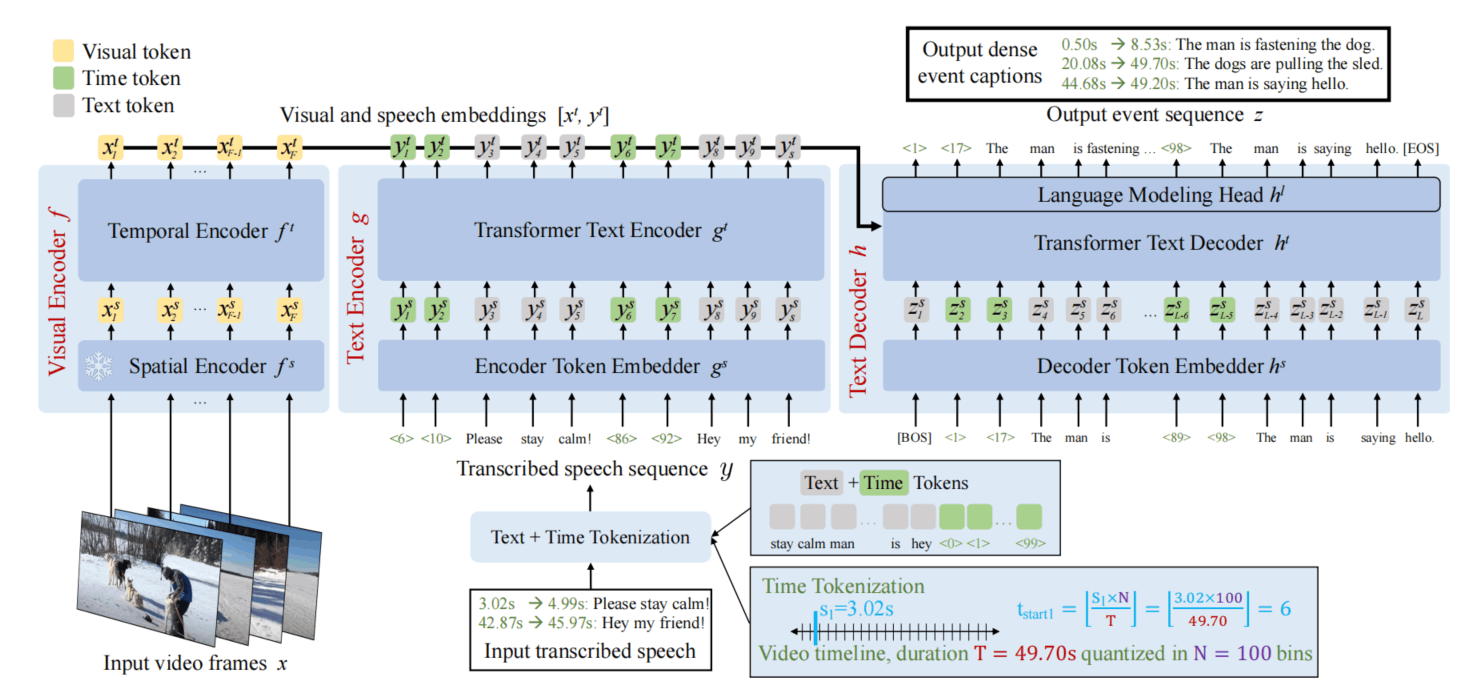
如上图所示是Vid2Seq模型的基础架构,编码器有Visual Encoder和Text Encoder,前者是CLIP+Transformer时序编码器,出来的蕴含了视频的动态特征;后者连同解码器在一起是一个T5-base,普通的语言模型架构。
特殊的是,编码器端输入的是一个带有时间戳的ASR转录文本,视觉编码器输入的视频会被量化为[1,100]这100个特殊的Token,时间戳也随之落到对应的区间,并附在对应文本的前面,一个是开始时间,一个是结束时间。特殊的100个Token是词典的额外扩充,会被转换成对应特殊的Embedding(原来32128,现在多了100个)。
编码器输出得到的所有Token串在一起,输入到解码器的Cross-Attention中,这里Token的长度不算长,是视频帧数+ASR的Token数量,视频帧数训练时控制在100,而文本则控制在1000内。
解码器进行自回归式生成,同样也是生成带有时间戳的特殊文本,包含所有的事件,一个事件包含两个时间戳Token和一段文字描述。输出的具体时间根据视频实际时长进行反推。

训练目标如上图所示是两部分,包含Generative Task和Denoising Task。使用的是从YouTube上爬取的原始长视频数据集,YT-Temporal-1B,包含了18M个有旁白的视频,每个视频平均有120句旁白。
对于Generative Task,给出视频,需要模型直接输出之前说的带有时间戳的文本,预训练的时候就是预测旁白所在位置和内容。
对于Denoising Task,是由于Gen Task无法对Text Encoder进训练,所以模仿T5添加的,T5中使用了Denoising Task进行预训练,实际上就是在输入文本中随机删掉一段,删掉的部分添加sentinel token(图中是[X][Y]),然后生成时得到被删部分的内容,每一段开头也是sentinel token。
Vid2Seq的架构使其适配于大规模数据集的弱监督信号,使用定位并预测旁白作为Dense Video Captioning的Proxy Task,这是这个方法最精妙的一点。
实验
实验很多,就不细看了,下面只介绍大概干了什么。
模型314M的可训练参数,基本就是时序的Transformer和一个T5-base,但是训练的数据量是充足的,进行了batchsize为512的200000次迭代,用64个TPUv4进行一天才能训练完。
训练数据集已经说过,是YT-Temporal-1B,下游任务数据集有YouCook2、ViTT、ActivityNet Captoins,还有普通Video Captioning的MSR-VTT和MSVD。
作者对预训练的视频长度、视频数量、使用的LM的大小都进行了实验,发现用长视频训练效果好,且能够scale上去,也用过1M的HowTo100M来预训练,和使用1.5M的YTT相当,然后发现还可以再scale上去。
对于两个目标,作者也进行了消融实验,发现两个目标都有用,并且输入多了Speech Text也是有用。
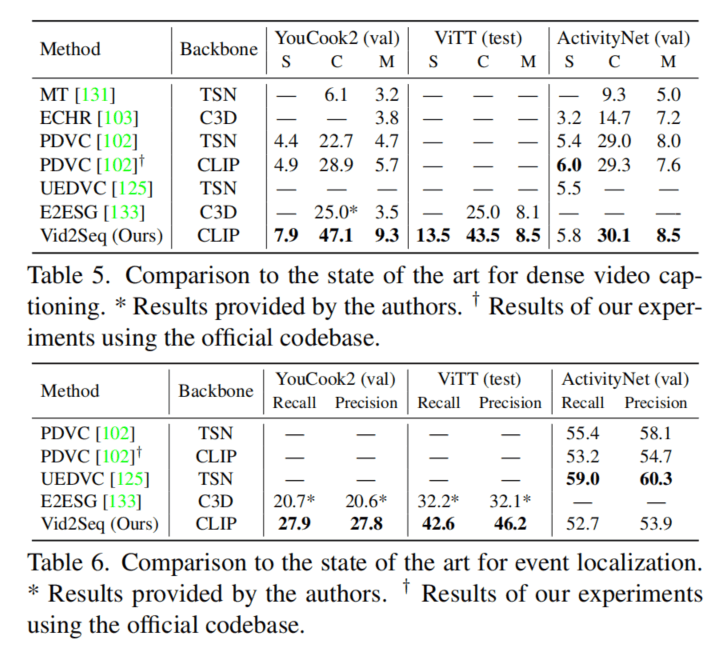
上面两个图是Dense VC的比较,在YouCook2和ViTT上的效果非常明显,在ActivityNet上则定位性能差了一些,因为没有其它方法精妙的定位模块。
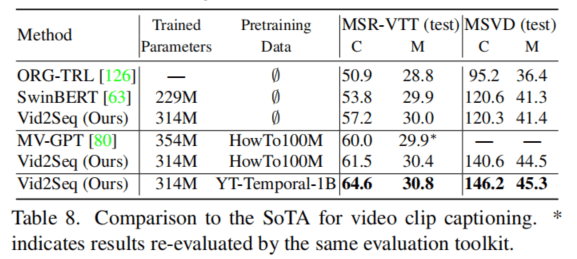
在VC上也进行了比较,在不预训练的情况下, 效果和SwinBERT接近,预训练后则效果极佳,但是目前看来没有达到最佳水平,但是也很好了。
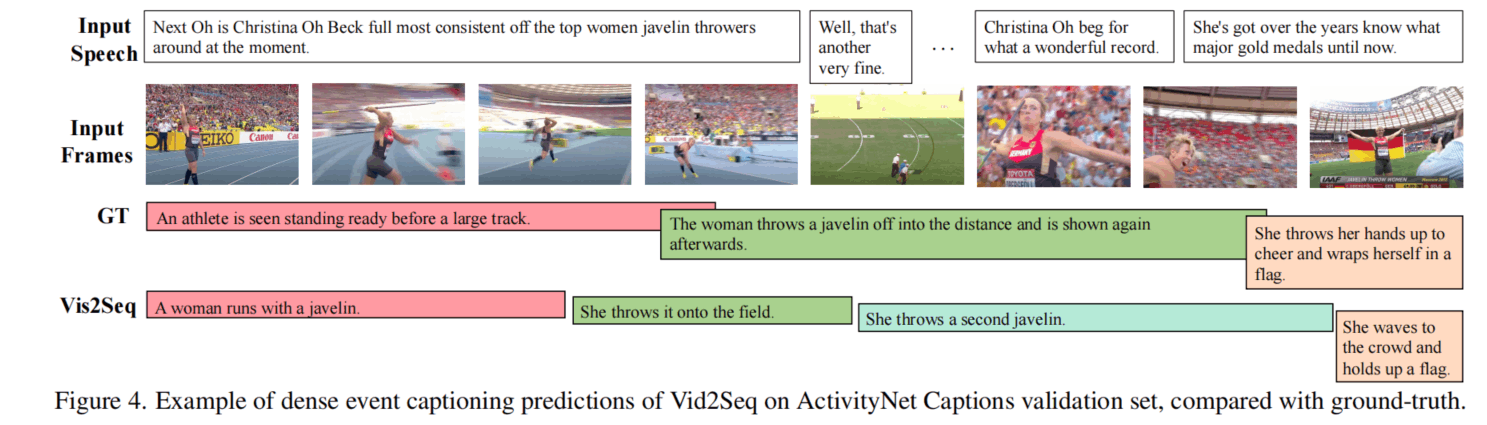
此外还进行了Video Paragraph Captioning和Few-shot的实验,就不一一列举了。下面放一些定性实验。
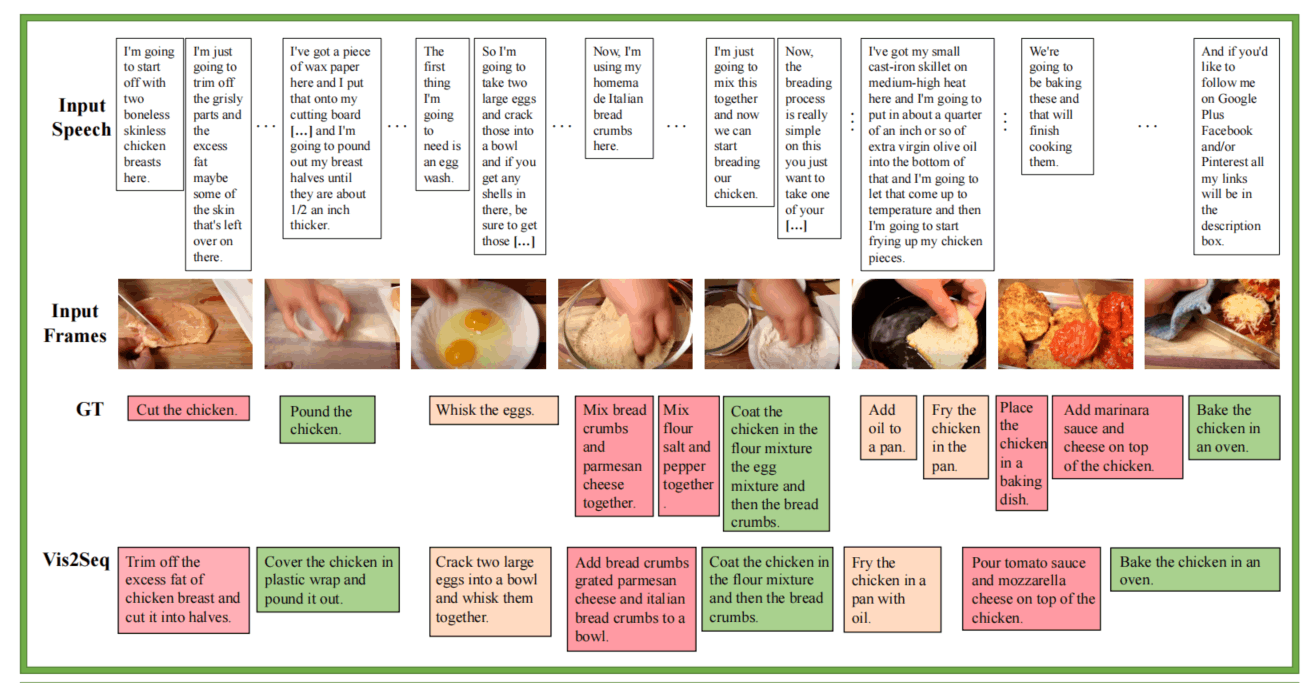
总结
Vid2Seq的整体思路是非常清晰和新颖的,Arsha Nagrani这个作者的多个论文都有这样的特点,这篇论文写作上也非常流畅,值得关注。
Vid2Seq设计了一个简单的架构,适配了LM预训练参数,统一了定位与生成任务,设计了巧妙的代理任务进行预训练。这种时序定位的任务,时序过于精准可能是不太必要的,因为事件本身很难说有精确的边界,所以文中也是通过量化的方式来放松这一个要求。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!