论文笔记 SoccerNet-Caption Dense Video Captioning for Soccer Broadcasts Commentaries
本文最后更新于:2023年10月30日 中午
论文笔记 SoccerNet-Caption: Dense Video Captioning for Soccer Broadcasts Commentaries
论文链接:SoccerNet-Caption: Dense Video Captioning for Soccer Broadcasts Commentaries (arxiv.org)
项目主页链接:SoccerNet - Dense Video Captioning (soccer-net.org)
CVPR 2023 Workshop的一篇主办方的论文,构建了一个足球比赛数据集,并标注了激情的解说,提出了一个新任务,即Single-anchored Dense Video Captioning(SDVC),即单个锚点的DVC。
SoccerNet-Caption Dataset
视频来自SoccerNet的471个足球比赛视频,视频质量较高(25fps×720p),标注从flashscore website爬取而来(不了解足球,不知道是啥……),最终获得了715.9h的视频和36894个有时间标注的comments。
除了这些文本评论,他们还收集了关于比赛的元数据,包括所有球员的球衣号码、裁判的名字、球队的名字、每支球队的首发阵容、他们的战术、11名首发球员、替补球员,以及与球员相关的任何事件,如进球、助攻、替换和黄牌/红牌。
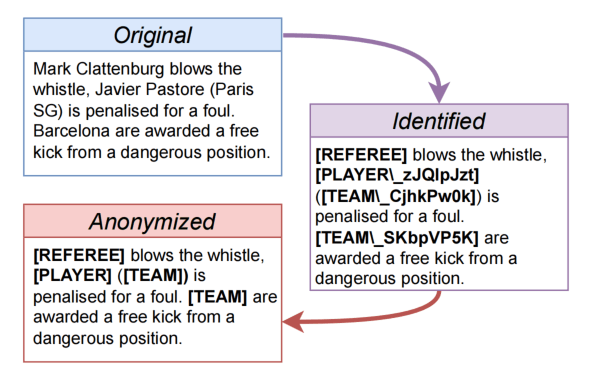
和一些早期提出的电影描述数据集一样,数据集的标注提供了匿名版本,因为目前的Captioning方法较少去考虑人名、队名,所以替换成一些特殊的符号。
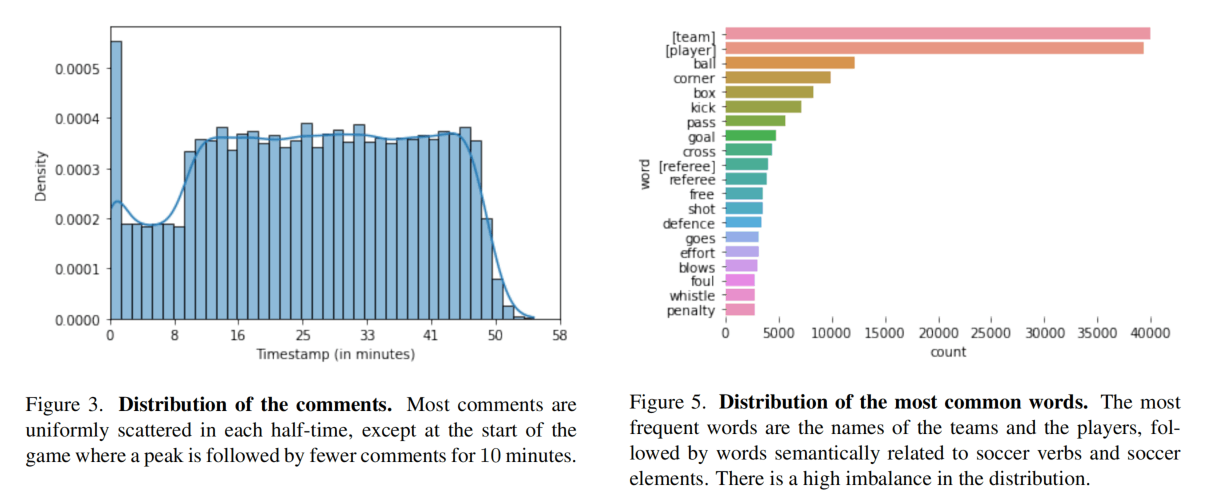
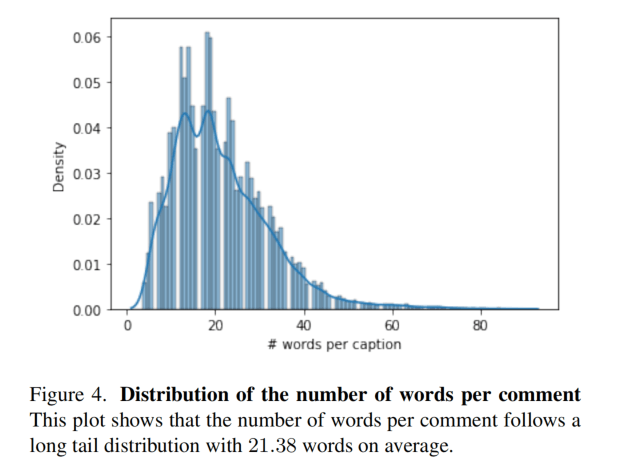
一场比赛比较久,图3是0分钟到60分钟的分布,比较均匀。图5是最常用词,足球领域常用的词频率很高。图4是词数量分布,平均21.38个词。
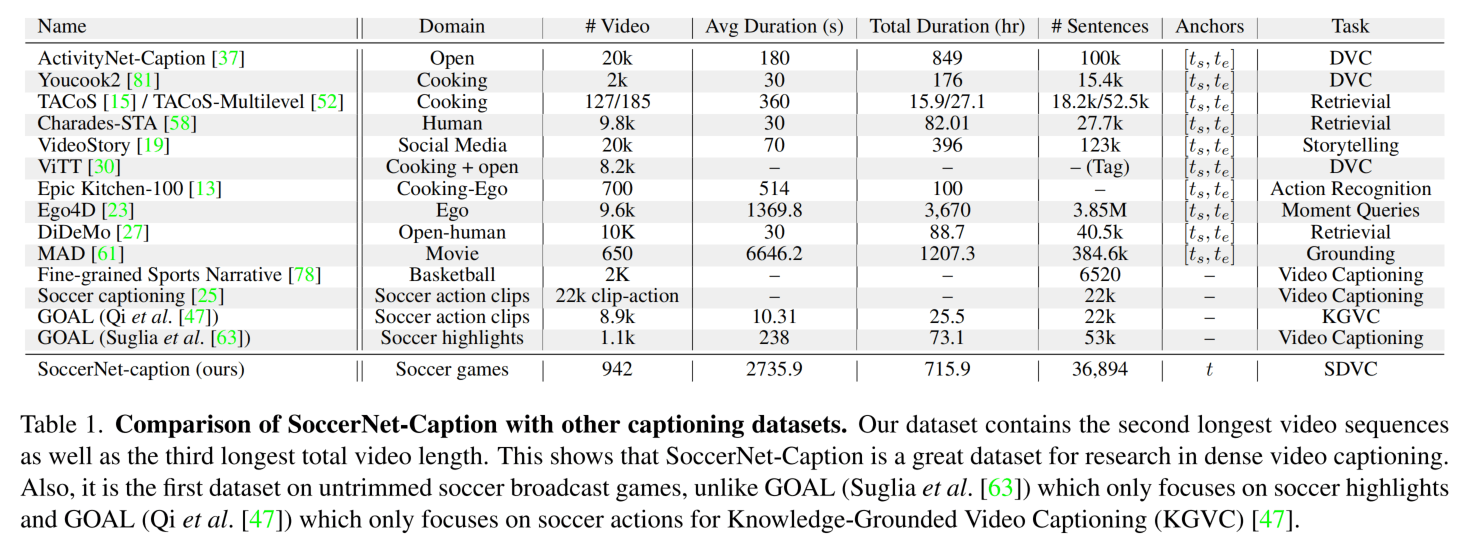
下面是与其它数据集的比较,这个数据集的视频数量少,但是总时长比较长,并且是适配它这个新任务的。
Single-anchored Dense Video Captioning
Single-anchored表示和以往的DVC不一样,没有开始时间和结束时间,而是只有一个评论应该开始的时间。因为足球评论不是一个有明显边界点的东西。(这一点也可以借鉴到其它任务中,比如异常检测的异常可能也没有明显的时间点)
在评价指标上,使用来衡量定位准确性,其中是时间上的容忍度,只要在容忍度范围内就算。对于语言准确度,使用M、B、R、C这四个最常用的指标,以及一个SODA_c指标。
SDVC baseline
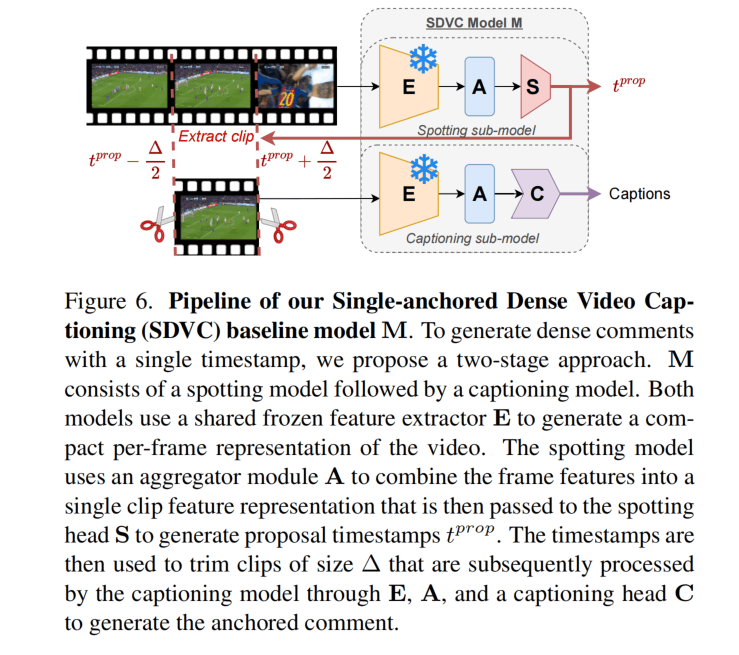
整个模型为M,包含冻结参数的特征提取器E、一个聚合模块A和Spotting头S和Caption头C。E得到帧级别特征,A进行时序聚合,然后通过S和C进行结果预测。
对于S出来的时间点,围绕其截取的时间段,然后送入C进行推理,S本质是一个二分类,表示一小段视频是否应该有comment。训练的时候视频被randomly cropped,然后使用BCE损失。(这里不太理解,正例应该是按照标注得到的,负例就是随机裁剪的?)。
推理的时候,整个视频分成有重叠的窗,得到分数之后用NMS平滑。
C本质是LSTM,使用了Teacher Forcing训练,这个没什么特别的。
特征编码器尝试用了ResNet、I3D、C3D、Baidu,聚合模块尝试用了NetVLAD、NetRVLAD、NetVLAD++、NetRVLAD++。
实验
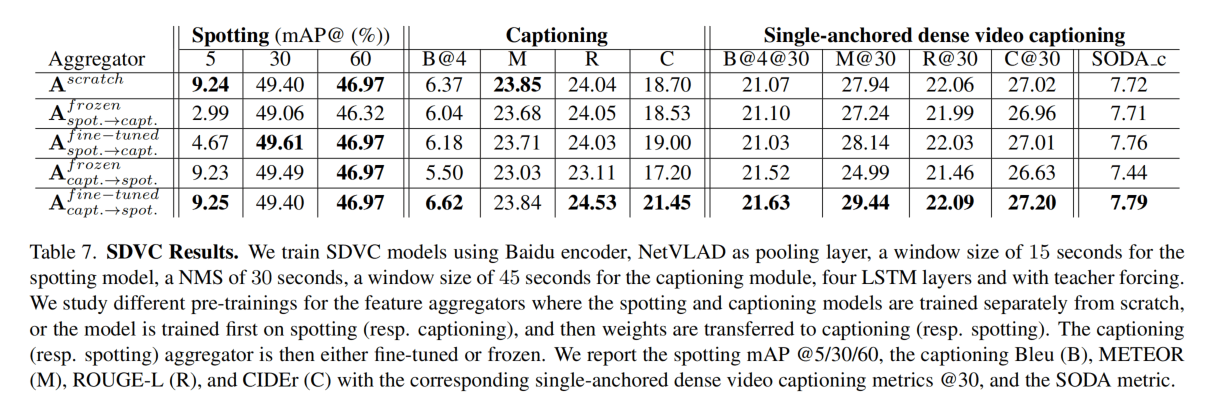
实验很多对于特征等的消融,没什么兴趣,这里看一下最后的一些结果。
在有30s的容忍度的时候,AP大概是50%,确实不能说很好。Captoining的C值也只有21左右。说明这个任务还是有难度的。

官网上有个leaderboard,这个OPPO的薄纱其它啊,CIDEr有69.73??

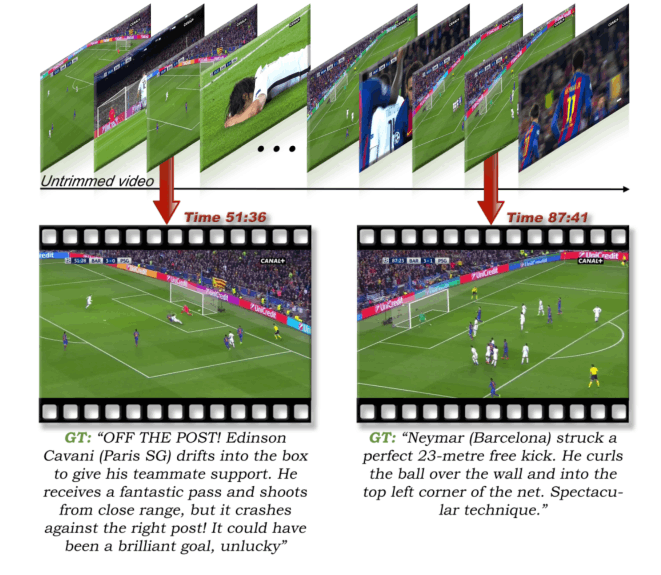
这个是定性实验,额……虽然我不太了解足球,但是这个d有点离谱,感觉模型是在瞎说……,这种模型真的能理解足球比赛里面谁是队友、点球、角球这些吗?
总结
基本就是主办方提出了一个难度很高的数据集让人来搞,这个任务还是很有意义的,但是目前的baseline感觉不足以解决这个任务,涉及到的难点太多了,要理解一场足球比赛还是太困难了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!