论文笔记 Human-centric Behavior Description in Videos New Benchmark and Model
本文最后更新于:2023年10月26日 晚上
论文笔记 Human-centric Behavior Description in Videos New Benchmark and Model
论文链接:Human-centric Behavior Description in Videos: New Benchmark and Model (arxiv.org)
西北工业大学吴鹏组的一篇Arxiv论文,发表于2023.10,提出了UCCD(UCF-Crime Captioning Dataset)数据集,该数据集对UCF-Crime里出现的7820个人的行为进行了描述文本标注(以及bounding box),并以此数据集提出了以人为中心的行为描述新任务,还提出了一个针对这个新任务的模型。
UCCD 数据集

上图是三种任务对应数据的比较,VC是对整个(简短)视频的一个简单的描述,DVC需要预测事件并分别描述各个事件,UCCD数据集则针对人,每个人在视频中完整的行为都将被描述出来,描述语句可能包含多个句子。
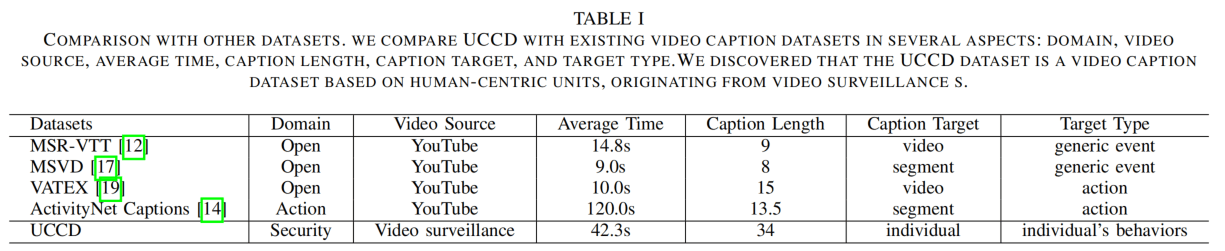
在数据统计分析上,UCCD是监控视频领域的,时长比VC任务的MSVD、VATEX、MSR-VTT长,比DVC的更短,但是描述长度是非常长的。数据标注用了20个native speaker,200h的培训+5000h的标注,每个视频至少要5个人来标,花费了约6000美元。
标注时,他们先用了300h把7820个人的bounding box标了出来,然后再进行文本的标注。论文里没有说5个人是怎么合作标注的。
模型
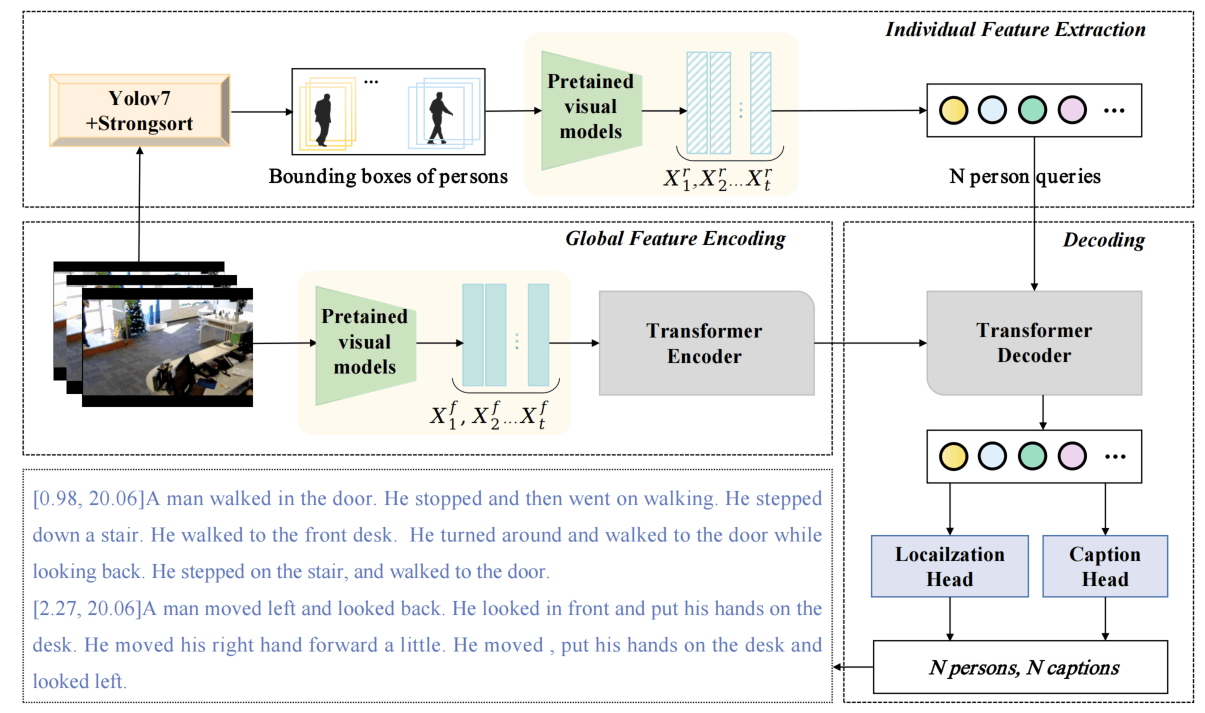
视频首先分帧,然后用YoloV7+Strongsort+OsNet进行目标检测和跟踪,把同一个人的box resize到相同大小送入预训练图像编码器(C3D、I3D、CLIP)提特征,作为person query。同时视频的整体特征也使用预训练模型(I3D)提取,并每帧独立送入Transformer Encoder中进行编码。
解码器是一个Deformable Transformer Decoder,并在输出接了一个Localization Head和一个Caption Head。这一块的原文的表述十分不清晰,期待其上传更新版本。
解码器可能是以person queries()、每一个query对应的参考点()、帧级别特征()作为输入。然后进行Deformable Attention,即用经过全连得到偏移量和对应的权重,然后对K个参考点和L个尺度进行加权求和。
Localization head预测开始时间、结束时间和置信度分数?但是又说是什么Box Prediction,这个box完全不知道是什么。
Caption Head的表述十分不清晰,图上没有体现LSTM的事情,但是论文Section IV.D部分莫名其妙跑出来了一个LSTM。
他们说传统的captioning模型只考虑将人物级别的特征,缺少与语言和帧特征的交互,为了改进,有了Deformable Soft Attention。这里传统的captioning模型压根不考虑人物级别特征呀?而且语言特征也不是很清楚说的是什么。
总之,训练的时候有GIOU的损失,有Focal损失,还有caption的损失。
实验

先定性实验,与Vid2Seq比较了,但是Vid2Seq是针对事件的DVC,和这个针对人的不太一样,但是还是实验出来了,其实……感觉和Vid2Seq差不太多,然后模型离GT都差的挺多。
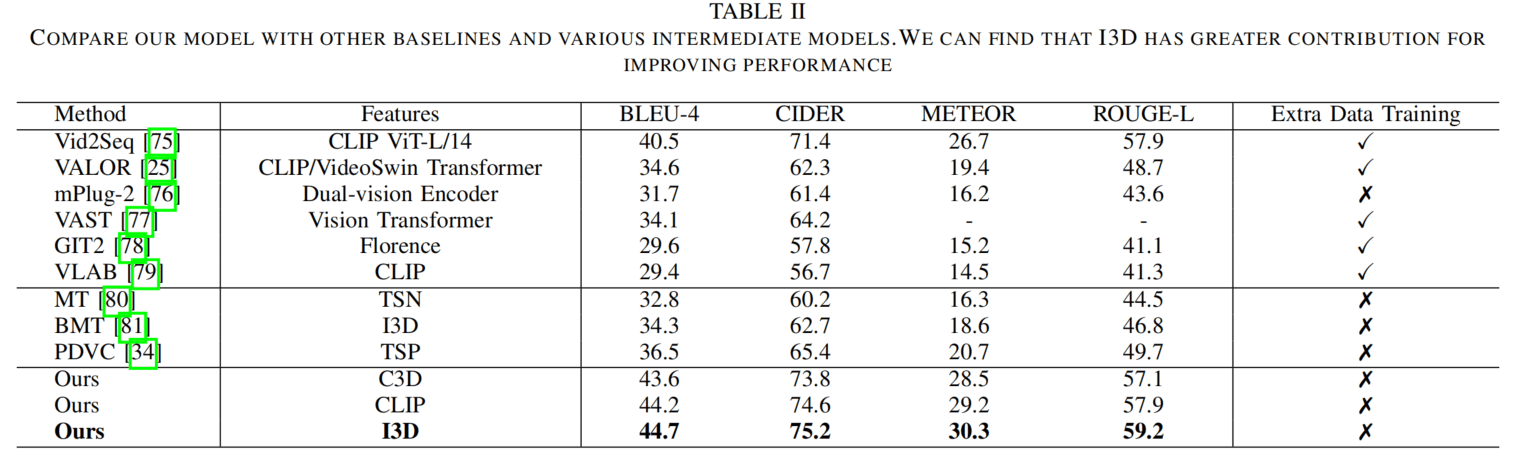
然后是定量实验,与SOTA进行比较,这个也看不太懂,没有细说怎么进行的比较。DVC会生成多个描述还好说,但是VC生成一个描述怎么算指标啊……
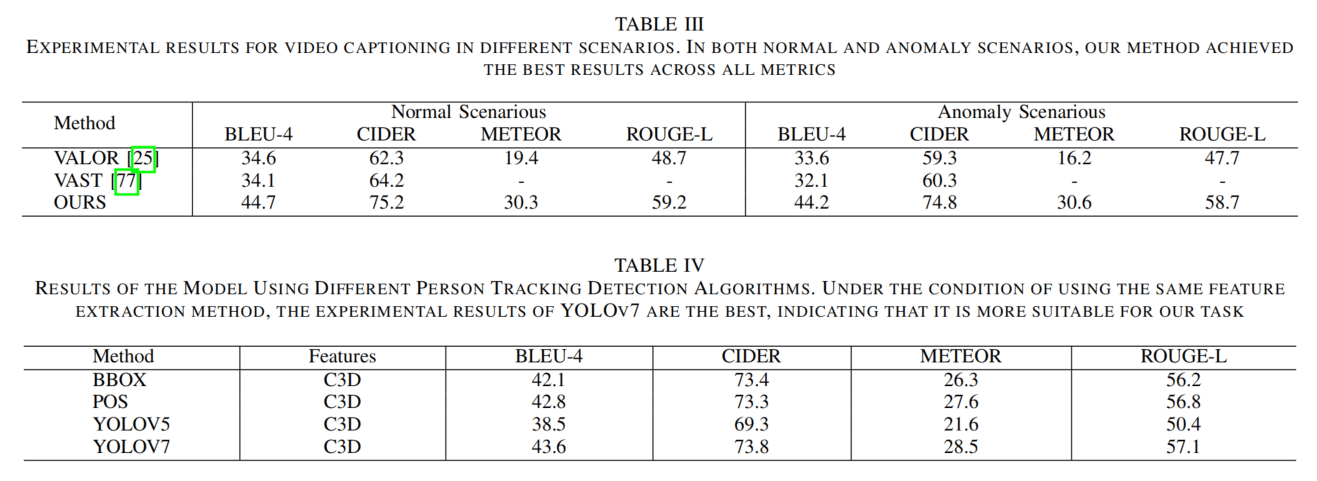
表3进行了正常和异常的描述,这里OURS写错了,然后VAST为啥不给METEOR的指标?结果发现他们根本没在新数据集上训练过,合着你拿在这个数据集上训练的模型比别人在另一个数据集训练然后在你这个数据集上zero-shot的结果???
表4说用了两种方法,可是有4行……

消融实验,反正就是都有效,都是好。
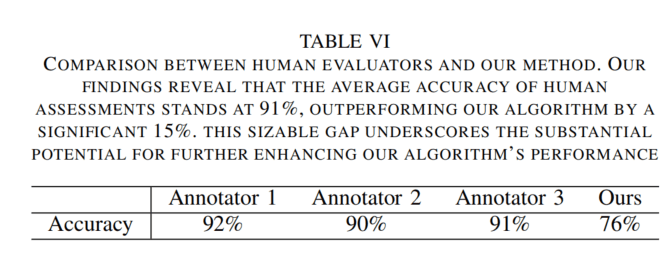
表6,人工评测,这里ACC又是从何而来????
总结
目前论文有很大很大很大很大的缺陷,基本不怎么能看懂,除了数据集看上去挺有价值,其余看上去就像是瞎编的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!