论文笔记 UCF-Crime Annotation A Benchmark for Surveillance Video-and-Language Understanding
本文最后更新于:2023年10月24日 上午
论文笔记 UCF-Crime Annotation A Benchmark for Surveillance Video-and-Language Understanding
论文链接:UCF-Crime Annotation: A Benchmark for Surveillance Video-and-Language Understanding (arxiv.org)
北京科技大学的一篇2023.9的Arxiv,对UCF-Crime进行了精确到0.1s的caption标注,提出了新的UCA(UCF Crime Annotation)数据集,支持temporal sentence grounding、video captioning、dense video captioning任务。
UCA数据集

首先,去掉了少量质量低的视频,并分成了训练、验证、测试集。
其次,这篇文章对UCF-Crime里的视频进行细粒度的标注,尽量把所有的事件都标注出来了,不管是否异常事件。
标注使用10个人花费1000小时,还有额外的3个资深人花费500小时进行标注审核。

如上图,时间非常精确,标注也比较丰富,但是例子给的不是很多。

异常和正常的视频大概均衡,但是在测试集差的有点多。不过,异常视频中包含的基本应该也是正常的事件,所以异常描述整体来说应该是偏少。
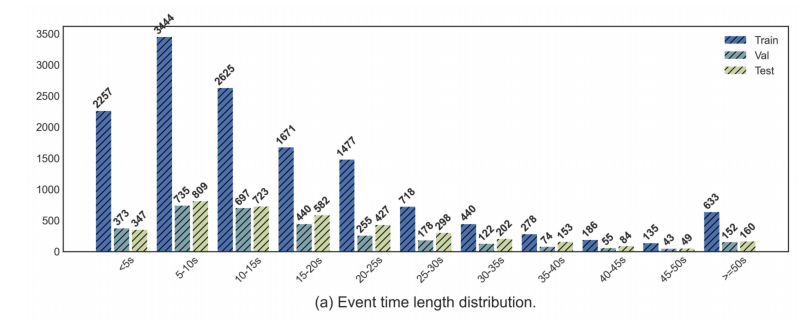
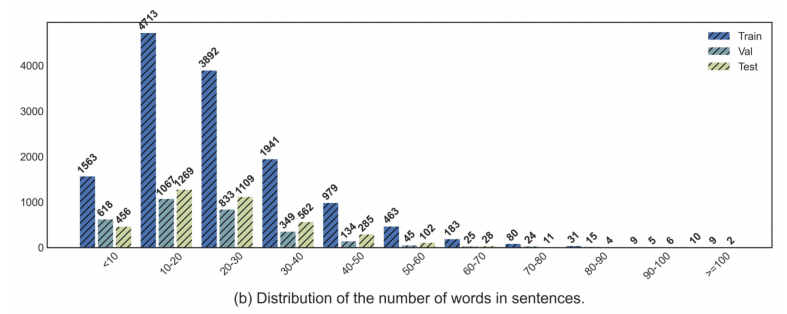
如上图,事件有长有短,最长可能超过50s,而25s内的事件是最多的。标注的长度也算聚集在40个词内。
Baseline比较
TSGV任务
就是给一个句子,要求找到视频中对应的时间段,就是video moment retrieval。
跑了6个开源的baseline,使用了相同的特征(这里感觉不是很有必要,因为论文不是要去比较什么方法比什么方法好,而是提供一些方法在这个benchmark上所能达到的最好效果是什么样的),指标普遍偏低。比如IoU=0.3的R@1,就是说预测的事件范围与标注范围的重合度大于30%的基本都低于10%,而R@5就是预测的top-5个范围中重合度达标的最高也只有22.3%。把这个阈值提高到0.5、0.7就更惨不忍睹了。

Video Captioning任务
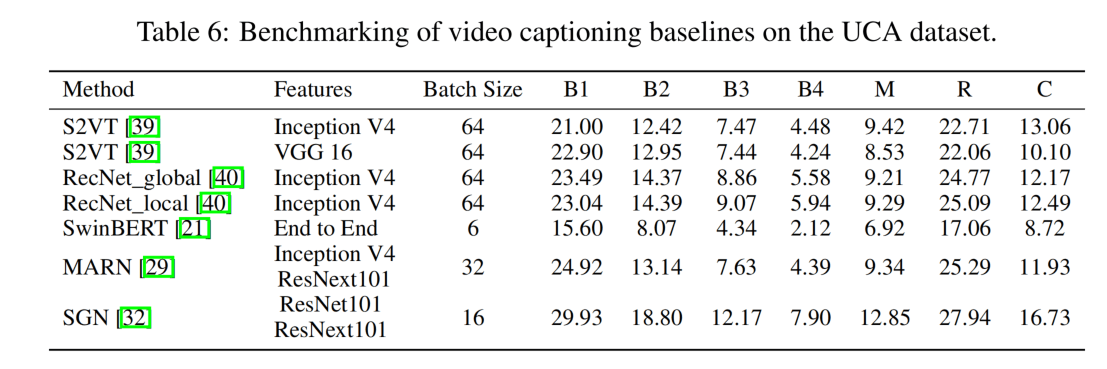
对视频进行描述,跑了5个baseline。这一块我比较了解。
首先看结果,CIDEr指标最高才到16.7,基本属于瞎说,可以认为难度是很高的。
其次里面23年的SwinBERT居然比不过15年的S2VT😂,这感觉是跑得有问题。那么问题出在哪呢?作者分析是预训练模型的问题,但是我觉得这个有点牵强,按道理SwinBERT的表征能力应该比其它的好很多才对,对于数据量来说,MSVD都能训起来,这个应该问题也不大。
此外,还有就是这篇文章对实验怎么进行的介绍太少了,按照目前的表述可能是直接把长视频送进去训练的,但是VC一般都是针对15s的短视频,这个可能会导致指标的下降。
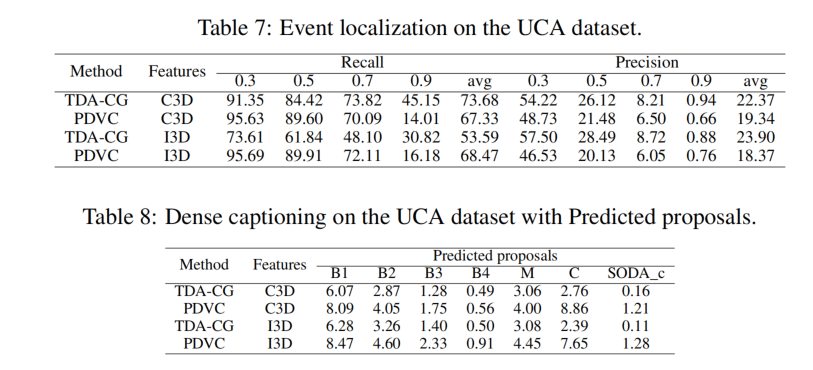
Dense Video Captioning任务
同时预测事件和进行Video Captioning,效果也是不尽如人意。这个UEDVC为为啥在前两个表里不放进去比??这里有使用GT proposal来dense captioning,为啥不套用一些普通VC的模型??论文写作的时候甚至表还放错位置了😢。

总结
这篇文章标注出了一个应该是相当高质量的UCA数据集,这个是核心贡献点。但是根据目前这篇在Arxiv上的pdf版本,论文还是有很多不足,首先对于数据集的样例给的太少太少了,不是很直观。其次虽然跑了很多baseline,但是没有一个的implementation是详细的,根本不知道是怎么做的实验。此外文中一些错别字和错位的表也很令人在意。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!