论文笔记 A New Comprehensive Benchmark for Semi-supervised Video Anomaly Detection and Anticipation
本文最后更新于:2023年10月23日 晚上
A New Comprehensive Benchmark for Semi-supervised Video Anomaly Detection and Anticipation
项目主页:NWPU Campus dataset (campusvad.github.io)
代码链接:zugexiaodui/campus_vad_code (github.com)
西北工业大学的一篇CVPR2023,提出了一个新的NWPU数据集以及一个新的Video Anomaly Anticipation任务。数据集基于监控视角,包含更多场景、更多异常类别和更长视频。新的VAA任务可以对异常事件进行短时(如5s)的预测。

NWPU Campus数据集
NWPU Campus数据集包含了在西北工业大学校内以监控视角拍摄的16.29h的视频,总共有305个训练视频和242个测试视频,其中训练集只有正常视频,测试集则同时包含正常和异常的视频(4.8:1)。
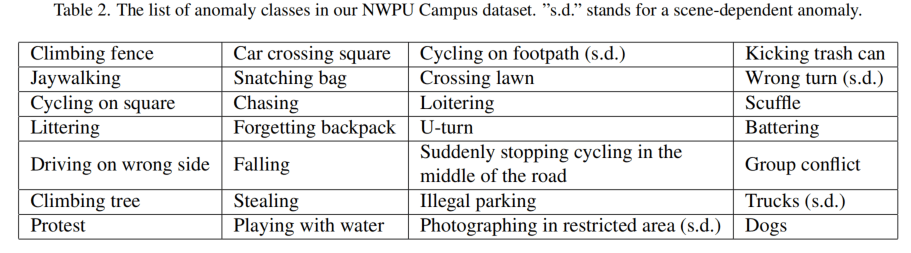
异常种类如下表所示,总共有28种,比如爬栏杆、横穿马路、丢垃圾、车辆掉头、狗、抗议、卡车、错误转向等等。一些示例可以看上面的图。标有"s.d."的表示这个事件是根据场景而言的,比如"Photographing in restricted area"在有的场景不算异常,在有的场景就算异常。
数据集拥有帧级别的异常标注,但是没有异常类别的标注。
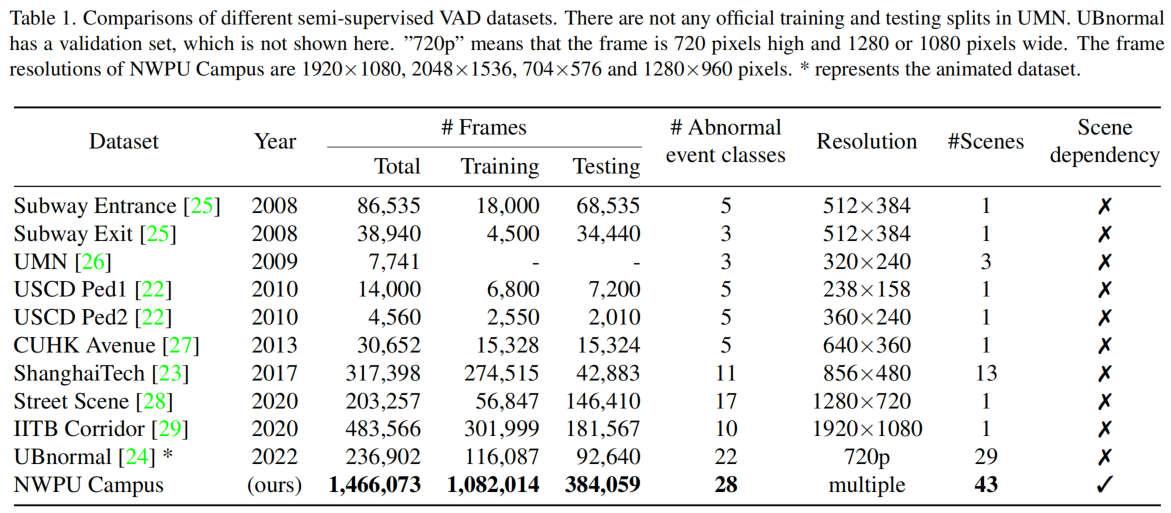
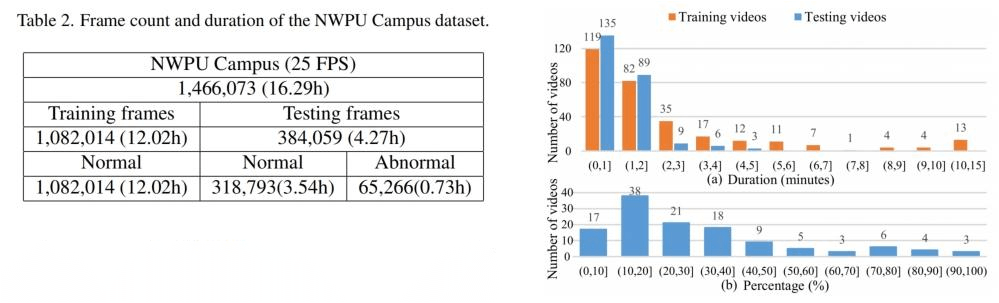
视频质量较高,有百度网盘,占用76.6GB。视频找了30个志愿者,设置了43个摄像头进行收集,部分视频是志愿者演的。视频的人脸和车牌号都被打码了。
Video Anomaly Anticipate(VAA)任务
VAD任务旨在检测视频的某一帧是否出现异常,而VAA旨在预测未来的一段时间内是否会出现异常。

如图所示,对于这一帧,他的标注是0,所以VAD的目标就是检测当前帧为正常,而对于VAA来说,它的未来帧中有一帧是1,即存在异常,所以VAA在当前帧要预测未来会发生异常。
Forward-Backward Scene-conditioned Auto-encoder

文章提出的基于预测的弱监督模型,主要包含前向U-Net和反向U-Net两部分,这一块原文写得比较绕,我简要说明一下。
Forward模型需要根据之前的帧来预测以及之后的帧,Backward模型则需要根据已有的帧和Forward预测出来的帧,由后面的帧来预测前面的帧。
在纯正常视频的训练阶段,这个模型就是两个方向的预测任务,而在异常视频测试的时候,Forward出来的结果应该会不准,而利用不准确的结果进行Backward,得到的结果也将是不准的,所以两次都会有较大的error,从而预测出了异常。
举个例子,图4中,一个人助跑()准备翻越栏杆,然后爬上了栏杆(),Forward利用助跑的画面预测爬上栏杆的画面()以及继续往上爬的画面(),但是由于Forward是由正常样本训练的,所以它预测的结果应该是这个人从栏杆边上离开()。对于VAD来说,不涉及到时刻及以后,就是将与进行误差计算,发现当前帧误差较大,可能是异常。对于VAA来说,预测的结果与真实结果相差较多,会影响接下来的计算。接下来,Backward将一部分真实帧和一部分预测帧作为输入,预测之前已有的结果。预测的“从栏杆边离开”的行为的倒推不应该有助跑,所以会有较大的误差。
训练的部分弄清楚后,具体来看模型的架构,都是U-Net支持的Conditional VAE模型,因为是VAE,所以会有一个将概率分布接近高斯分布的loss,这个loss与前面Forward、Backward加起来就是最终的loss。CVAE就是额外通过拼接和加权求和,将提前准备好的Scene image融入进来作为背景知识。CVAE架构如下图所示。
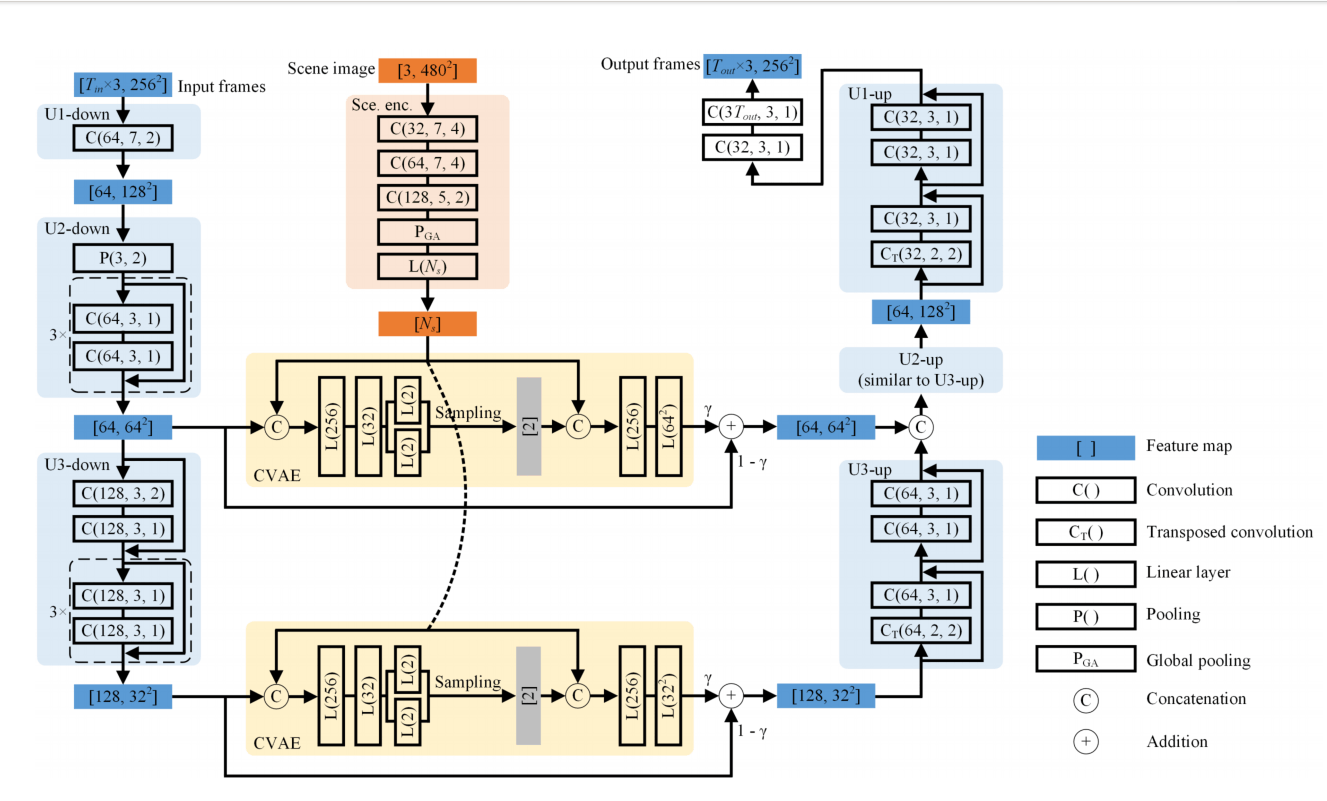
需要注意的是,模型的输入不是视频的原始帧,而是用预训练ByteTrack跟踪得到的 object region。
Scene image是精心准备好的关于视频背景的一张图,由于是监控摄像头,背景不会经常改变,所以准备这个不会很难。
实验
由于提出了数据集和新任务,论文复现了7种模型,其中有基于重构的1种、有基于距离的1种还有基于预测的5种。同样都用目标检测跟踪后的作为输入。在NWPU外的数据集不使用scene image进行比较。

如上图所示,结果是很好的,Avenue数据集由于画质太差所以效果差了一点。
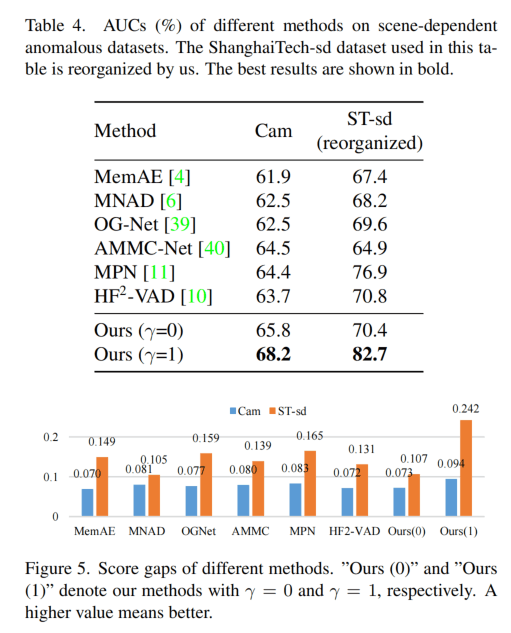
作者还是重新组织了ShanghaiTech数据集,使其变成Scene相关的,结果也是比较好,使用了scene image的效果好很多。

对于VAA,作者没什么可以比的,Chance是随机预测,Human是人眼评测,由于人对时间不是很敏感,所以是统计在3秒内会出现异常的AUC。本文的方法比随机的好,但是距离人还是差了很多。
总结
新提出的数据集感觉是比较有用的,但是这种划分只适用于one-class的方法,假如是weakly-supervised的方法,需要异常视频来训练,那么这个数据集可能就需要重新划分了。数据集的质量看上去是很不错的,但是难度也很大,有些与场景有关的就使模型必须要去考虑这一点了,不然是完全没办法处理的。
新提出的VAA任务有些麻烦,最后也是只能预测出3s的效果,这个感觉停留于概念阶段,应用价值不是很大,我预测这人后3秒会翻栏杆有什么意义呢?
文章做的实验还是很扎实的,至少给了一个比较完整的benchmark。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!