基于梯度下降算法的Zero-shot Captioning方法
本文最后更新于:2023年9月17日 下午
基于梯度下降算法的Zero-shot Captioning方法
介绍三篇文章,通过梯度下降算法来做zero-shot的image/video captioning,整个过程需要用到一个语言模型(如GPT-2)和一个多模态对比学习模型(如CLIP)。
| 论文标题 | 时间 | 来源 | 论文链接 | 代码链接 |
|---|---|---|---|---|
| ZeroCap: Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic | 2021.12 | CVPR22 | ZeroCap | 代码 |
| Zero-Shot Video Captioning with Evolving Pseudo-Tokens | 2022.7 | Arxiv | 2207.11100(arxiv.org) | 代码 |
| Zero-Shot Dense Video Captioning by Jointly Optimizing Text and Moment | 2023.7 | Arxiv | 2307.02682 (arxiv.org) | 无 |
ZeroCap: Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
这篇文章属于始祖,提出了ZeroCap模型,发表在CVPR2022上,是Tel Aviv University的一个团队发布的。
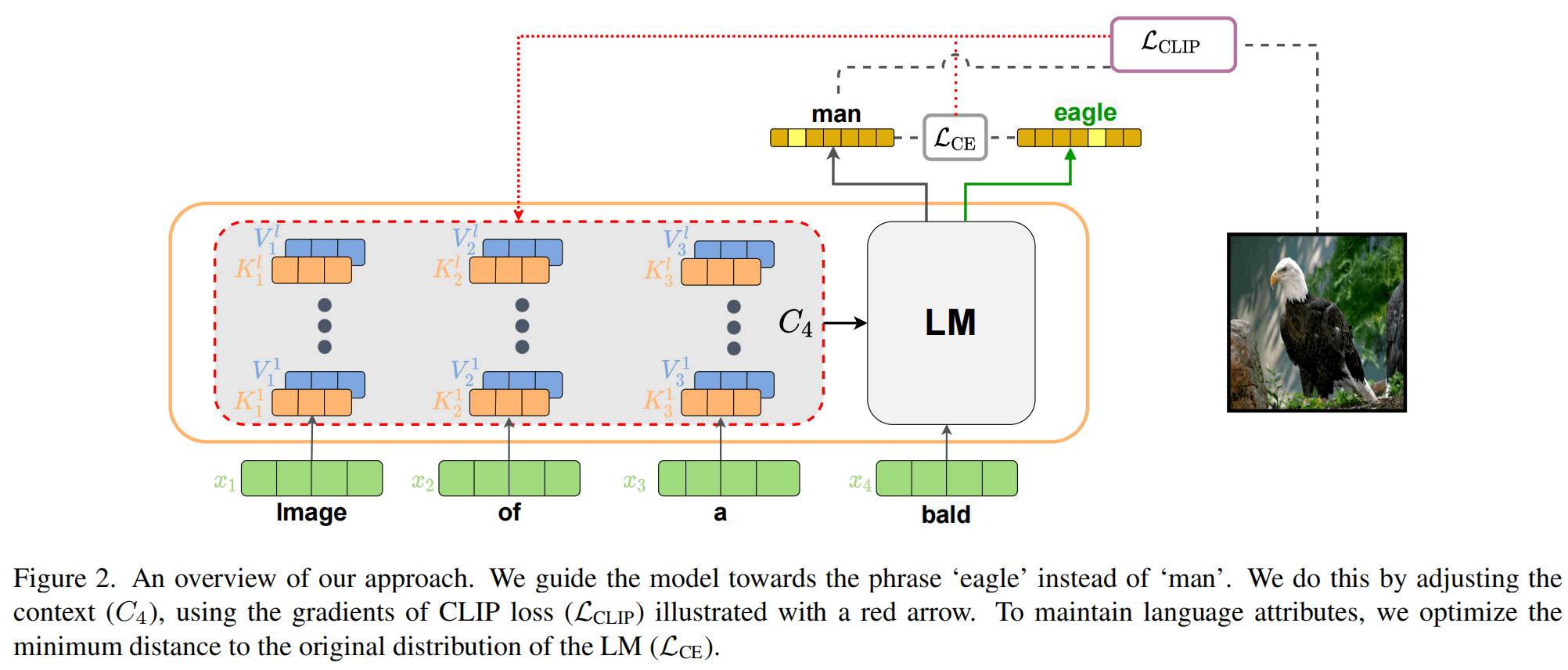
上图是ZeroCap的整体流程,基于Transformer的语言模型(LM)都会有QKV,其中K和V在自回归式生成过程中是可以被缓存的,而ZeroCap就利用了这些K和V,把他们统称为上下文C,对C进行调节可以改变模型输出的下一个单词的预测。
那么,C如何被调节呢?还是通过梯度下降算法。
在生成一个新的单词的时候,LM会输出下一个单词的概率分布,而为了令这个单词与图像相关,会使用CLIP计算与相关性有关的损失,同时为了令单词符合语言习惯,还会计算使用未修改的C时下一个单词的分布,并计算两者交叉熵作为语言损失。
通过两方面损失的制约,在生成一个单词(实际上可能是token)的时候,就得到了一个loss,就需要进行一次梯度回传,并通过优化器来改变C的值,从而辅助下一个单词的生成。
这样虽然利用了梯度回传和优化器,但是不需要任何数据来进行训练,可以不受数据分布的限制。
下面具体介绍损失是如何计算的。
CLIP-Guided Language Modelling
每生成一个token的优化问题总结为下面这个公式
首先看第一项,其中是第个token之前的所有层的key和value的缓存,是第个token,是输入第个token之后生成下一个token的概率分布,则是使用未经修改的C得到的原始概率分布。两个概率分布之间计算交叉熵来靠近。超参数设置为0.2。
其次看第二项,同样得到在输入第个token的时候的下一个token的概率分布,然后从中选出512个最大概率的candidate tokens,将其与之前的单词组合成句子,再计算句子与图像的距离,经过一些数值上的处理得到与图像相关的期待的分布:
然后两个概率分布之间通过交叉熵来靠近,是超参数被设置为0.01:
在预测过程中,通过损失函数来更新的参数:
其中学习率设置地比较高,为0.3。此外,作者还使用了beam search。
实验
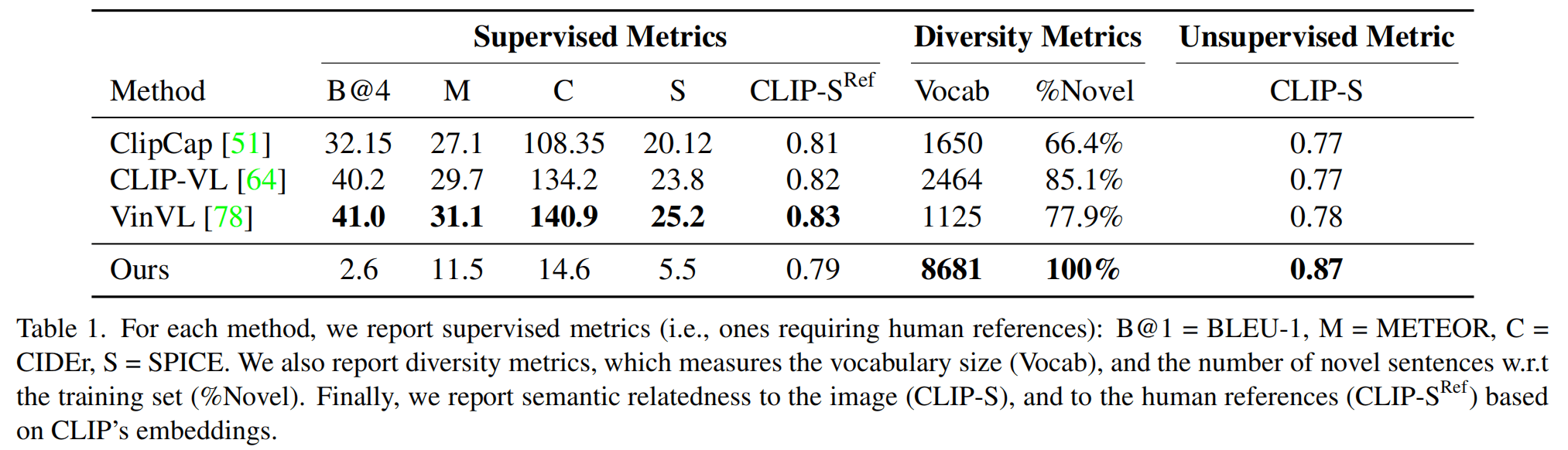
由于方法比较创新,没什么其它文献来比较,就比较了使用监督学习的方法,自然是在传统的指标上比较差(B、M、C、S),但是这里引入了几个新颖的指标,比如CLIP-Sore,加了ref就是文本与GT的文本的距离,不加ref就是文本与GT的图像的距离,后者在这篇文章方法上有更高的分数。除此以外还有多样性的指标,即词表大小和新颖度,新颖度就是生成句子与训练集中句子完全吻合的百分比,可以看到ZeroCap有100%的新颖度。
在预测速度上,单卡Titan X在5beam 512candidate的情况下3s生成结果。这个速度只能说一般。


以上是一些定性的结果,展示了这种方法可以对图片进行caption,并拥有一定的OCR和常识的能力。
然而,我们发现,这个方法解释的对象其实是一个CLIP的embedding,并不一定要是“图片”,只要在CLIP的空间里,还可以是其它的东西,所以这篇论文还展开了一些有趣的研究:
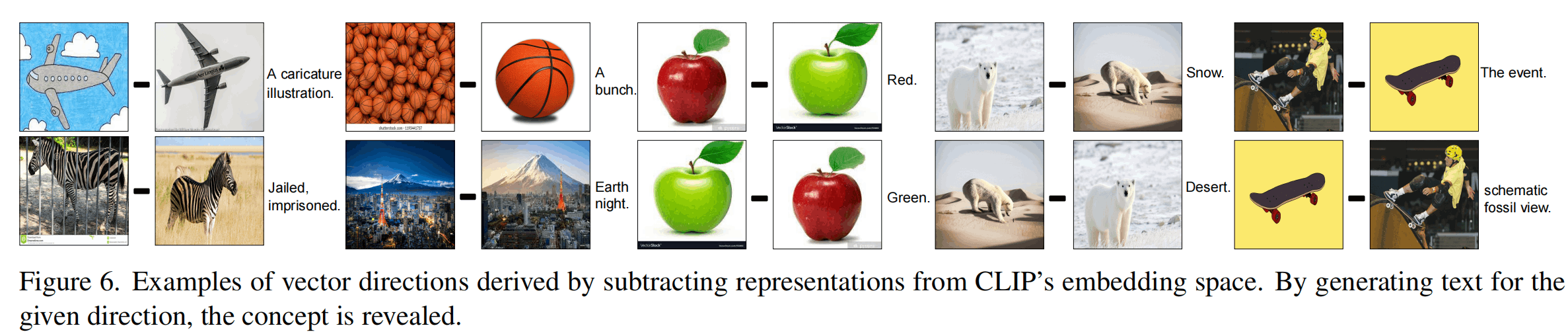

如图,作者对多个图片的embedding进行了向量的运算,从而对CLIP空间的方向进行了语义上的分析。Figure 6是减法,比如左上角是飞机的插画,减去飞机这个元素之后就提取出了“插画”这个语义元素。一堆篮球的图像减去篮球的图像就得到了“一堆”这个语义元素。Figure 7的加法也很有意思,人+法官锤就是法官,手机+苹果就是苹果手机……
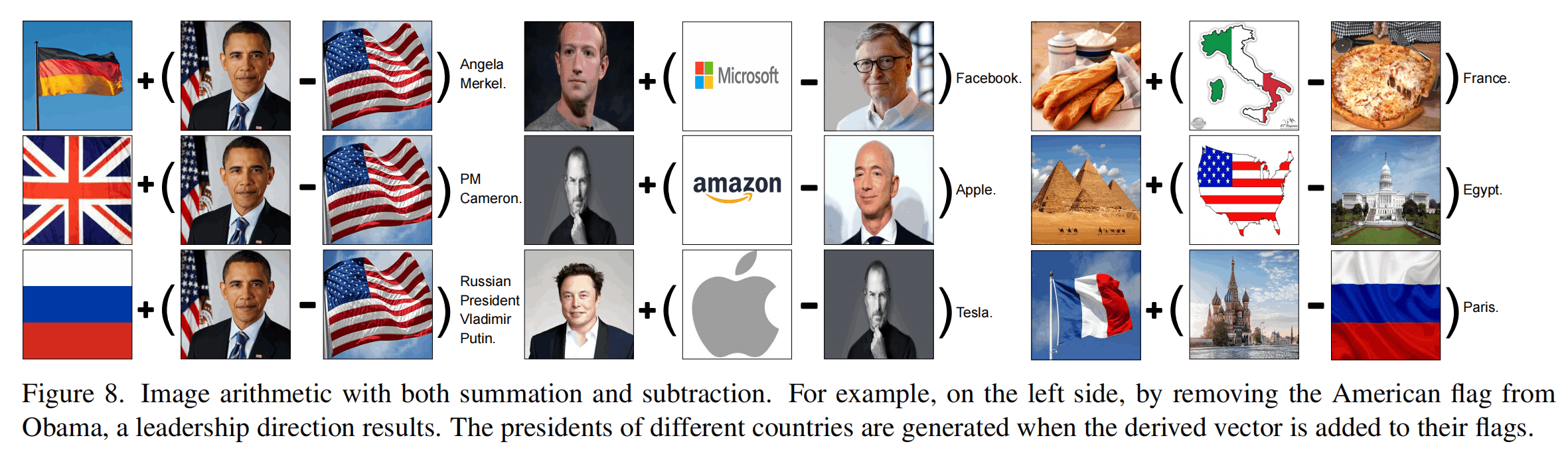
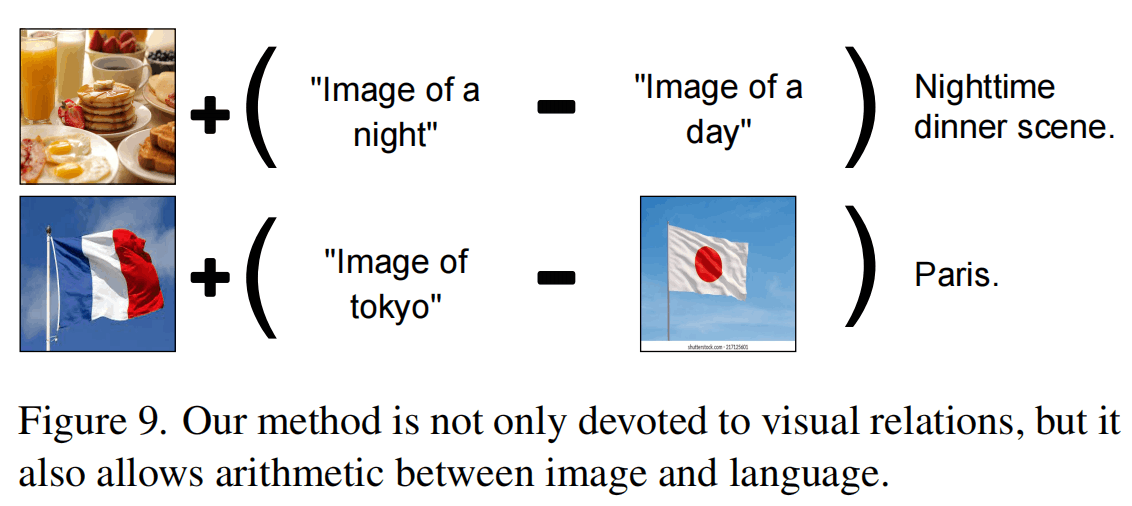
上面做一些更加复杂的运算,加入了更多的模态来做加减法。
总结
这篇文章提供了一种新颖的zero-shot的对CLIP embedding的解释方法,从令一个角度来说,是进行了zero-shot的image captioning工作。对于captioning任务,常规的指标限制性比较大,这个模型表现并不是很好,但是对于无监督的语义指标,模型表现则更好。但是,这篇文章也没有用更多的指标(可能目前也没有合适的指标),效果究竟好不好,还是未知数。传统的方法可能会对生成的过程进行更多的限制,而这里限制就更少了,但是又可能需要对生成过程进行更多工程上的规范(比如控制长度、降低重复、去掉无意义的特指,如“Flicker”)。
对于解释CLIP embedding的任务,这则是一个比较优秀的方法,并且现在ImageBind出来之后,甚至还可以解释更多模态在这个语义空间中的行为。(没有查询资料,不知道有没有人做)
但是限制也比较多,会受到LM和CLIP的偏见的影响。
Zero-Shot Video Captioning with Evolving Pseudo-Tokens
接下来介绍相同团队带来的一篇Arxiv上的文章,对之前的方法进行了改进,使其进行Video的Captioning任务。
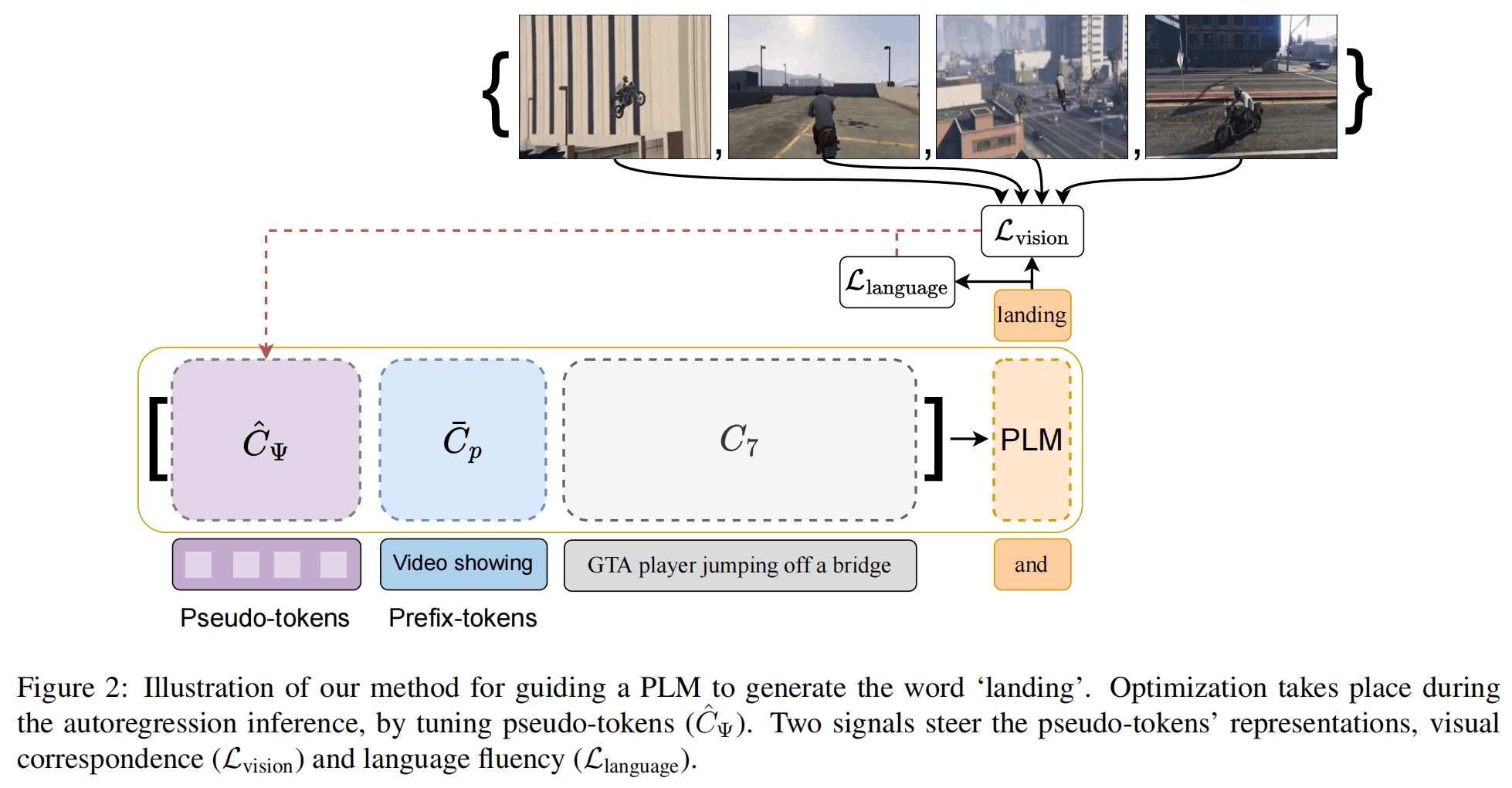
整体架构如上,和ZeroCap十分类似,都是通过一个语言的损失和视觉的损失来控制,同样是做基于随机梯度下降的zero-shot captioning。不同之处在于前面还添加了pseudo-tokens,并用其产生的C来接收梯度带来的改变。此外,这篇文章还进行了多轮的caption生成,从而避免单次生成带来参数学习不充足的情况。
接下来直接详细介绍其方法:
Method
最终的优化公式如下,和上一篇文章类似
其中,视觉部分的损失如下:
其中是第k轮的句子与所有帧的相似度的总和,这个相似度的计算是通过上一篇论文的方法,为了降低复杂度只用top 100的candidate token。语言部分的损失则如下:
其中,,PLM的参数是当前输入单词,是Pseudo-tokens,即随机初始化的类似prefix tuning的可学习向量,如上图是前缀的prompt,是之前生成的token。这里两次用到PLM,一次是更新后的概率,一次是更新前的概率(即不包含),两者靠近计算损失。
注意,全部的可学习的参数都在中。
在优化的时候,会进行多轮的优化,生成一个句子后,保留,再进行下一个句子的生成,文章这样生成16轮得到较好的效果。同时再prompt的选择上在范围内随机,起到augmentation的作用。
在采样帧的时候,文章没有固定采样,而是通过计算CLIP embedding的方式来选择最关键的帧。文章先选择第一帧作为anchor,之后按照顺序计算后续帧的距离,选择离anchor有一定距离的帧作为下一个anchor……就这样进行采样。
实验
使用单卡Titan X,一个句子需要5s生成,进行16轮则需要一分半的时间(还挺久的)。
同时也使用了top-k sampling的生成方式,还有避免长重复句子的限制,以及降低大写字母token的权重。

上图是使用这个方法进行迭代精炼的过程,可以发现句子越来越准确具体。
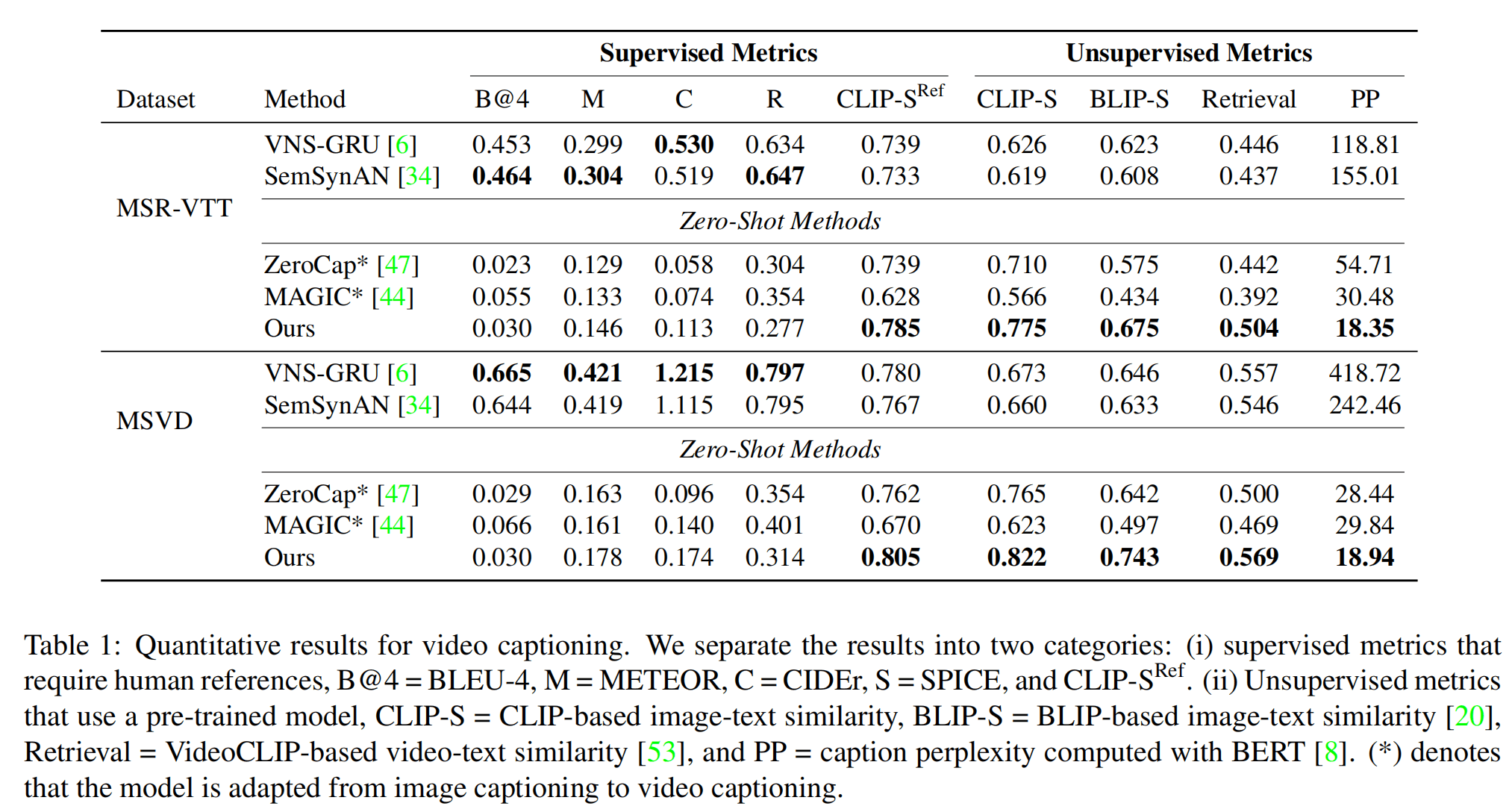
定量分析结果在两个Video Captioning数据集上进行,使用了更多的无监督的指标,体现出效果真的不错。


两个定性分析的结果,发现这篇文章效果挺好,迭代也是有效果的。
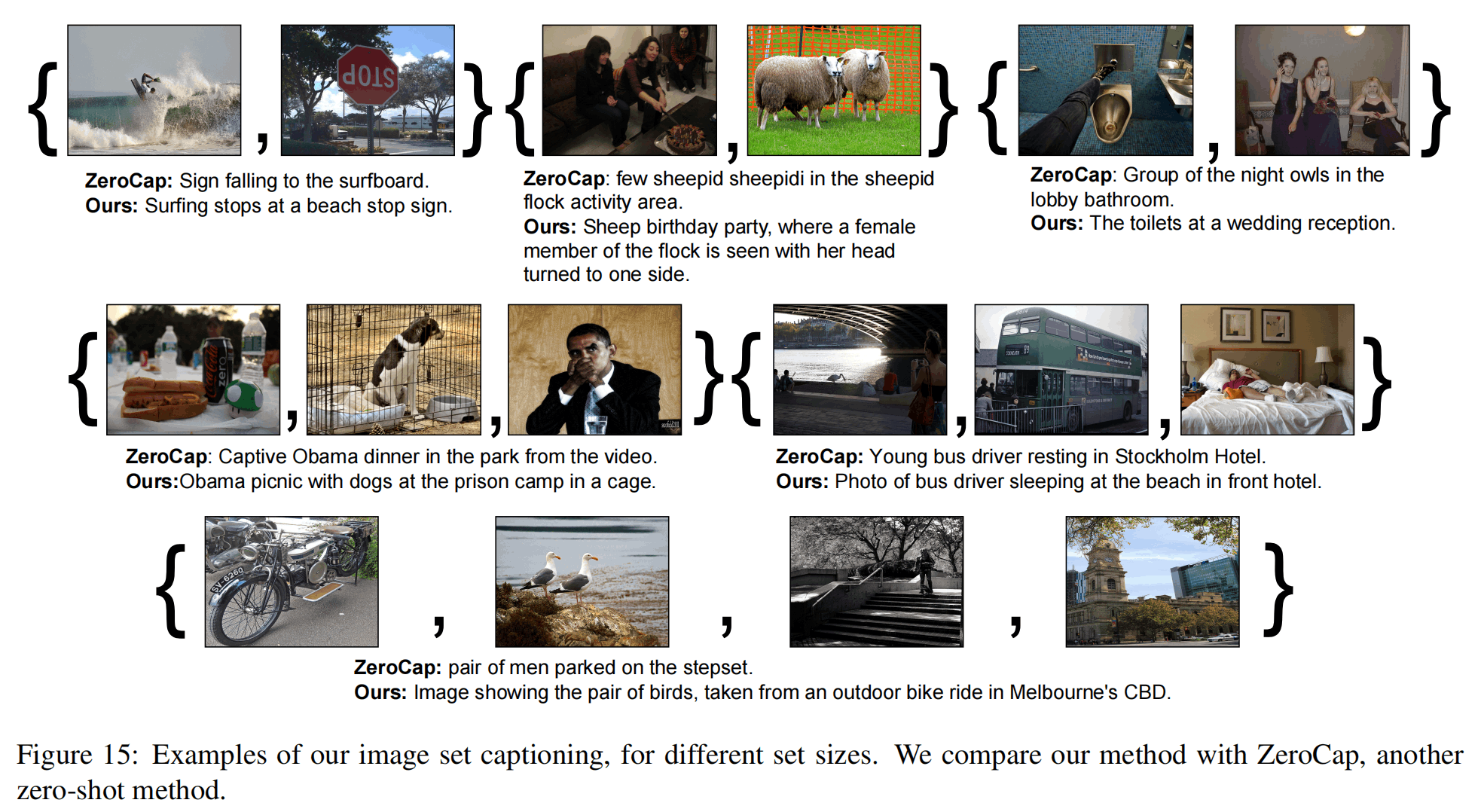
文章还进行了采样帧数/输入图片数的实验,如上图,对于几张几乎毫不相关的图片,模型还是能得到较为真实的叙述,图片越多说得也一般越好。

对于CLIP采样方式的可视化,一般都是检测镜头切换,效果是还不错。
总结
这篇文章提供了一种新颖的Zero-shot Video Captioning的方法,利用一个语言模型和一个image-text模型,通过多次的迭代,生成的句子会越来越好。首先这种zero-shot的方法在实际中应用的范围就广了很多,其次迭代的轮次是可以自定义的,所以在实际应用中也可以有一个质量和成本的权衡。
然而,还是有许多限制的。首先就还是web-scale的数据的问题,可能会有奇奇怪怪的词出现,如下图。此外,模型完全没有考虑时序信息,对于输入的多张图片,模型要自己来选择推断顺序,并且运动、速度等信息被完全忽视了。最后,效率也是一个问题,生成一个单词就要反向传播一次,更何况还需要多轮的句子生成。

Zero-Shot Dense Video Captioning by Jointly Optimizing Text and Moment
接下来再介绍一篇文章,是另一批韩国的团队最新发布的,将这种方法拓展到了Dense Video Captioning上来,提出了ZeroTA模型。
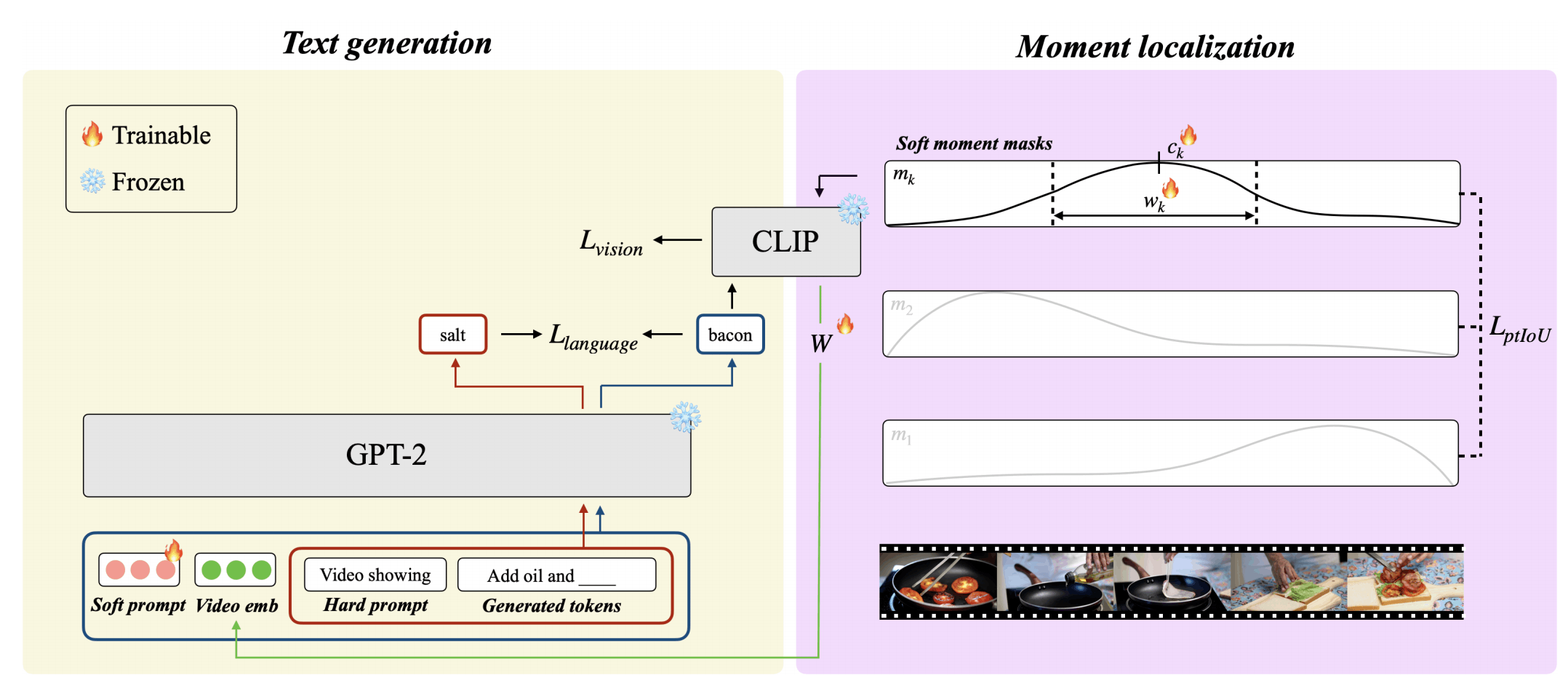
相较于上一篇文章,这篇文章基本是在做加法,添加了Dense所需要的定位事件的部分,以及作为LM输入的video embedding。
接下来详细介绍其方法:
LM的输入分为四部分,第一部分是Soft prompt,是可学习的参数。
第二部分是Video Embedding,moment通过CLIP提取特征,然后聚合之后通过线性层得到。
第三部分是Hard prompt,就是prompt。
第四部分是之前生成的token。
这里如何选择moment是重点,一个moment对应两个可学习的参数和,是归一化的中心和宽度,然后通过下面这个公式得到一个mask:
其中是某一帧的归一化坐标,是控制曲线锐度的超参数。
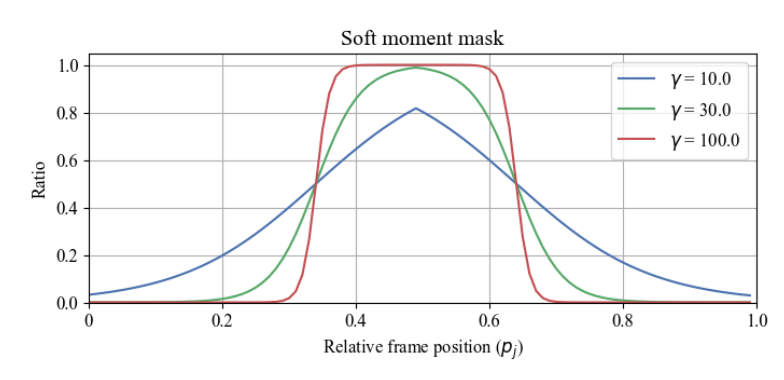
在预测过程中,会逐步增大,使sharpness增大。而一段视频的moment数量则作为超参数。
为了让模型关注几个不重叠的moment,除了通常的视觉和语言的损失,这里添加一个新的pairwise temporal IoU loss:
表示N个moment配对的可能性,IoU就是交并比。
最终的loss形式:
实验
使用CLIP ViT-L/14和GPT2-medium,三个分别为,moments数量为4/8,进行12轮迭代。
使用C、M、S(SODA_c)三个指标,这里SODA_c之前没见过。
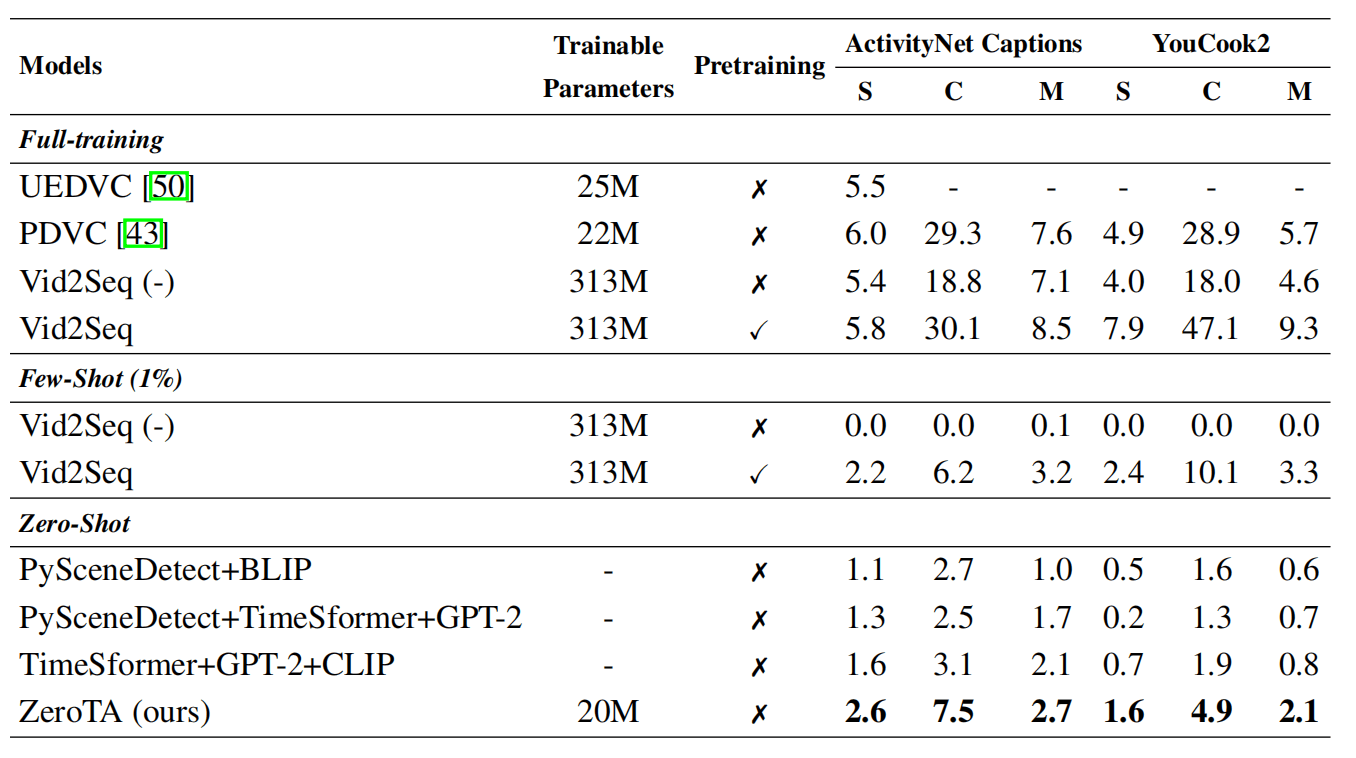
在两个数据集上结果如表所示,由于缺乏对比,构建了几个baseline。
PySceneDetect是一个检测视频场景的库,可以将视频以不同方法来分割出不同场景,+BLIP就是用预训练的image caption模型来生成caption,TimeSformer+GPT-2是用一个预训练的Video Caption模型,而TimeSformer+GPT-2+CLIP则是使用之前那个预训练模型来通过beam search为整个视频生成多个caption,然后用CLIP对帧进行匹配,找到caption对应的范围。
三个baseline都比较简略,ZeroTA也是轻松超过,对于监督训练的模型是必然比不上,对于1%的few-shot模型则有比较性。
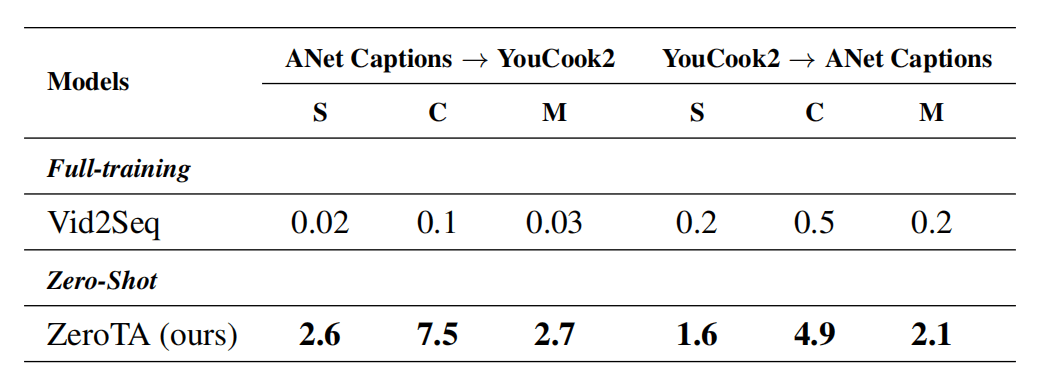
这个表则是看跨域的表现,Vid2Seq跨域表现很差,ZeroTA则跨域没什么问题,指标都是一样的低hhhhh。
实验还发现CLIP和GPT越大越好,video embedding也是越多越好,注意这个文章是把平均后的向量映射为固定个数的video embedding。但是实际上这个与没有相比,没有特别多的增加。

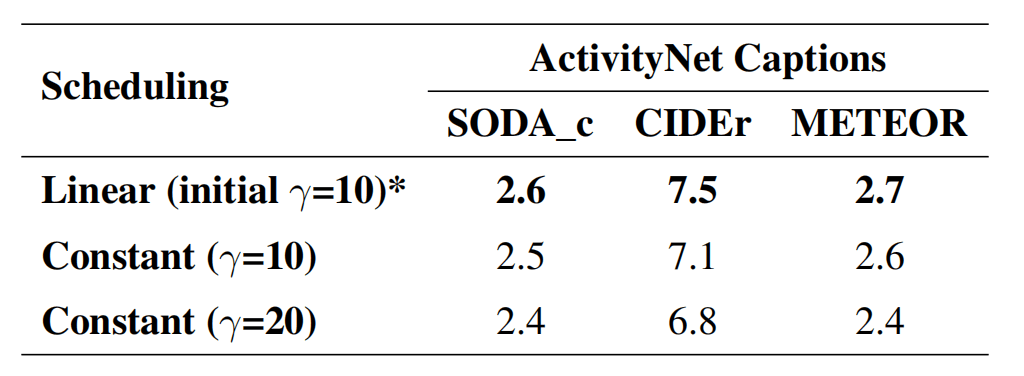
下表对于的调节影响还更高一些。
定性分析如下

总结
这篇文章主要价值在于把之前那个团队的zero-shot captioning的方法延申到了dense video captioning上,感觉没有那么惊艳,效果也不是很好评价,这个SODA_c指标不太了解,C和M则被之前的论文证明是不太适用于这种zero-shot的模型的,假如我是审稿人,我会更希望它加入更多的指标,反正也不需要训练嘛。此外,评价指标上事件定位的精度貌似没有体现。
架构上,这个video embedding的加入会显得比较奇怪,算是增加了比较多的参数,但是效果有没有那么好。
三篇文章的总结
发表在CVPR的ZeroCap比较惊艳,到2023.9已经有77个引用了,很多也是沿着这个方向的改进模型,感觉这个方向是有发展的潜力的。
目前限制反而可能出现在评价上,因为评价zero-shot不能用平常的那些指标,其它的指标又有各种各样的,没有统一。
前两篇文章主要说的是方法,没有体现LM和CLIP进行scale的结果,第三篇也只是做了简单的消融,目前CLIP可以到Huge级别,LM则可以更大了,既然不用训练,那我比较期待在那上面的结果。对于多模态的LLM,这可能是一个新的解决方法。
多轮迭代的方式是一个比较好的设计,在实际应用中会比较好,可以在算力和性能间权衡。可不可以把这种方式与监督学习的方式进行融合呢?
这种方式对词表没什么限制,可以进行更多语言的captioning。
目前在图像上的研究比较好一些,在视频就要考虑时序等信息,会比较复杂,很难做zero-shot。
ZeroCap可以对CLIP embedding空间中的任意点进行解释,那理论上,新出的ImageBind也是可以用这个方法来加入更多的模态的!
对于调整参数,第一篇是中间的K、V进行调整,后两篇则是prefix,那么可不可以用其它adapter的方式呢?
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!