论文笔记 Towards Video Anomaly Retrieval from Video Anomaly Detection:New Benchmarks and Model
本文最后更新于:2023年7月28日 下午
论文笔记 Towards Video Anomaly Retrieval from Video Anomaly Detection:New Benchmarks and Model
论文链接:Towards Video Anomaly Retrieval from Video Anomaly Detection: New Benchmarks and Model (arxiv.org)
代码链接:待开源?
中国西北工业大学的Arxiv预印期刊论文(2023.7.24),提出了Video Anomaly Retrieval这个新任务,旨在进行文本-视频检索和音频-视频检索,对应两个数据集UCFCrime-AR和XDViolence-AR,并提出了一个ALAN模型作为baseline。
Video Anomaly Retrieval(VAR)任务

如上图所示,VAR任务使用一个文本或者音频对视频进行检索,乍一看与Video Retrieval(VR)任务没什么区别,但VAR的特点在于被检索的视频①长度可能非常长 ②可能包含需要关注的异常事件。
传统视频检索任务使用DiDeMo、MSR-VTT等数据集,视频已经切分成小片段,文本和视频内容设计范围比较广。对于长视频则视频检索模型一般没办法,会有另外的Video Moment Retrieval任务,这个任务则是检索出长视频中符合文本描述的一段。而VAR的粒度不及Video Moment Retrieval,但是检索对象却是长视频。
同时,VAR更关注异常情况的检索,比如撞车、爆炸、斗殴等,但是也能支持普通文本的检索,这一点论文没有强调。
下图是更详细的不同任务的对比。

VAR Benchmarks
作者构建了UCFCrime-AR和XDViolence-AR两个Benchmark,UCF-Crime和XD-Violence都是VAD中常用的数据集,前者有1900个视频和video级别的标注,后者有4700+视频和对应video级别的标注。
UCFCrime-AR是一个文本-视频的检索数据集,作者找了8个人标记了UCF-Crime的视频的中英文caption。XDViolence-AR是一个音频-视频的检索数据集,作者就是用了其音频来作为query。
ALAN模型
作者提出了Anomaly-Led Alignment Network(ALAN)来进行VAR的任务,其整体架构如下:
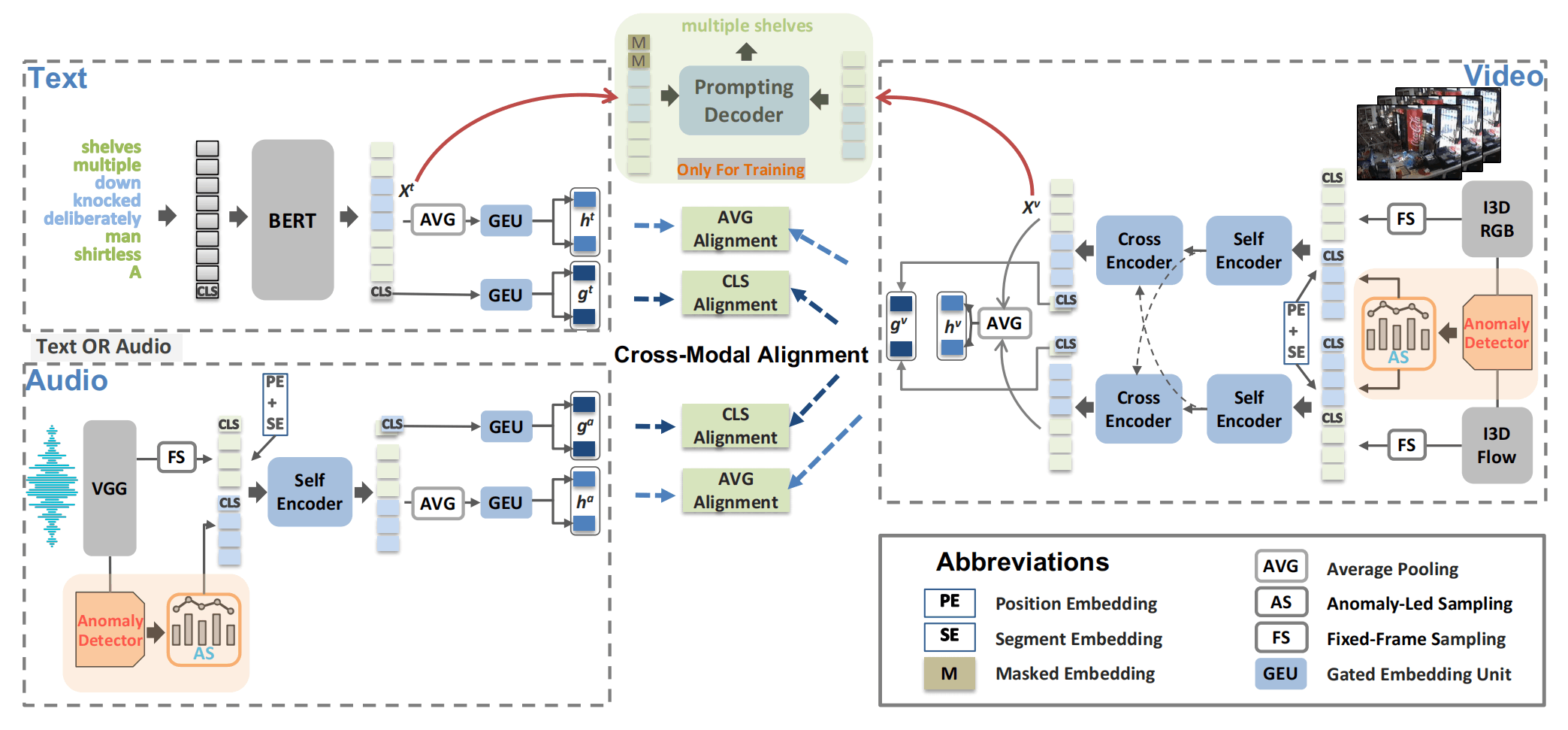
视频包含RGB和光流两个模态,分别用I3D-RGB和I3D-Flow提取,音频则使用VGGish提取,文本使用BERT提取。
视频和音频的处理逻辑类似,作者提出了Anomaly-Led Sampling(AS)和Fixed-Frame Sampling(FS)两种采样方法,前者通过一个VAD模型来找到视频异常的片段,并提升在其中采样关键帧的概率,后者就是普通的等间隔采样。帧会添加[CLS]、位置编码、区分模态的编码,然后通过Transformer进行模态融合或者进一步的编码,最后得到[CLS]的特征以及平均池化所有token的全局特征。
文本对应的也会得到[CLS]的特征以及平均池化所有token的全局特征。
这里两种都算全局特征,只是通过不同的方式得到,AS的具体采样方法见下图Algorithm 1.

VAD模型是3层时序卷积层,最后使用Sigmoid得到每一帧的分数。
训练loss分为三部分:①模态对齐 ②VAD ③掩码语言建模
-
模态对齐
最小化之前得到的全局特征之间的余弦相似度,会通过网络预测不同模态相似度的权重来进行融合,文本和音频额外使用GEU来得到“两种模态”的特征。两种global的特征通过超参数融合。batch内使用双向max-margin ranking loss。
视频有RGB和Flow的全局特征,在计算模态对齐的视频需要文本和音频也有对应的两个全局特征,但是没有,所以通过GEU来一生二,得到两种特征。
-
VAD
弱监督的训练方法,模型预测帧级别的异常分数,取top-k作为视频级别异常分数,然后使用视频级别的标签进行优化。
-
掩码语言建模
通过Spacy分析句子中的动词短语和名词短语,mask掉,然后重构。
整体来说,ALAN的模型包含了一个BERT、一个Prompting Decoder、多个Self-Attention和Cross-Attention、多个GEU、两个VAD模型。论文没有给出参数量,但是感觉还是挺多的(论文说BERT的参数不冻结)。论文最后说一个pair的检索时间是0.008s,在UCF和XD的测试上一次检索都只用2.7s和5.6s,这个效率也太高了吧,我觉得得打个问号,这个肯定是没有包含VGGish和I3D的。
实验
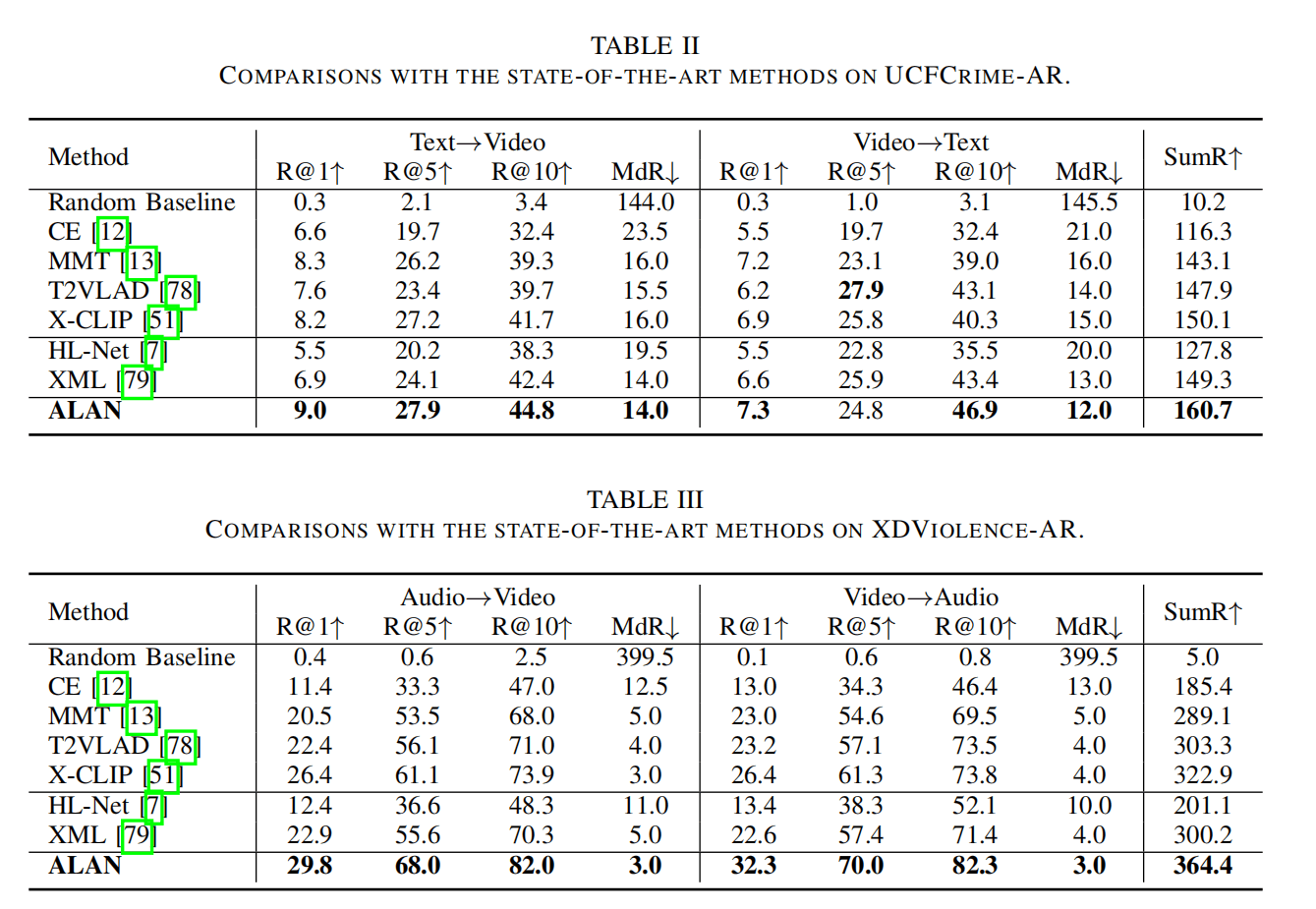
上图第一栏(CE到X-CLIP)是视频检索模型;第二栏的HL-Net是VAD模型,使用ALAN的框架,只是利用了其Video Encoder,而XML则是Video moment retrieval模型,但是不使用其时序定位的模块。
结果证明ALAN效果最好,与其最接近的是X-CLIP,提升还挺多。
实际应用中,应该更关注的是Text->Video的任务,不是很清楚Audio<–>Video的使用场景,从这个角度看,X-CLIP和ALAN差距不是特别大。
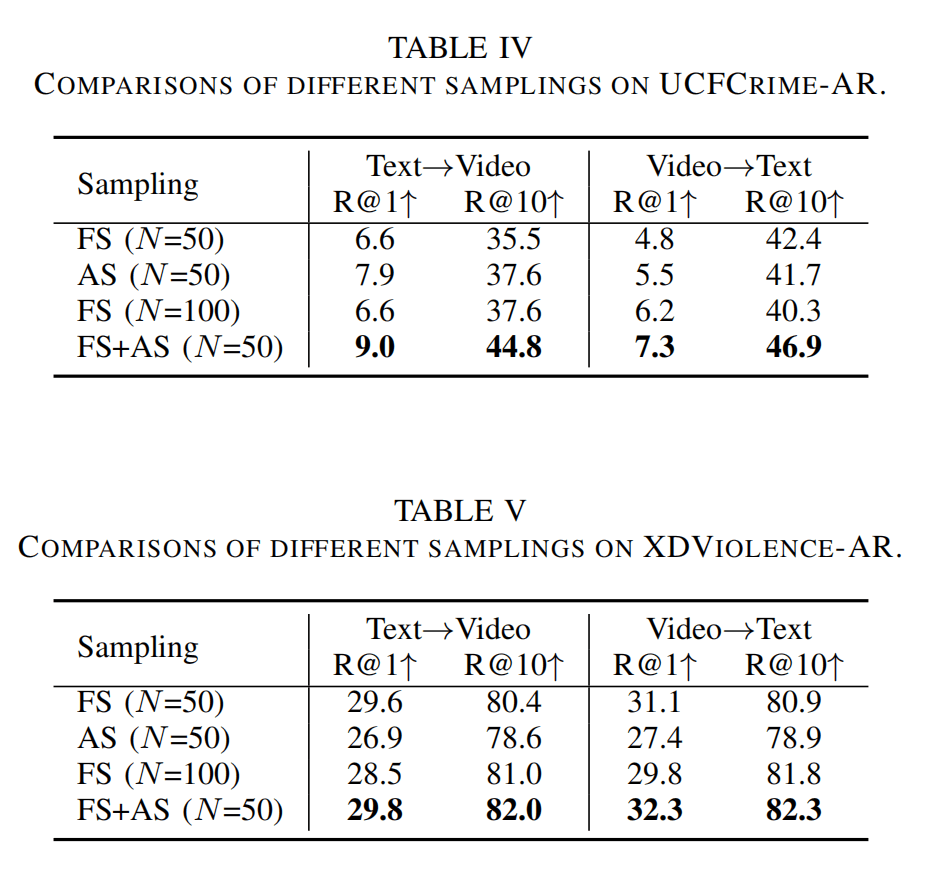
上图是不同采样方法的比较,发现AS+FS能显著增加性能,并且在UCF-Crime上更明显。

对于掩码语言建模任务的加入,掩码特定词的效果更好,而掩码特定短语的效果最好。
作者说掩码短语在4个指标上有3个指标领先所以更好,但是假如更关注Text->Video的话,应该是掩码单词效果更好呢……这个消融实验对我不是特别有说服力
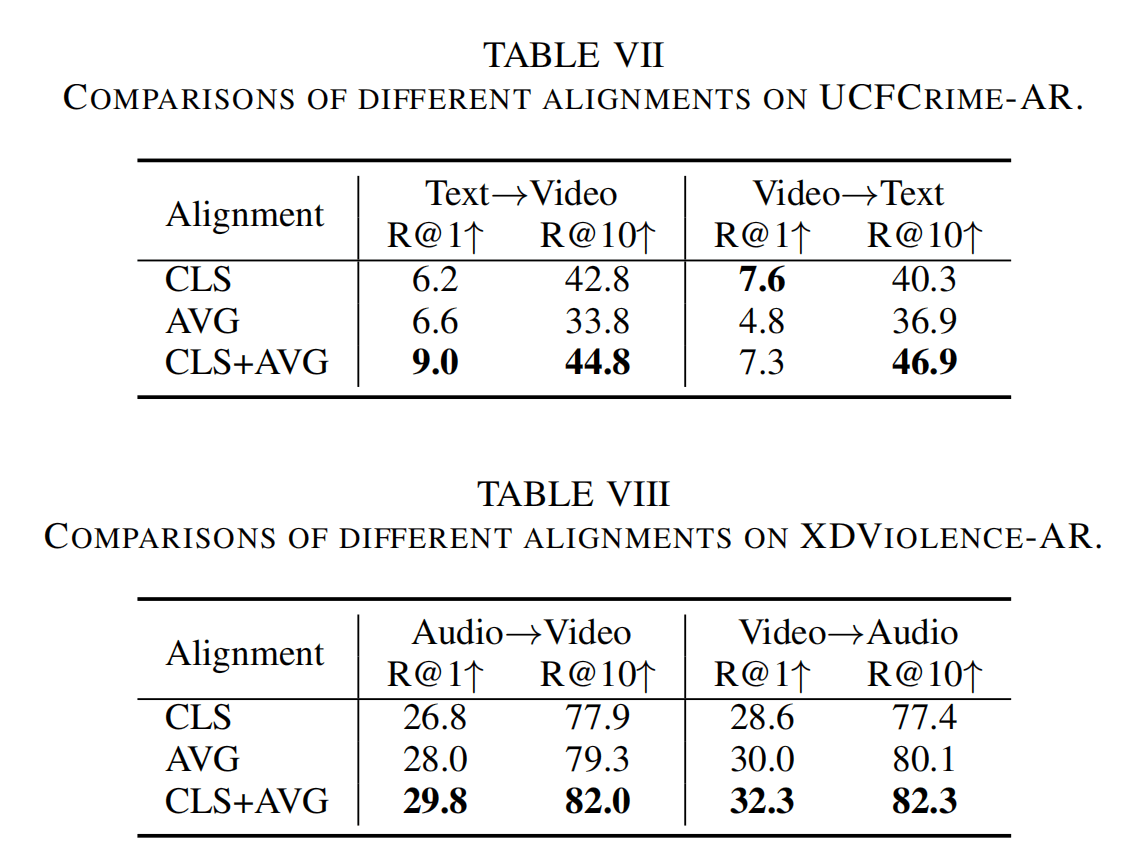
作者对使用两种全局特征的方法进行消融,也有对应比较显著的提升。
还有一个loss超参数的融合就不放出来了,下面是一些可视化的分析:

图5是query检索出来的top-3的视频,效果还是不错的,最右边的是正常的检索,发现也有效果。

图7则是一些简单的单词的检索结果,也有效果。
但是这里也许可以定量分析而不只是可视化?比如通过“Explosion”来检索所有视频,根据分类标签统计召回率什么的。因为实际情况的query text可能就是偏简单的。假如有定量分析会更好一些。
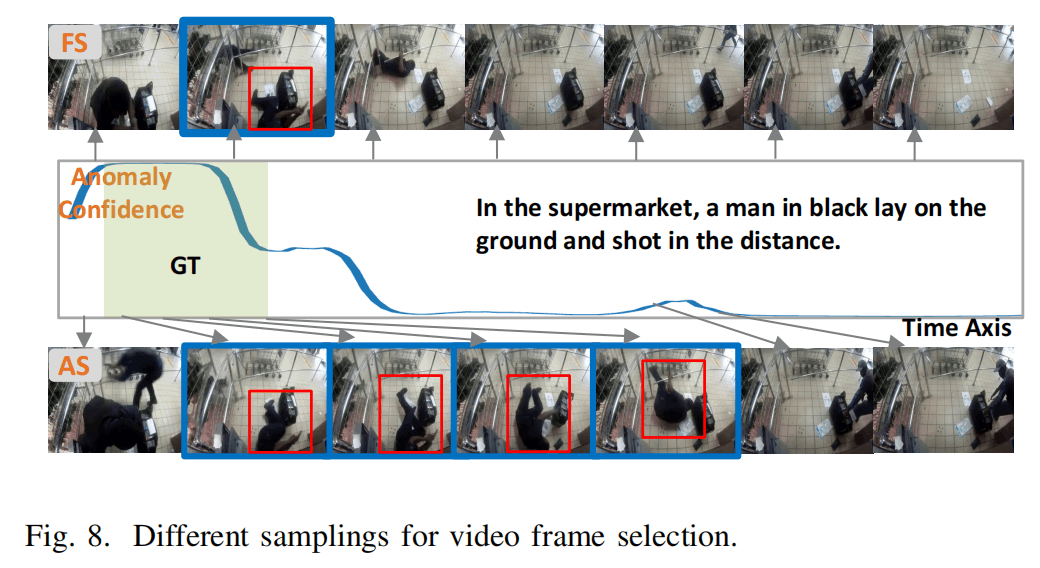
图8是异常检测的效果和对应的采样方式示意。

图9是跨数据集的zero-shot的结果,使用UCF-Crime的文本来检索XD的视频,得到了还不错的结果。
为啥用UCF-Crime的文本?可以直接人工标10+个XD的视频,然后检索看看泛化性能呀。
结论
整体有一定的新意,也许需要带一下这个技术的实际应用场景。实际上和视频检索相比,只要解决了长视频的处理方法,差别也不是特别大,并且实验看上去本文也没有领先太多。
弄了新的benchmark应该开源的……24号挂上来的,现在28号,也可能是我看得太早了,不过论文里丝毫没有提到要开源的迹象……这个不开源的话,可信度都得打个问号。
模型的细节没有说清楚,比如说各个模块的层数、总参数量、冻结哪部分的参数、测试时间运行在什么机器上、用什么配置运行的,期待补充材料。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!