MultiCapCLIP Auto-Encoding Prompts for Zero-Shot Multilingual Visual Captioning
本文最后更新于:2023年10月24日 上午
MultiCapCLIP: Auto-Encoding Prompts for Zero-Shot Multilingual Visual Captioning
论文链接:2023.acl-long.664
北大和鹏城实验室在ACL2023发表的一篇论文,介绍了一种zero-shot的多语言Captioning的方法(MultiCapCLIP),其训练时使用目标域的文本语料进行重构式的训练,预测时将输入直接替换为图片,就可以生成Caption。
接下来介绍其方法:
方法
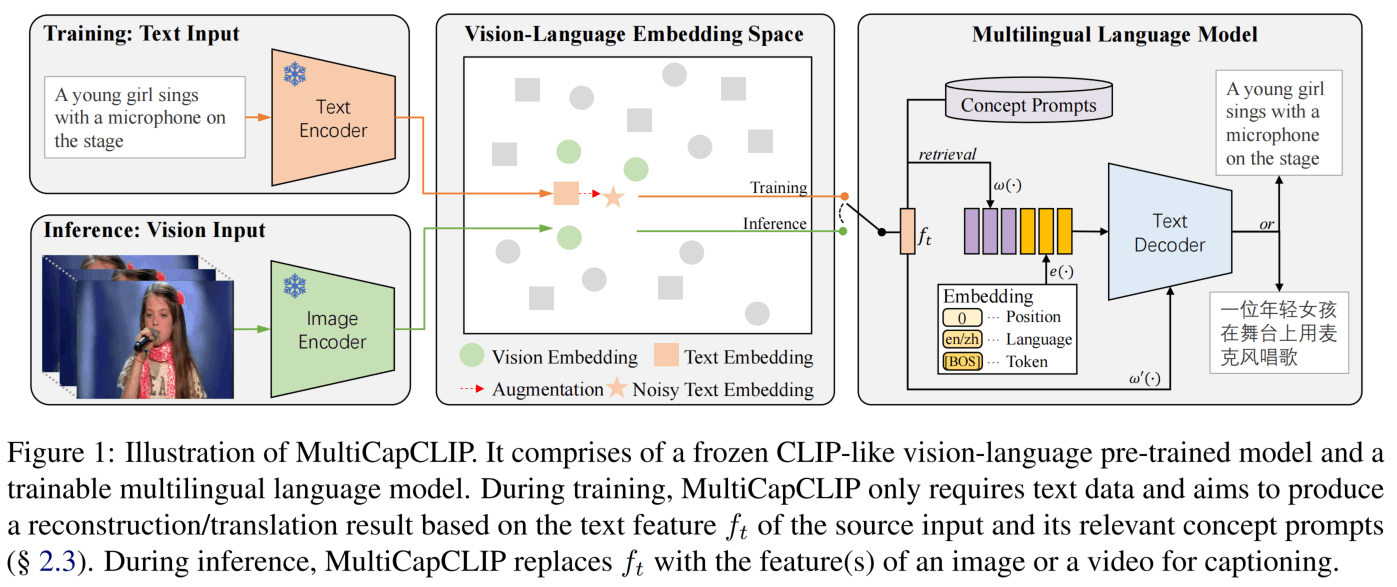
图1是MultiCapCLIP的架构,训练时进行的流程,是一种auto-encoding,其中S是文本域,P是视觉概念域,预测时则进行,其中V是视觉域。
首先,对于一个语料库,作者使用spaCy提取文本最常见的1000个名词组成visual concepts,然后不用prompt直接使用CLIP获取其embedding,得到。
训练时,对于一句话,提取CLIP特征为,然后获取距离最近的K个visual concept为,经过映射维度作为Text Decoder的前一部分输入。第二部分输入则是prompt加上位置编码和语言编码。同时还会通过交叉注意力参与Text Decoder的解码。
预测时,把改成图像的embedding就可以。
为了更好的效果,作者还进行了augmentation。因为在Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning论文中指出视觉和语言在CLIP的空间中仍然是具有modality gap的,所以作者进行了input augmentation(IA)和feature augmentation(FA)两方面来提升泛化性。
IA就是把输入的句子S随机替换为语料库中最相近的N个句子之一,FA则是在上添加一个高斯噪声。
实验
实验在图像和视频的Caption数据集上进行(MS-COCO、MSR-VTT、VATEX-CN)
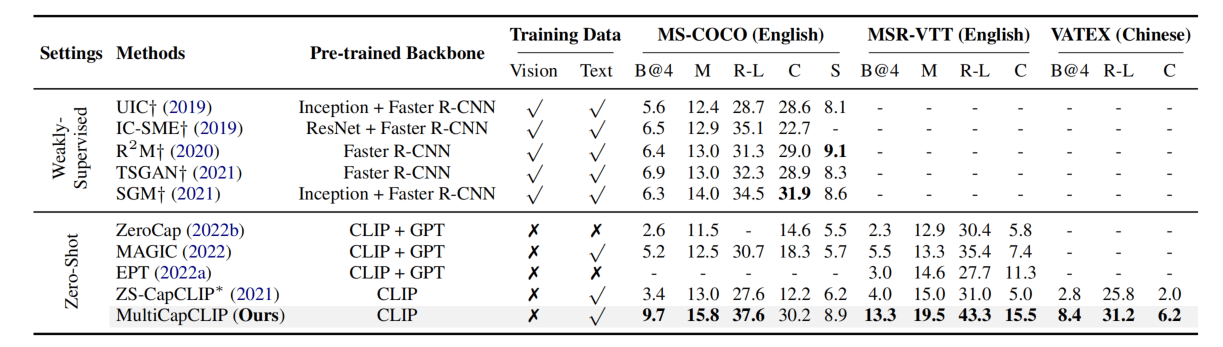
通过比较可知Zero-shot的方法普遍是比不过弱监督的,但是MultiCapCLIP却有很大的提升。Zero-Shot方面本文方法也超过了之前介绍的ZeroCap,毕竟人家没有用文本数据来训练。同样只使用文本,这篇论文方法超过了MAGIC。同时,在中文数据集上没什么可以比较的,但是比他们自己构建的Baseline还是高。
然而,这里用的都是监督的指标,在Zero-shot方面可能使用无监督的指标(BERT-Score、CLIP-Score)也会有一些参考价值。
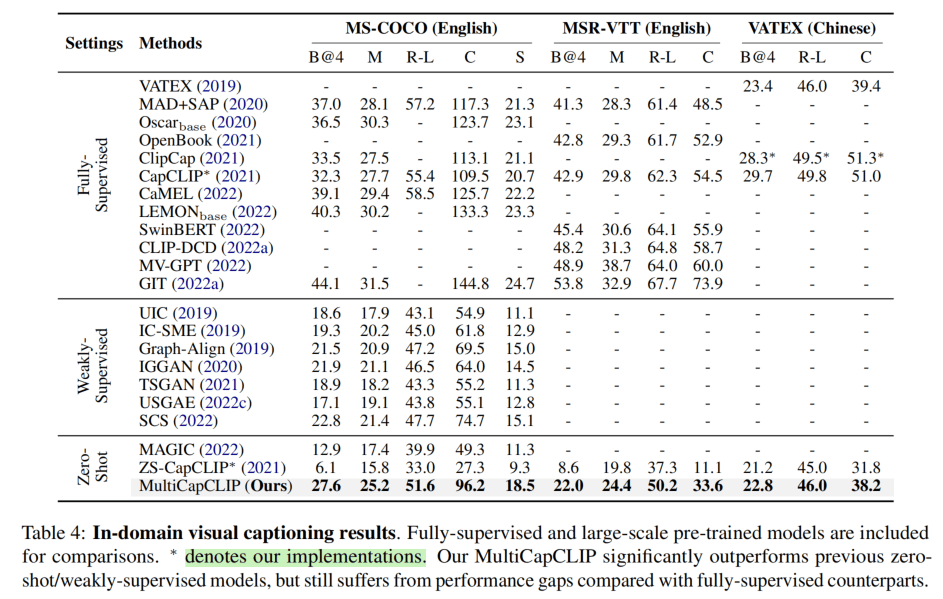
上表则是In-Domain的比较,即使用了语料库和图像库进行训练,但是没有利用其配对信息。在COCO的CIDEr上达到了96.2,已经是非常不错的成绩了,但是距离监督的还有很大差距。MSR-VTT的CIDEr也是有差距。中文的VATEX上达到了19年的监督学习的Baseline水平。
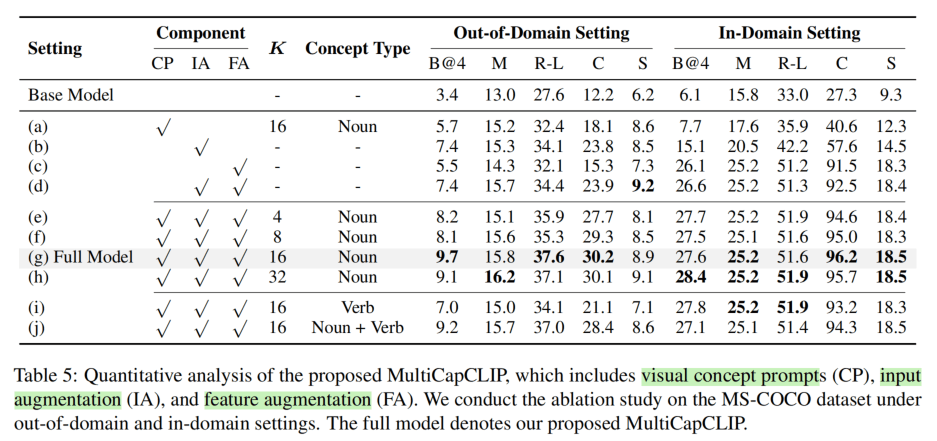
消融实验可以发现在Out-of-Domain中,单独使用FA的效果很差,结合以后则更好。动词的概念没有单独用名词概念好。

定性实验如上,concept的识别还是比较准确,但是感觉动词都是根据名词概念脑补出来的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!