论文笔记 OvarNet:Towards Open-vocabulary Object Attribute Recognition
本文最后更新于:2023年7月28日 下午
论文笔记 OvarNet:Towards Open-vocabulary Object Attribute Recognition
论文链接:OvarNet: Towards Open-vocabulary Object Attribute Recognition (arxiv.org)
代码链接:KyanChen/OvarNet (github.com)
项目主页:OvarNet: Towards Open-vocabulary Object Attribute Recognition (kyanchen.github.io)
北航、小红书和上交联合做的Open-vocabulary目标属性识别,提出了OvarNet模型,该模型能够检测任意目标以及其任意属性。由于目前缺少拥有足够标记的数据集,其采用了一种federated策略来组合多个数据集并得到能够获取属性语义的CLIP模型,同时还能够利用image-caption pairs。
这个新任务同时进行object detect和attribute recognition,并且是以open-vocabulary的形式进行的。如下图,第一行左边四张是经典的闭集目标检测,右边四张是闭集属性识别,而下面一行就是这篇文章提出的OAR,其中蓝色的是数据集外的标签。

Method
OvarNet的训练分成了三个阶段:
- 训练一个普通的二阶段的open-vocabulary模型,使用offline的RPN提出区域proposal,然后进行分类和属性识别,此处得到一个CLIP-Attr模型。
- 组合多个数据源,进行federated strategy来微调CLIP模型。
- 为了提升效率,通过知识蒸馏训练一种Faster-RCNN类型的端到端的模型。
第一阶段
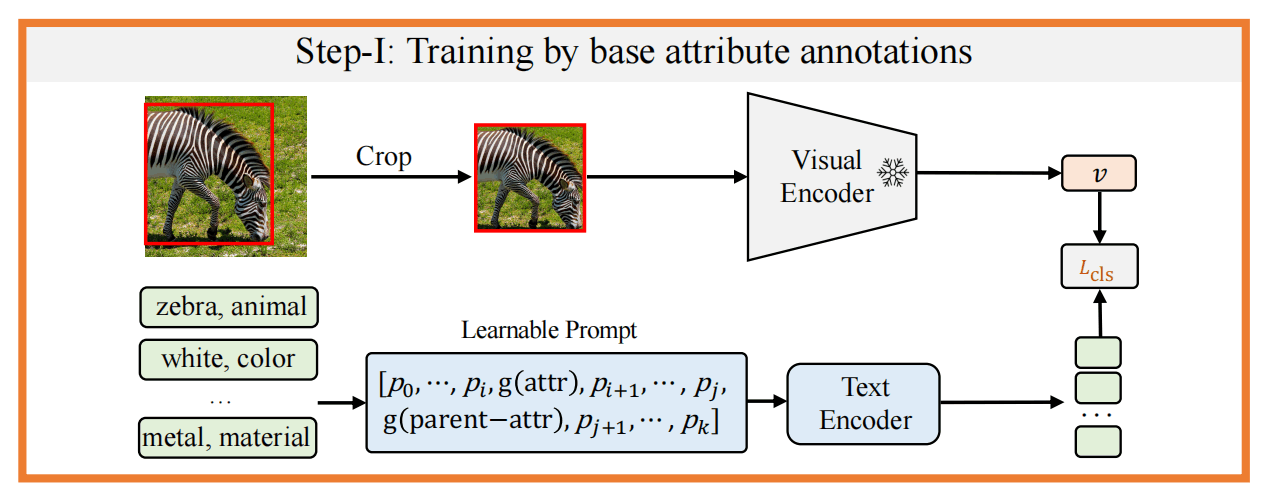
使用已有的COCO base categories得到一个offline的RPN网络,能够提出类别无关的proposal,然后在原图上将区域crop出来,经过CLIP图像编码器编码得到其视觉embedding。
文本端使用属性为数据源,并添加其在语言上的父级类别和learnable token作为prompt,经过文本编码器得到文本embedding。
将区域视觉embedding和属性文本embedding计算相似度进行属性识别。
第一阶段,由于缺少同时拥有bounding box、attribute、categorie的数据集,就合并使用目标检测和属性识别的数据集,来微调一个对属性敏感的CLIP Text Encoder。
第二阶段
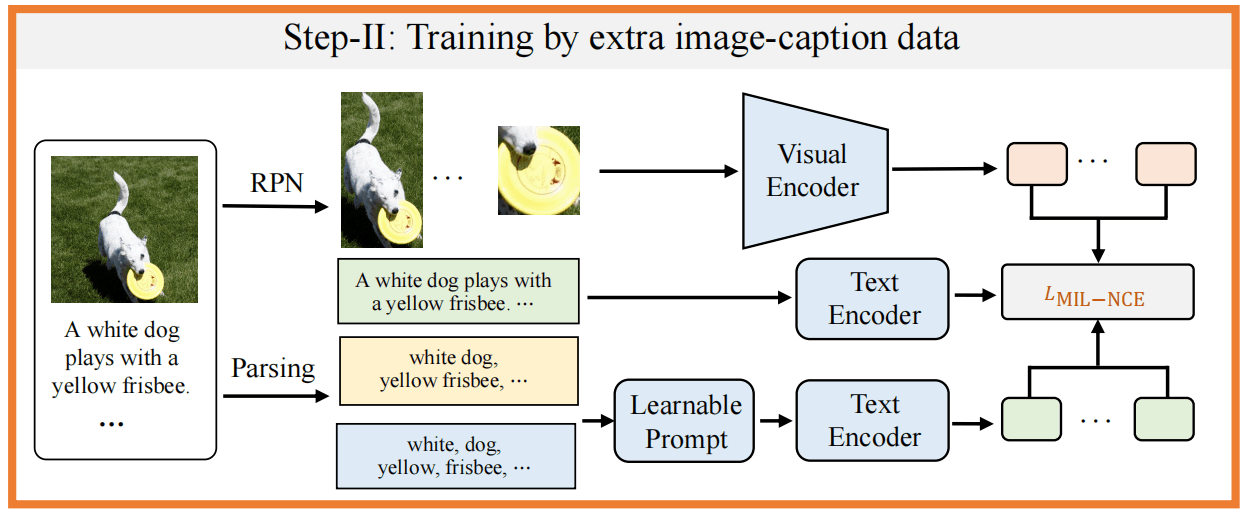
第二阶段开始利用image-caption的数据,使用RPN网络得到proposal,保留最大的框和top-K个得分的框,并将原图根据此裁剪再送入视觉编码器,使用第一阶段的模型来得到pseudo-postive标注。
对于caption,使用TextBlob工具分析句法得到类别、属性和名词。
这一阶段使用MIL-NCE作为损失函数:
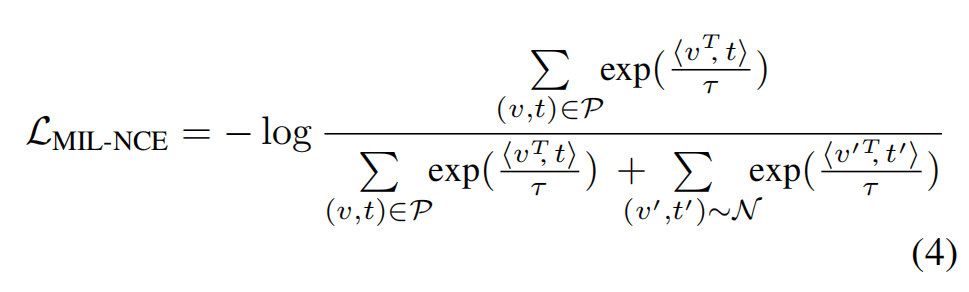
其中,最大的框和caption作为正例,top-k的框与解析出来的类别和属性作为正例。
这一阶段微调Visual Encoder和Text Encoder。
第三阶段
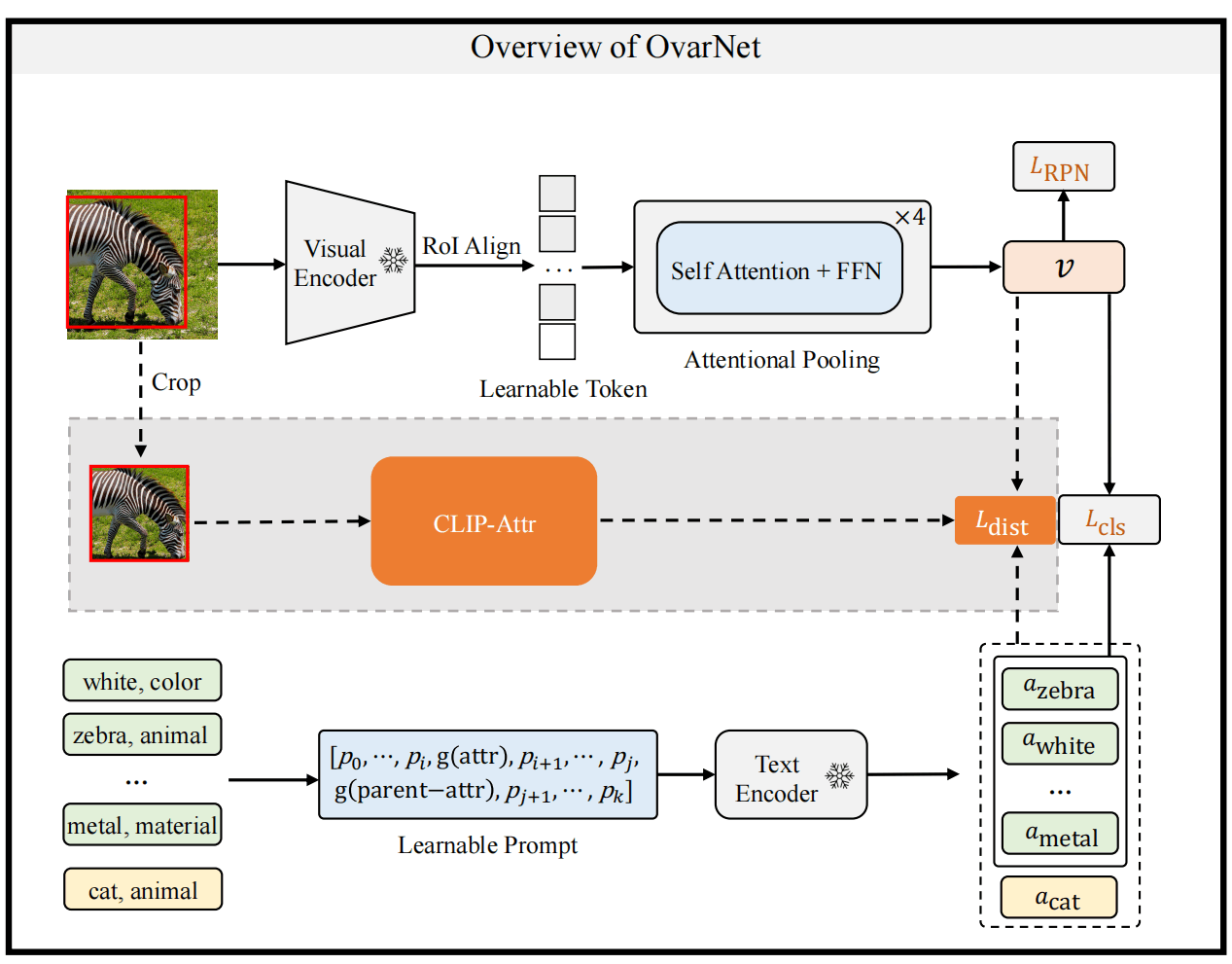
由于前两个阶段要使用RPN得到区域,然后还要分别送入视觉编码器提特征,太麻烦了,所以这里蒸馏一个一步到位的模型。即提取一次整体特征,然后使用RoI Align得到proposal的特征,经过编码之后作为视觉特征。
训练的时候使用第二阶段训练好的模型作为teacher,来指导一步的模型生成较好的proposal。另一路还是用Text Encoder来做open-vocabulary的匹配。
实验
这里简要介绍其实验。
数据集使用COCO(目标检测)、VAW(属性检测)、CC3M、COCO-Cap(图像-文本对)、LSA(包含图像、目标框、属性,来自VG等数据集)
评测基于LSA、OVAD(人工标注仅测试集的benchmark)
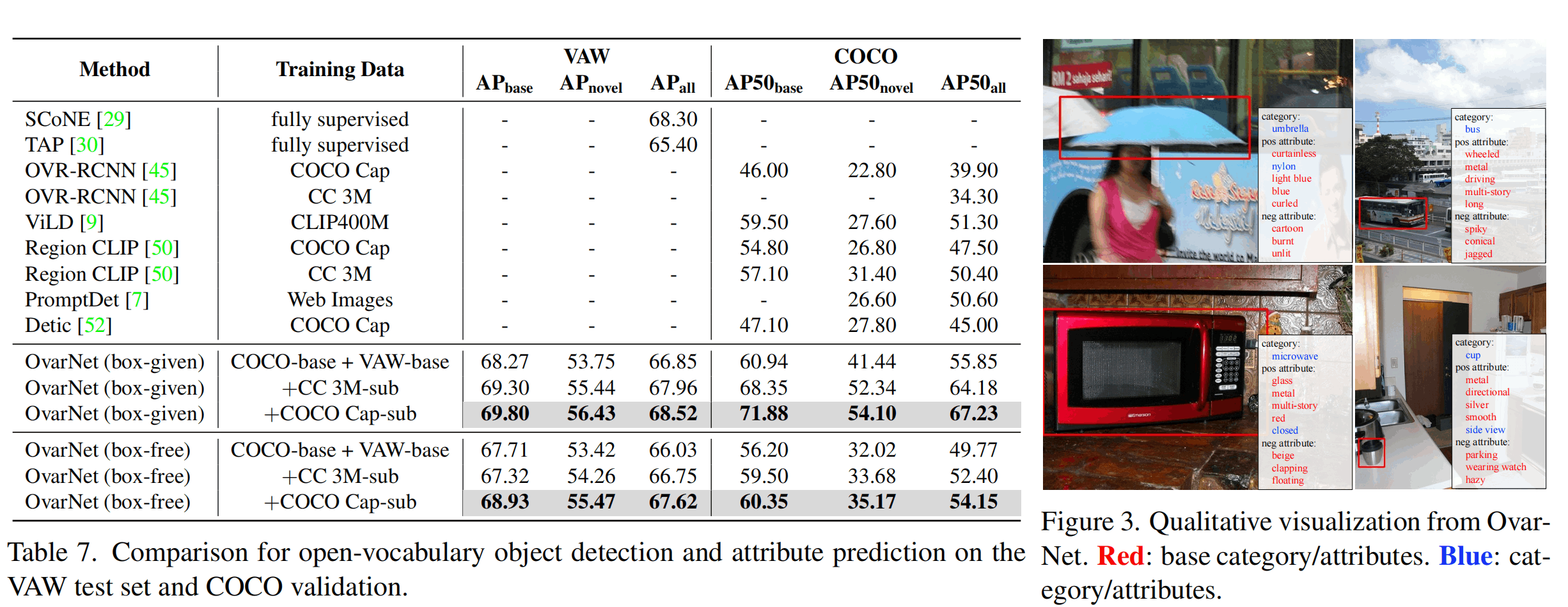
放一个与sota比较的表,其他实验和细节请看原文呢。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!