论文笔记 Semantic-SAM:Segment and Recognize Anything at Any Granularity
本文最后更新于:2023年7月20日 下午
论文笔记 Semantic-SAM: Segment and Recognize Anything at Any Granularity
论文链接:Arxiv
香港科技大学6月挂在Arxiv上的一篇文章,使用SAM的数据集和思想,构建了一个能够分割更多种粒度的模型Semantic-SAM。模型主要贡献是能够感知语义且能够提供更多的粒度。

Semantic-SAM
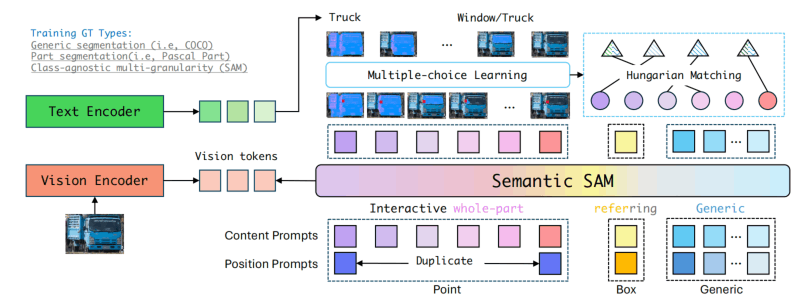
如上图所示,Semantic是一个query-based的模型,支持point、box、generic作为query。
与SAM不一样的是,point和box使用了统一的格式,即一个点会被看作是宽和高都非常小的box。
对于point,同一个point会被复制9次,赋予9种粒度的embedding和表示query种类的type embedding作为content prompts,point位置则会使用无参数的position encoding得到position prompts。
对于box,不区分粒度,对box添加一些噪声之后作为prompts,然后加上一个type embedding作为content prompt。
对于generic,使用和Mask DINO一样的流程,即
Mask解码器基于Deformable Decoder,输入query、reference box和image features,得到query output feature。
输出的query feature会分类得到semantic category和mask,用来进行recognition loss和mask prediction loss。
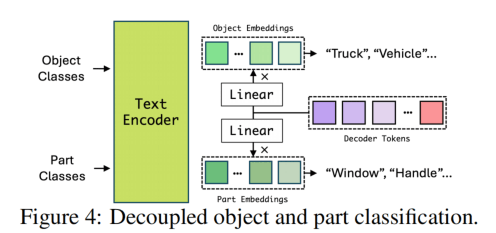
类别会通过两种Linear层得到两种粒度的embedding,一种是part的另一种是object的,两种分类其实是不同的分发所以是用两个Linear。
Part Segmentation
标注一个object的部分,比如人的头、左手、右手、身体,这些“部分”可能在不同object之间是通用的,比如鸟、鱼、自行车都有Head、Body。
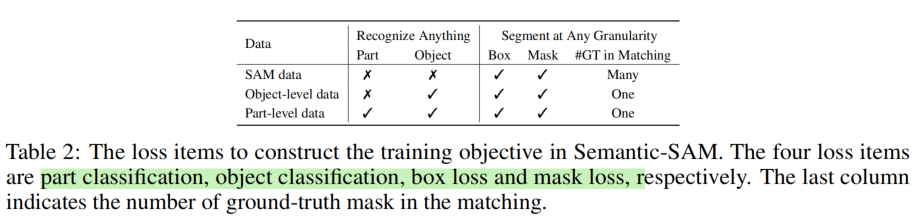
这里只对有标签的数据训练,没有标签的SAM-1B的数据就不适用这个loss。多粒度Mask预测时,使用Hungarian算法来进行多对多的匹配。
每种数据的loss具体如下,
模型细节:视觉预训练模型使用Swin-T/L,语言编码器使用UniCL(不太熟悉,但是是类似CLIP的),图像分辨率使用。
实验
和SAM原文的建议一样,使用了1/10的SA-1B,获得了比其他都更好的成绩。
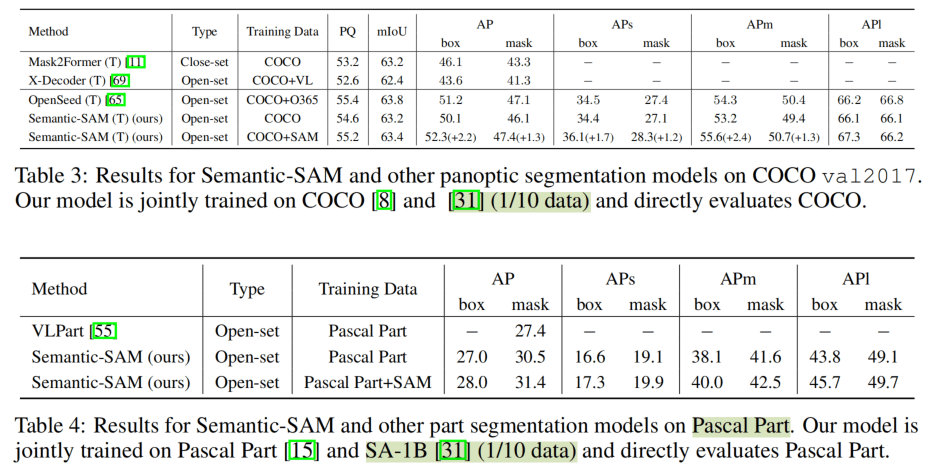
这里和SAM使用同样的setting进行比较,效果更好(但是两者用的视觉backbone是不一样的)。
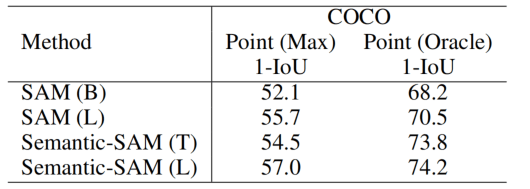
使用SA-1B的一个子集进行验证,使用一个point来得到多种粒度,然后匹配GT中最接近的,计算IoU。因为SAM只有3个粒度,所以要得到6个粒度就给了两个点。这里必然是Semantic-SAM的效果更好,因为做了Many-to-Many的训练。

对于Match,消融实验发现Many-to-Many贡献对于粒度的指标贡献很大。也是意料之中。

但是假如做many-to-one,这个指标降到了73.2,和SAM比差了很多呀
结论
Arxiv上这篇论文给的细节不够多,毕竟没有被review过,一些地方有笔误,叫SAM主要是借鉴了任务和数据,没有借鉴模型,然而这个模型肯定是比SAM要大很多的,SAM解码器就是两层。没有眼前一亮的感觉,等待时间验证吧。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!