论文笔记 Deformable ConvNet v1+v2+DETR
本文最后更新于:2023年7月20日 上午
论文笔记 Deformable ConvNet v1+v2+DETR
- 【ICCV 2017】Deformable Convolutional Networks:ICCV 2017 Open Access Repository (thecvf.com)
- 【CVPR 2019】Deformable ConvNets V2:CVPR 2019 Open Access Repository (thecvf.com)
- 【ICLR 2021 Oral】Deformable DETR:Deformable DETR: Deformable Transformers for End-to-End Object Detection (arxiv.org)
最近看到Deformable attention越来越多,于是关注到了Deformable这个东西,本文从起源开始介绍三篇经典的CV相关使用Deformable的论文。文本只介绍其方法,对实验和背景不展开过多的叙述。
Deformable ConvNets
CNN的卷积核是固定的,具有局限性,对于长距离的建模也不佳,Deformable ConvNets则是一种新的网络架构,能够实现变形的卷积。
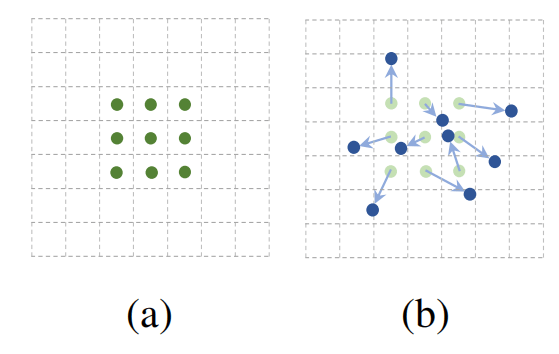
如下图所示,(a)是传统的卷积操作,拥有一个的卷积核。(b)是对采样位置进行变形的操作,原来的绿点通过施加offsets偏移到了蓝点,从而得到了变形卷积的雏形。
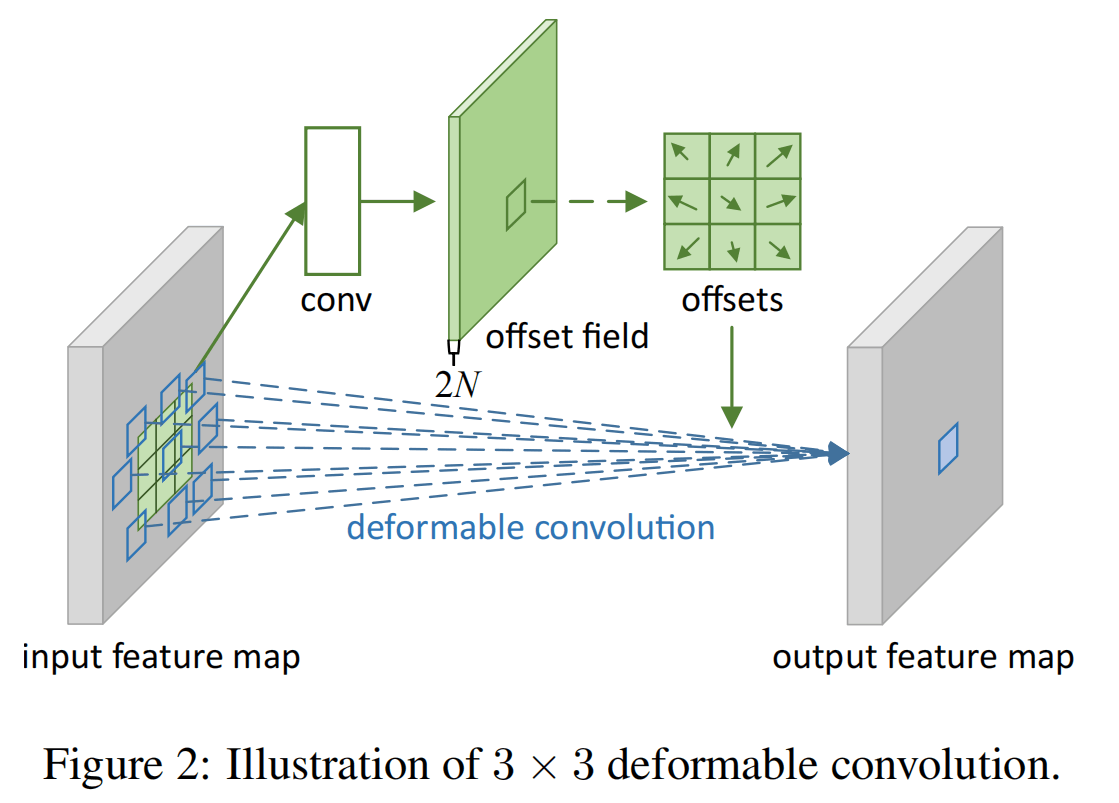
上图是一个的Deformable Conv的架构,和卷积类似,变形卷积也是在输入特征图上使用一个滑动窗口,每个窗口得到输出特征图上的一个值。变形卷积首先会初始化一组采样点:
对于输出特征图上的每一个位置,使用下面这个公式:
是包括自身的周围9个位置,而则是进一步的变形offset,有了这个offset,采样的点就会变到别的位置上而不是一个方框。
公式中是每个点对应的可学习的权重,则是取出某个(小数)位置上的值,这个值需要通过bilinear interpolation来得到。
就如图所示,是通过一个卷积操作得到的,图中指的是卷积核的大小(),由于有两个偏移方向,所以要得到的深度。
论文还提出了Deformable RoI pooling,基本上类似,就是在RoI pooling的每一个bin中使用变形卷积来得到值而非简单的平均。
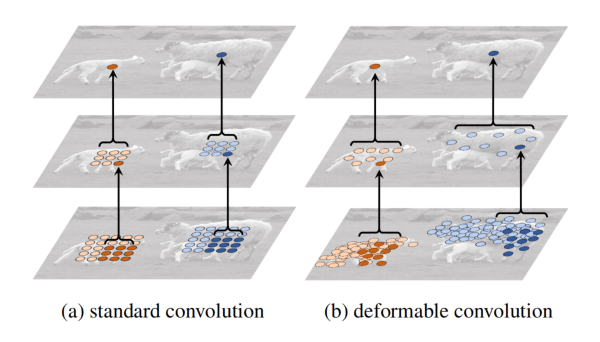

使用变形卷积,可以如上图得到变形的感受野,同时可视化效果也很不错,有一种天生的自底向上的注意力。
Deformable ConvNets V2
作者观察到Deformable Conv很强,所以准备往上面叠更多层,但是发现叠多层之后变形卷积的关注范围又变散了,会超出感兴趣的范围,没有和预料中的那样聚集在一个物体周围。所以,V2还添加了一个调制的操作:
别的都类似,这个就是重点,它控制了变形卷积核在扩散时的权重,其值在,也就是说,一个采样点不会肆意吸取周围点的信息了,假如到了边缘,它的权重可能会降低到0。
的计算方式也很简单,就是把计算时候的2K的深度拓展到3K。
Deformable DETR
从传统注意力到DeformAttn
接下来就把可变形状和现代的Transformer结合起来了。
DETR有收敛慢、受限于分辨率(注意力复杂度高)、对小物体检测效果不好的问题,而Deformable可以进行离散的空间采样,在与DETR结合之后可以构建一个更高效、更适合层级特征的目标检测器。
传统的多头注意力如下:
公式有点不一样,其中是单个维的query特征,是需要关注的所有key特征,是多头注意力的头数,分别是进行注意力时query和key的长度。是融合多个头的输出矩阵,是把key映射为value的矩阵(可能有些奇怪,其实是把被施加注意力的输入映射到value),就是常规的,但是这里简写了这一步骤。
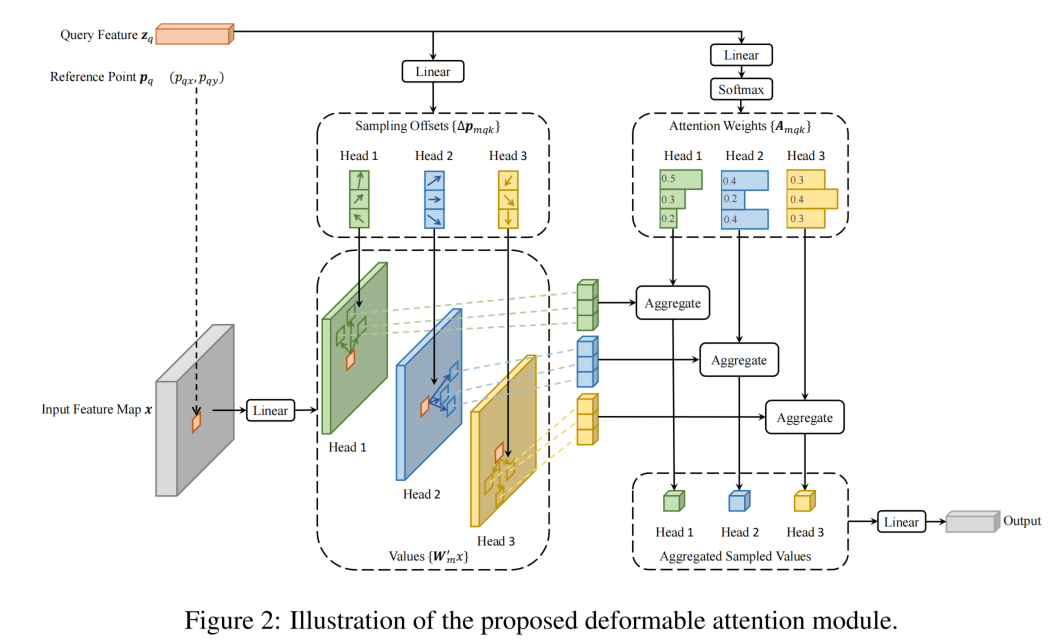
Deformable Attention Module如下:
注意这里的是一个函数,表示取该位置的像素值,不是括号内的乘法。这里把key的范围由限制到了,是一个2d的reference point,是相较于传统的一个额外输入,与query一一对应。而学出来的是从点出来的K个offset(这一点与变形卷积有些不一样)。offset的范围不受限制,可以是短距离也可能是长距离。
会通过一个线性层从映射到维度,即采样点头数(2d偏移量+1d的注意力权重)。注意这里并不是和多头注意力那样通过query乘key得到的,而是直接学习出来的,在K的维度进行归一化。
整体来说,DeformAttn对于每一个query,会使用M个头、选择K个采样点,每个采样点包含与参考点的偏移距离以及对应的归一化权重。
Deformable Attention Module还可以扩展到多尺度版本:
由于有了多尺度,所以参考点是归一化的坐标,把坐标映射到第个尺度的像素坐标,其余都与单尺度版本类似。多尺度版本就是在多个尺度上,以同一个点,每个点预测K个偏移,然后使用归一化的注意力矩阵合并。
DeformAttn for DETR
接下来将其应用到DETR的架构中MSDeformAttn应用到DETR的架构中,首先是编码器:
用作编码器时,输入和输出都是相同分辨率的多尺度特征图,对于每个query pixel,参考点就是本身,为了区分位置和层级,会使用positional encoding和scale-level embedding。
然后是解码器:
解码器中仅交叉注意力会被替换为Deformable,对于每个query,参考点的归一化位置会通过query embedding + linear + sigmoid得到。在最后得到box时,会使用query对应的参考点位置作为box的初始中心,然后额外预测中心的偏移量以及box的宽和高。
Iterative Refinement
实际时Deformable DETR还使用了一些trick,比如这个迭代式的box精细化。
每一层解码器都对中心偏移量和宽高的变化进行预测,首先初始化中心偏移量为第一层通过query embedding得到的中心,宽高初始化为0.1。然后,下一层以这个中心为参考点,得到中心偏移量和宽高的变化量(即相对于0.1的变化量),然后以偏移的中心作为参考点进行再下一层的解码……
Two-Stage
第一阶段从encoder中获得一些region proposal,第二阶段把这些proposal作为初始框来进行Iterative Refinement。
可视化结果
不同box对应的采样点图,看上去……好像也没有那么强的可解释性?

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!