论文笔记 Segment Anything
本文最后更新于:2023年7月19日 上午
论文笔记 Segment Anything
论文链接:Segment Anything (arxiv.org)
代码链接:facebookresearch/segment-anything (github.com)
Demo:Segment Anything | Meta AI (segment-anything.com)
Segment Anything是Meta AI发布的非常火的图像分割相关论文,提出了Segment Anything Model(SAM)模型,开启了图像分割领域的新范式。
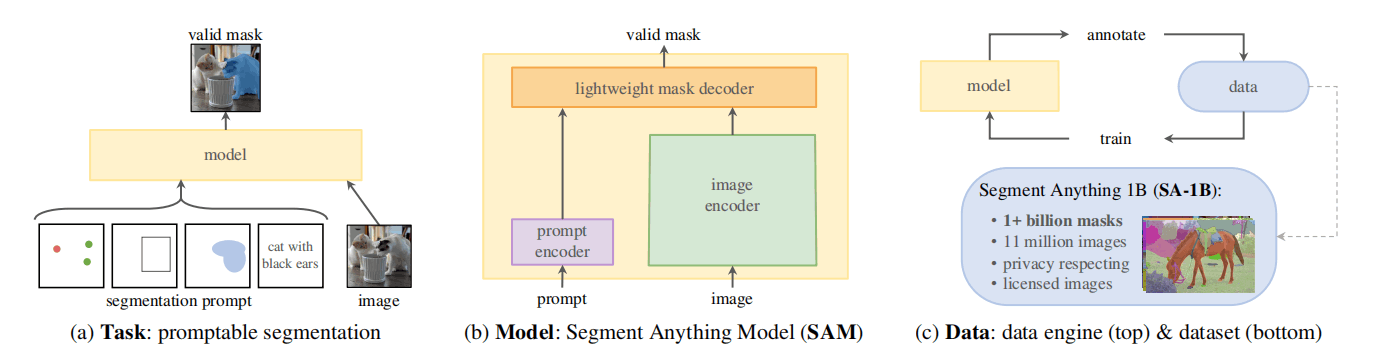
SAM的贡献为上图所示的三点:Task、Model、Data。
- Task:该文章提出了promptable segmentation任务,即输入模型图像和prompt,输出一个和提示相关的有效mask。其中,prompt可以是point、box、mask、text,“有效mask”指的是当prompt的语义较为模糊,无法确定进行segment的粒度,有多种正确的segment mask时,任意一个mask都是有效的。
- Model:SAM模型采用了简洁且灵活的设计,其包含一个较大的图像编码器和一个轻量的解码器和prompt编码器。prompt编码器可以接纳多种prompt格式的输入。而使用“头重脚轻”的架构可以只提取一次特征来进行多次不同prompt的解码任务。
- Data:SAM的训练策略是先训练、再利用训练好的模型辅助标注、再利用标注的数据进行训练。这种循环的训练策略可以在节约人力的情况下,获得高质量的标注。目前有许多方法利用了这种训练策略,关键词为Bootstrap或者self-training。最终SAM通过这种方式构建了一个具有11M图像、1B mask的分割数据集(SA-1B)。
SAM的效果图就不放了,大家都知道它效果多好,接下来介绍其技术细节。
Promptable Segmentation Task

如图,对于一个模糊的point prompt,SAM生成3种粒度的mask,在训练时,模型的输出与最接近的粒度计算损失并回传。
Segment Anything Model
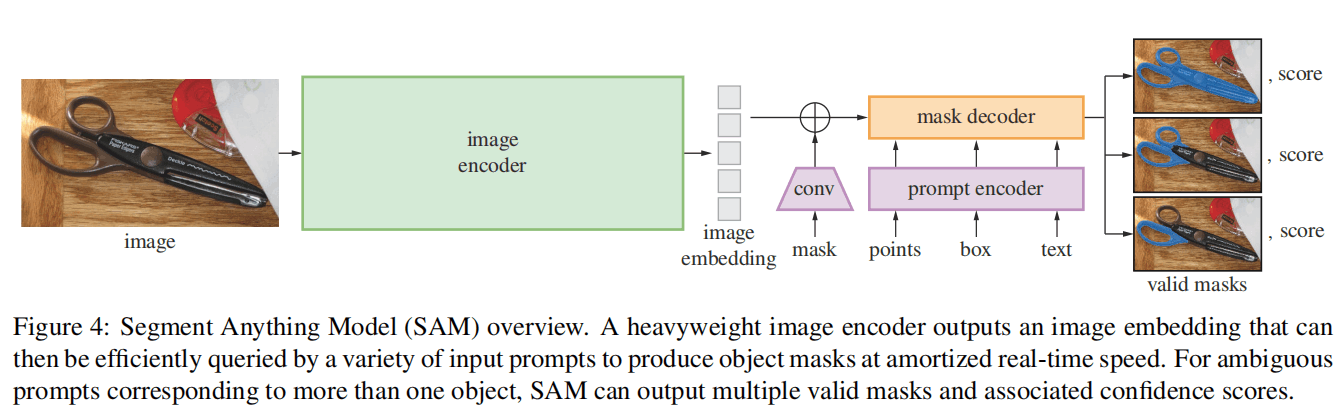
Image Encoder
图像编码器选用了MAE-Huge/16,输入分辨率的图片,得到个patch embedding,并通过和的卷积降低到256通道维度以免数据量过大。
Prompt Encoder
Prompt分为了密集的(mask)和稀疏的(point、box、text)。
密集的mask prompt先通过卷积降低分辨率并匹配通道维度为256,然后再与patch embedding相加。假如没有mask,则一个特殊的[NoMask]embedding会与patch embedding相加。
point prompt分为坐标和前景/背景两部分,坐标通过position encoding得到256维的向量,然后前景/背景则分别设置一个可学习的embedding相加。
box prompt表示为两个point prompt,为左上角和右下角。
text prompt是CLIP提取的token。
然而,这篇文章没有过多的关注text prompt,重点在于geometric prompt。
Mask Decoder
Mask Decoder将image embeddings和prompt embeddings映射到多个粒度的输出mask。
首先,将多个[class]token与prompt embeddings组合,[class]`之后会被用来得到不同粒度的mask输出。
Decoder分成四步
- token自注意力
- token对image embedding交叉注意力
- token FFN
- image embedding对token交叉注意力
这种类似bi-attention的方式进行两层,最后再来一次额外的token对image embedding交叉注意力。
由于分割任务与位置关系十分密切,所以在每个attention层,都会将positional encoding加在image embedding上,同时原始的token也会加到更新后的token上。
在decoder处理之后,就要开始生成mask。首先把image embeddings通过卷积上采样4倍,然后将[class]token通过3层MLP得到一个张量,这个张量与image embeddings按元素相乘,得到mask的预测。
SAM的使用3个[class]输出3个mask(whole, part, subpart),训练的时候,选择与Ground Truth最接近的粒度计算损失并回传。
在推理的时候,3个mask会通过预测的IoU进行排序来得到最终输出的mask。IoU是预测面积和真实面积的交并比,模型会通过[class]+MLP预测得到一个IoU分数,可以认为是模型输出的对于自己预测的置信度。
Training
训练使用focal loss和dice loss以20:1的比例进行,同时模型预测IoU分数还会通过MSE与实际的IoU分数计算损失。
训练策略采用了interactive segmentation setup:
- 在标注的mask中,选择一个前景的point或者box,选择box时会给坐标增加一些噪声来模拟人的划分误差。
- 在拥有第一轮的输出后,之后的point会从之前预测错误的区域进行采样,假如预测错误的情况是false negative(该像素应该要被选中但是没有)则为前景点,假如是false positive(改像素不应该被选中但是选上了)则为背景点。同时,前一轮的预测结果将作为mask prompt进行后面轮次的训练。这样的中间轮次持续8轮。
- 8轮过后,剩余2轮不添加新的prompt,仅使用已有的prompt进行训练。
这种交互式的训练策略总共有11轮,论文中说后续可以尝试更多的数据和更多的轮次,因为image embedding只用提取1次,而light weight的decoder可以便捷地运行多次。
Segment Anything Dataset
数据集包含11M超高质量的图片(平均分辨率,发布的分辨率降低到短边1500)。
除此以外包含1.1B的mask,mask的收集过程见下文。
如下图所示,每张图片的mask数量多、精细程度高,并且图像来自世界的各个地方,对AI的公平性有贡献。

Segment Anything Data Engine
如此厉害的数据集,标注过程分成三部分:模型辅助人工、半自动、全自动。
Assisted-manual stage
首先,作者先使用一些公开的数据集训练一个SAM出来,然后通过SAM“头重脚轻”的架构,设计了交互式的实时的标注平台。标注者被要求标注他们能够描述出来的任何东西。
在这个过程中,一边标记,用来辅助的SAM不断进化,使用标记出来的新数据进行训练,图像编码器也从ViT-B扩展到ViT-H,这样重新训练了6次,最后标注者平均14s可以标注出一张图像。
这一阶段总共收集4.3M mask和120k图像。
Semi-automatic stage
半自动阶段,旨在提升数据集的多样性。所以这个阶段作者给SAM添加了一个目标检测的head,用来检测图中所有的物体,然后让标注者去标记那些没有被框出来的物体。
同样,这一阶段也重新训练了5次,由于难度上升,标记时间为34s,但每个图像的mask数量上升。
这一阶段总共收集5.9M mask和180k图像。
Fully automatic stage
全自动阶段,旨在提升数据集的量。作者给SAM一个的网格point prompt,每个点都能预测出3个mask。这一阶段利用一些手动的算法来选择可信的mask。
- 模型输出的IoU分数当作置信度,通过阈值选出可信的mask。
- 选择出stable的mask:mask像素的概率,卡阈值为和,假如两个阈值生成的mask类似,那么这就是一个stable的mask。
- 使用非极大值抑制(NMS)来过滤重复的mask。
这一阶段总共收集1.1B mask和11M图像。
实验
zero-shot point mask

SAM主要与一个单点交互式分割网络RITM进行比较,上图(a)是在23个数据集上相对RITM的定量分析,大部分更好,少部分数据集更差一些。(a)中还有橙色的点,表示“oracle”模型的评价,因为SAM会输出3种mask,非oracle的情况就是选择置信度最高的mask与GT进行比较,而oracle则是将3中mask与GT进行比较,取最相似的。在oracle的情况下,SAM在所有数据集上表现都更好。
(b)则是在几个数据集上的人工评价, (c)(d)则是加入了其它baseline的比较。
zero-shot edge detection
用网格获得768个mask,NMS之后使用Sobel得到边缘,感觉非常不错!

zero-shot object proposal
用的网格+NMS来获得非常多的mask,并通过执行度和稳定度获取top 1000个proposal,在LVIS数据集上进行评价,效果也很好。

zero-shot instance segmentation
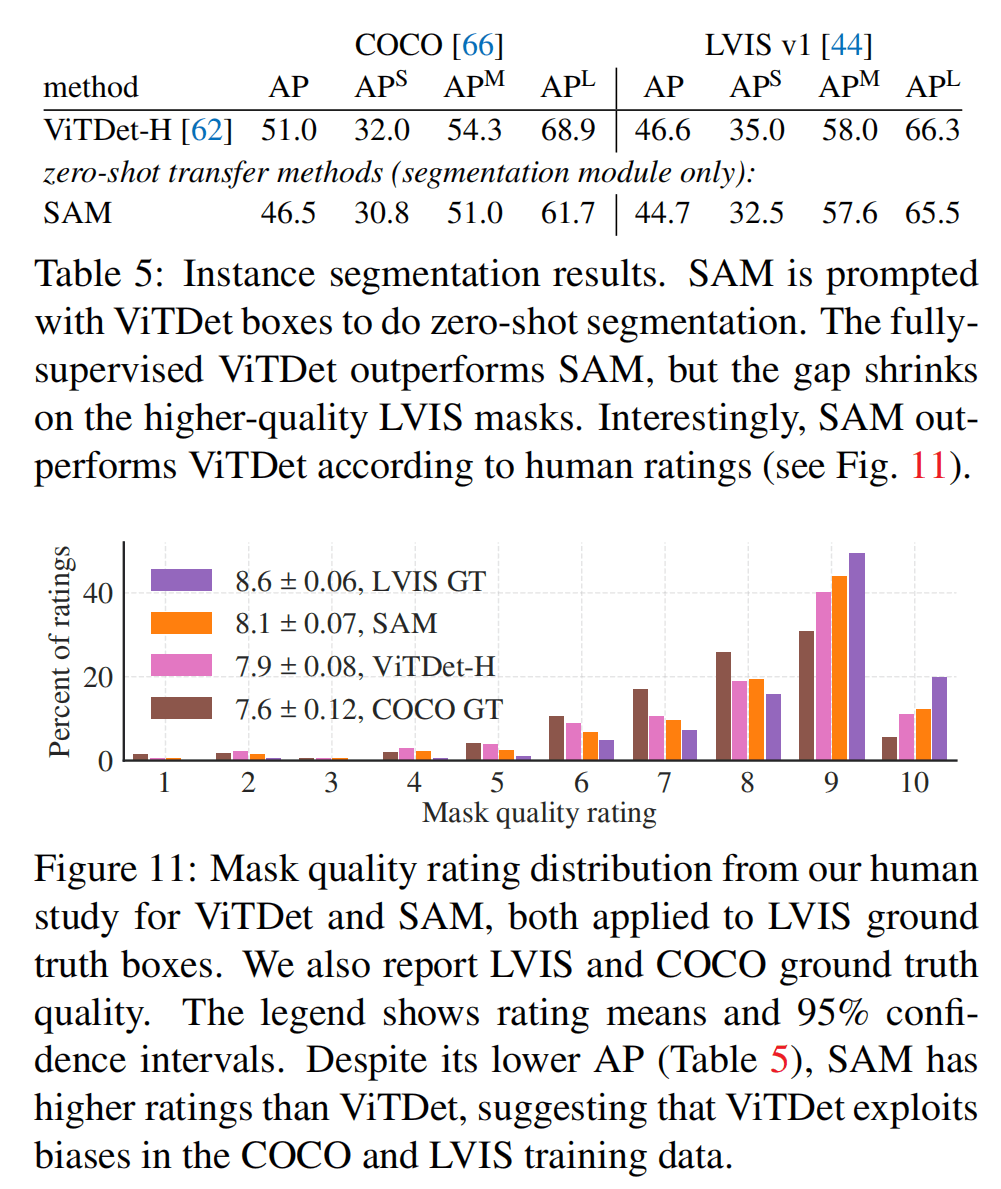
这里使用了目标检测模型ViTDet来检测框,然后用框给SAM prompt。
这里和全监督的方法对比,发现在小数据集上有一定差距,在更精细的LVIS数据集上差距减少,而在人工评测上效果更好。
zero-shot text-to-mask
这个训练方法非常有趣,SAM的常规训练没有使用text prompt,数据集也不包含文本,他们zero-shot text-to-mask的方法是对于数据集中大于像素的区域,提取其CLIP image embedding作为prompt。
注意这里是image embedding而不是text embedding,因为image和text是在同一个语义空间的,在训练的时候无需额外的文本标注来训练,而预测的时候就可以直接用文本来进行推理。

上图是定性分析,发现用文本的效果不是非常好,因为有模糊语义的存在,但是结合point一起作为prompt的话就更好了。
总之,本文只是对文本进行了初步的尝试,只是展现了潜力。
消融实验

在数据上,最后使用的数据集只包含自动生成的部分,左图证明加上人工标注部分效果只有微弱增加,所以自动生成部分的数据已经很好了。
中间图证明使用10%的图片作为训练数据效果与100%相当,可以是一个practical setting。
右图说明使用小一点的编码器也可以。
总结
总之,SAM是一个为了“通用”而设计的模型,在各个细小的任务上不一定能超过专精的模型,但SAM任务和数据集的提出为更好的AI创造了可能性。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!