论文笔记 Segment Any Anomaly without Training via Hybrid Prompt Regularization
本文最后更新于:2023年7月7日 下午
论文笔记 Segment Any Anomaly without Training via Hybrid Prompt Regularization
论文链接:Segment Any Anomaly without Training via Hybrid Prompt Regularization (arxiv.org)
2023.5月华中科技大学在Arxiv上发表的论文,是CVPR2023 **Visual Anomaly and Novelty Detection (VAND) 2023 Challenge **的Zero-shot赛道第二名。
文章提出了一种通过利用视觉基础模型进行图像异常分割的zero-shot方法,该方法使用Grounding DINO + SAM + Regularization,在不进行任何训练的情况下进行图像异常分割,并通过融合多种prompt为基础模型注入异常检测领域的专业知识。最终在多个数据集上SOTA。
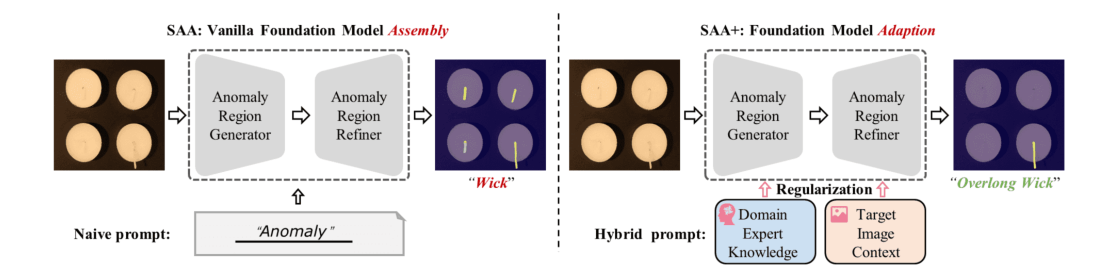
文章提出的模型叫作SAA+,其基础版本(SAA)如下面左图所示,Anomaly Region Generator是Grounding DINO模型,这是一个可以通过自然语言进行open-vocabulary目标检测的模型;Anomaly Region Refiner是SAM模型,就是Segment Anything,可以对图像进行分割。基础版本模型通过“Anomaly”这样简单的prompt让Grounding DINO进行检测,然后通过检测框让SAM分割。由于模型对异常的定义不明确,所以SAA容易出错,而SAA+在此基础上加入了专家知识prompt和一些先验的限制,最终使模型能够较好进行异常分割。
前置:使用到的视觉基础模型
Grounding DINO
首先简要介绍Grounding DINO模型(IDEA开发),它能达到的效果如下图所示,不仅可以根据用户输入的任意词进行检测(open-vocabulary),还可以理解用户的自然语言形式的需求从而进行分割。

模型架构如下图所示,设计思想主要为:多模态Transformer、DETR类queries模型、更早更充分的特征融合。
用Transformer做多模态已经被广泛使用就不多说了,DETR类通过query来进行目标检测的模型可以端到端训练不需要NMS,对于非检索类的模型,越早融合多模态性能应该越好。模型在neck、query init和head三个地方进行了特征融合。
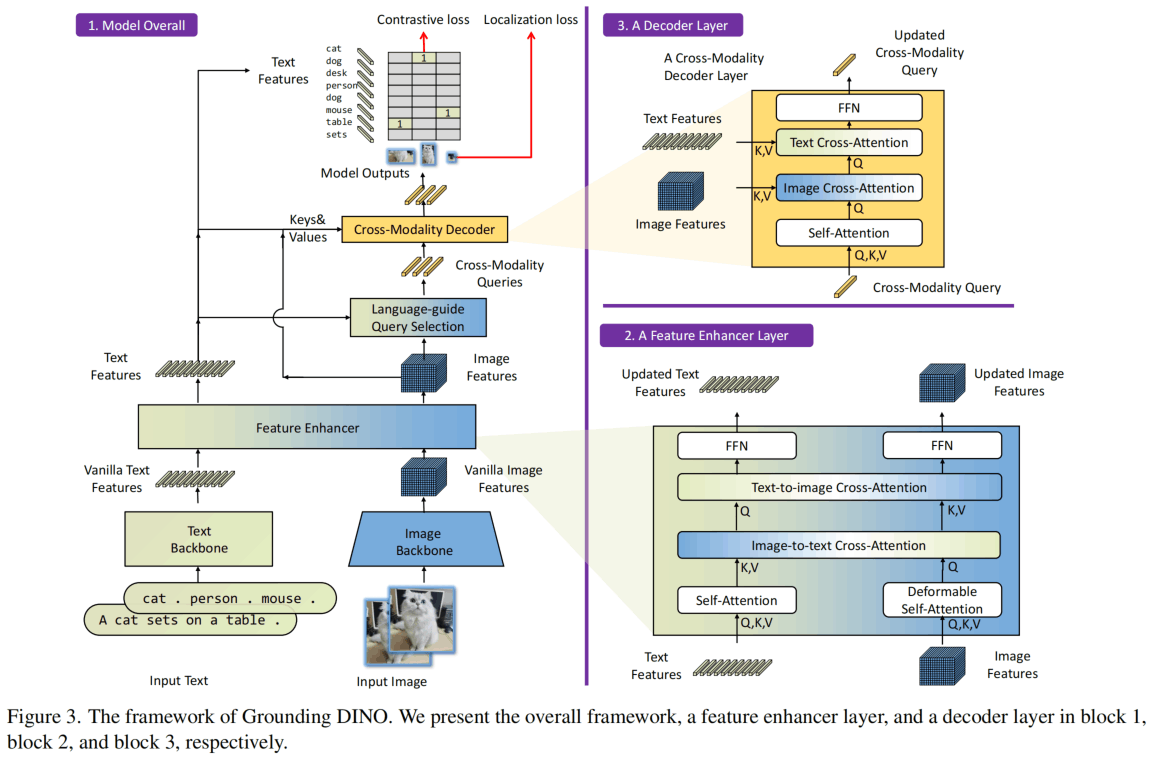
模型细节不在这里阐述,得到的Tiny模型参数172M,Large模型341M,分别使用Swin-T和Swin-L作为视觉backbone,使用BERT-base作为文本backbone。Feature Enhancer为6层,Cross-Modality Decoder也是6层,hidden dim只有256比较低。
训练一个GPU只能有一个样本……,用了64个A100结果总batch size也是64……
Segment Anything(SAM)
Meta AI开发的模型,火出圈了。模型能够使用点、框、mask、文本作为prompt引导分割,并使用轻量的decoder来生成mask,模型在11M图像+1B mask上进行训练。
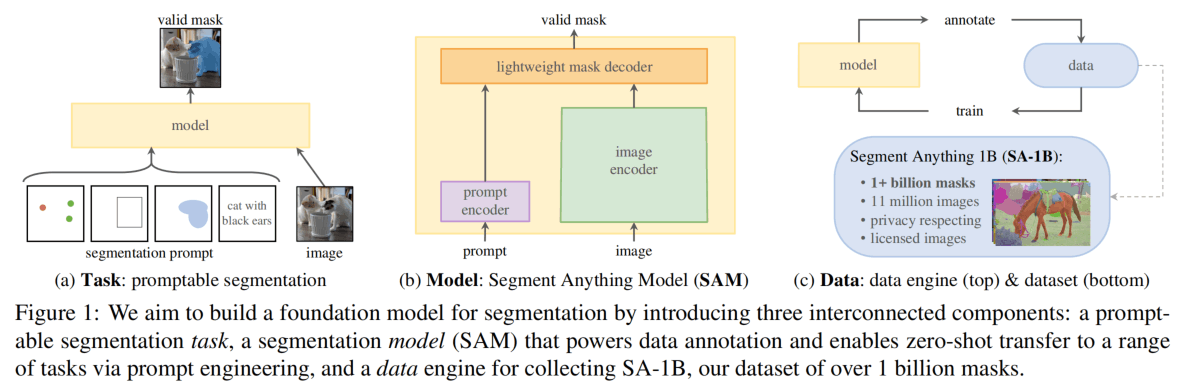
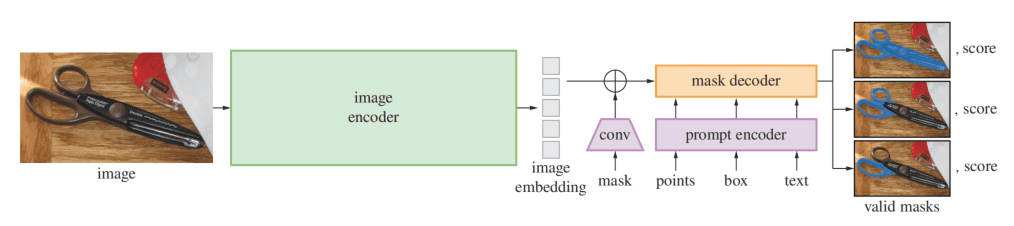
模型架构如下图,image encoder使用了高分辨率MAE模型,prompt encoder分为密集(mask)和稀疏(point、box、text),前者使用卷积编码和element相加,后者使用embedding,其中文本使用CLIP的编码器。Mask decoder是一个两层的Two Way Transformer,最后上采样+MLP得到mask。
SAA
GroundingDINO可以根据语言prompt 和图像 得到对应的检索框和分数:
而SAM可以根据框和图像得到像素级别的mask :
**分析:**SAA提供了zero-shot异常分割的基本流程,但是发现使用naive prompt(比如“Anomaly”)不能使GroundingDINO得到准确的框,因为在不同环境下“异常”是不一样的,比如图中的蜡烛芯,本来只有过长的才是异常,而SAA把所有蜡烛芯都看作为了异常。所以,需要为“异常”添加先验。
SAA+
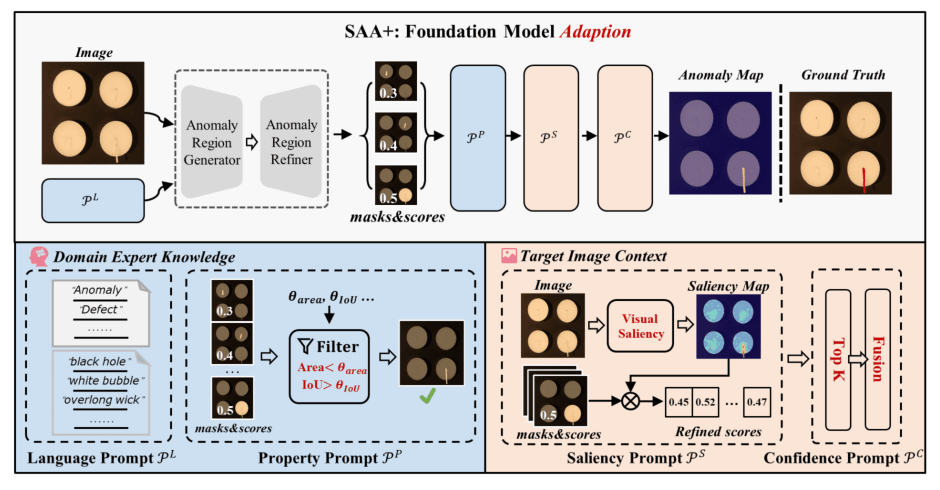
SAA+如图所示,在SAA的基础上添加了Domain Expert Knowledge和Target Image Context两个方面的Regularization,总共提出了4种Prompt,最终的方法就叫做Hybrid Prompt Regularization。
Anomaly Language Expression
这个模块提供给GroundingDINO更细致的prompt,包含通用的提示(“anomaly”、“defect”)和类别相关的提示(“black hole”,“overlong wick”),让目标检测模型根据这些更细致的描述找到异常区域。
符号如下:通用提示(),类别相关提示(),两者组合()。
Anomaly Object Property
在得到mask和score()之后,首先根据异常的一些先验知识进行过滤,这里需要通过GroundingDINO得到被检测物件的位置和面积,然后计算mask candidate与其的IoU,并通过阈值过滤。
过滤之后得到,这一步叫
Anomaly Saliency
对于输入图像,计算其saliency map ,即对于每一个像素计算其与临域像素之间的差并求和。这里的叙述说像素,但是实际上是用了WideResNet50的特征图。
然后对于每个mask candidate,计算其saliency score ,即mask部分的saliency的均值的指数。然后与原来的置信度相乘得到新的分数
Confidence Prompt
选出top-K个置信度最高的mask candidate,然后组合在一起得到最终的分割。这一步叫。
实验
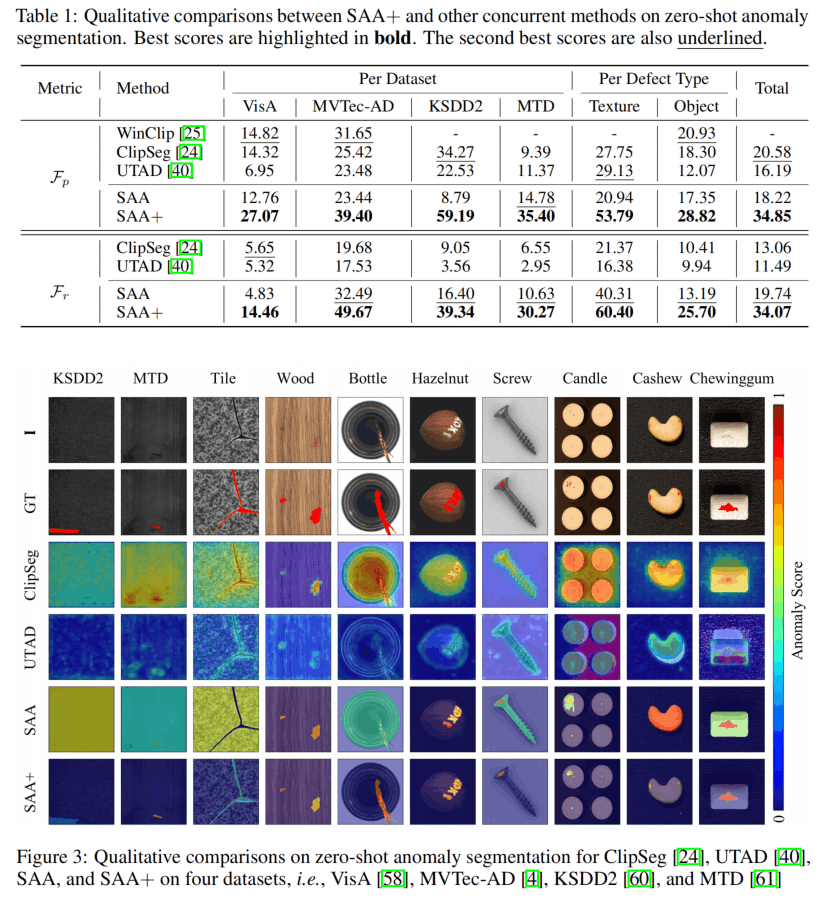
结果如上,没什么好说的,就是好,接下来是消融:
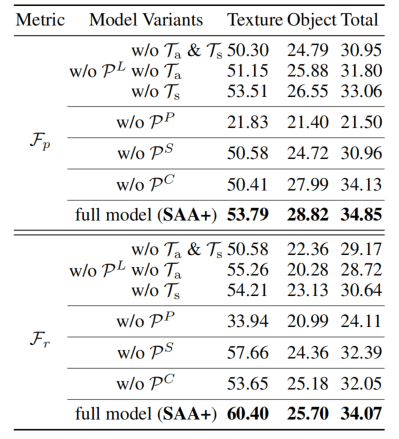
发现的贡献最大,是通过面积和IoU过滤的那一步。但是描述缺陷定义却没有贡献很多。
结论
在不同的领域中,“异常”是不一样的,这是一个非常难定义的概念,甚至不可能被定义出来(假如定义螺丝钉上有划痕为异常,那有的带花纹的螺丝钉又应该是正常)。但是,在实际使用中,某个环境下的异常一般是稳定的,比如过长的蜡烛芯、有孔洞的木板等,因为不能对于每个场景都进行大规模训练,所以有了few-shot和zero-shot的方法。
这篇文章通过利用了两个在大数据集上预训练的模型,相当于利用了“常识”,然后通过4种手工的方法去添加“异常先验”进行限制,并且可以用语言的prompt来提示检测哪种异常,思路感觉很不错。假如放到视频异常检测中来,在每一个场景下可以用自然语言去定义异常行为是什么,那么就更容易实际应用,比如在公园里滑滑板是正常,但是在马路上就是异常。然而实验的结果不是很理想,手工的方法也不是很novel,感兴趣的点与其说是这篇文章,不如说是其使用到的两个模型。
下面以这种思路,在视频异常检测任务上开开脑洞:
视频异常检测的异常定义比较难,不同领域不一样,比如网络视频、监控摄像头就有比较大的差距,使用一个固定的模型来检测或分类所有情况比较困难,对于每种场景也不想去过多的训练,并且异常样本少也是一个问题。那么是否可以借助基础模型进行一种新的范式?假如是校园马路场景,那么我给模型一些异常行为的描述,比如“逆行”、“摔倒”、“打架”,然后让模型对这些行为进行检测。又或者我给一些正常行为的描述,除了这些行为都被认为是异常。又或者我可以给除了语言以外的提示,比如时间?天气?位置?图片(比如竖中指的图片)?要是弄出来了,模型名字就叫“Detect Any Anomaly”吧。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!