论文笔记 Streaming Video Model
本文最后更新于:2023年7月6日 下午
论文笔记 Streaming Video Model
论文链接:Streaming Video Model (arxiv.org)
代码链接:yuzhms/Streaming-Video-Model Code for “Streaming Video Model” (github.com)
中国科技大学学生在微软实习的一篇CVPR2023论文,论文的标题野心很大,叫作Streaming Video Model,视频流模型。文章提出了一种Streaming Vision Transformer(S-ViT)模型,其统一了以序列为基础的任务(行为识别)和以帧为基础的任务(多物体跟踪),并能够高效处理长视频。
介绍
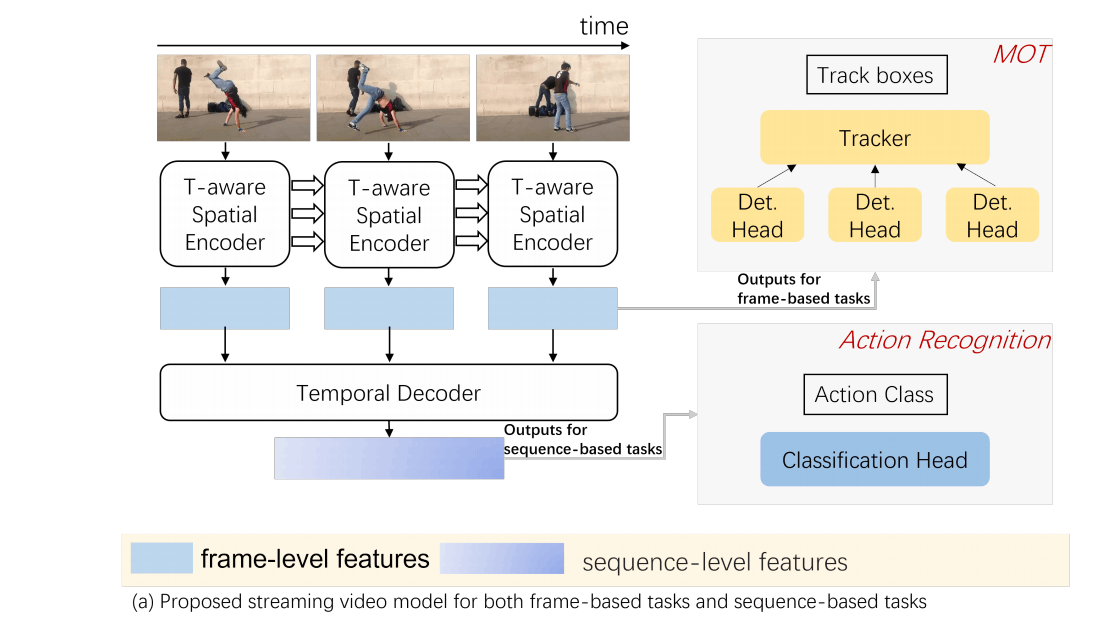
S-ViT的架构如上图所示,包含了两个阶段,第一阶段是memory-enabled temporally-aware spatial encoder,有记忆功能、考虑时序、基准为ViT,得到帧级别的特征。第二阶段则是收集之前的特征,使用一个时序的基于Transformer的解码器得到序列级别的特征。
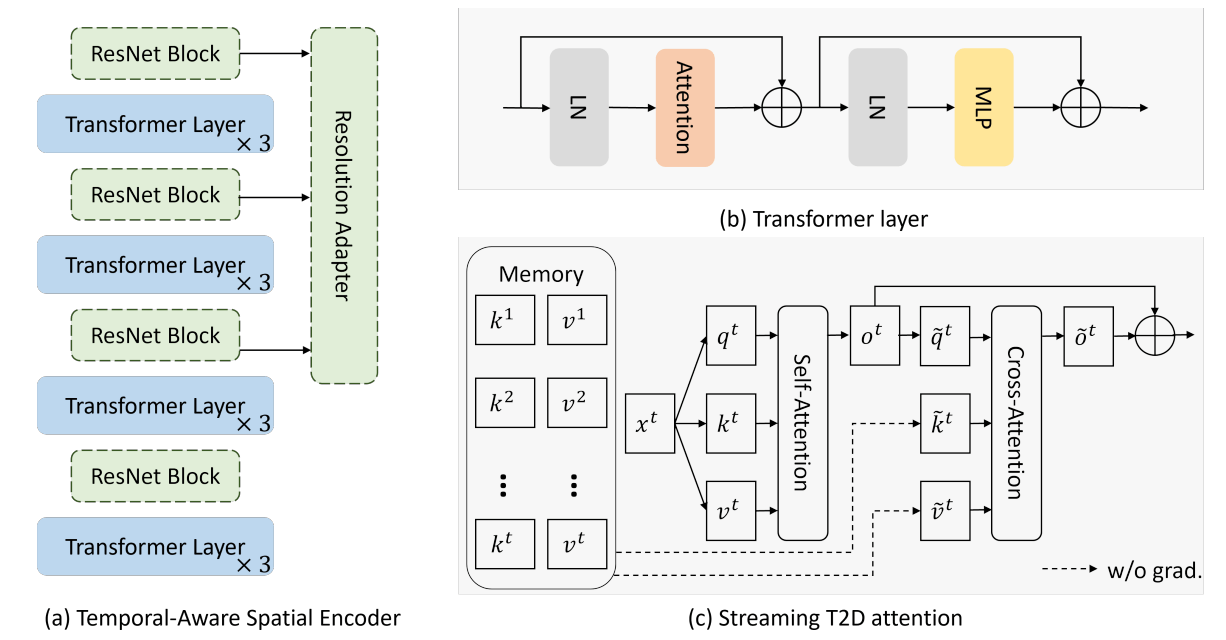
第一阶段的解码器如上图(a)所示,包括多层Transformer层、可选的ResNet层和可选的Resolution Adapter层。后两个在需要多尺度特征图的任务中被使用。
Transformer的架构如上图(b),但是其中的Attention改成了图(c)中的Streaming T2D Attention。首先,图像patch普通地计算自注意力,得到,并保存中途生成的到记忆池中,记忆池中的张量从计算图中脱离开。
之后,输出进行交叉注意力,来对记忆池中存储的以往的帧施加注意力。直接做全注意力算力消耗太大,所以此处分为XT和TY两个数据平面进行注意力,XT就是patch只会与记忆池中相同横轴、不同时序的patch进行交互,TY则是patch只会与记忆池中相同纵轴、不同时序的patch进行交互。
两个平面的输出通过可学习的通道权重融合,得到。
CLIP-ViT-B/14作为基准模型,有12层,4阶段,每阶段3层,每个阶段后可插入ResNet。时序解码器则是4层简单的Transformer。
行为识别的分辨率用224,追踪任务的分辨率就可能高达1440x800。
实验结果

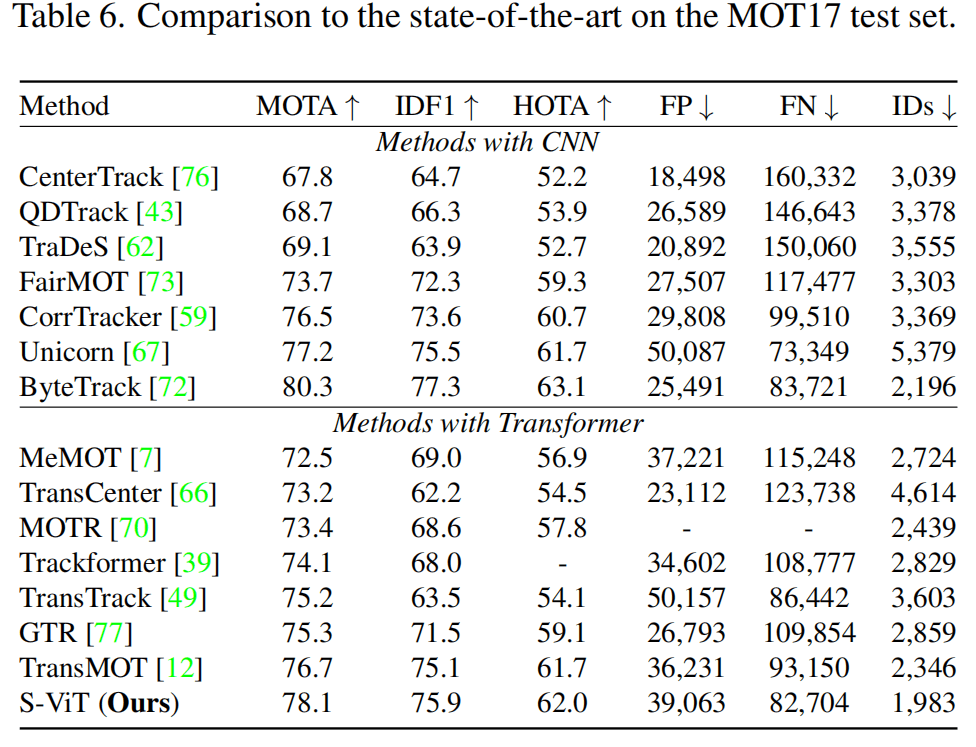
Tab1和Tab6是跟踪的结果,总之效果还是很好的。

K400上S-ViT和SOTA X-CLIP、T2D-B的性能差不多。
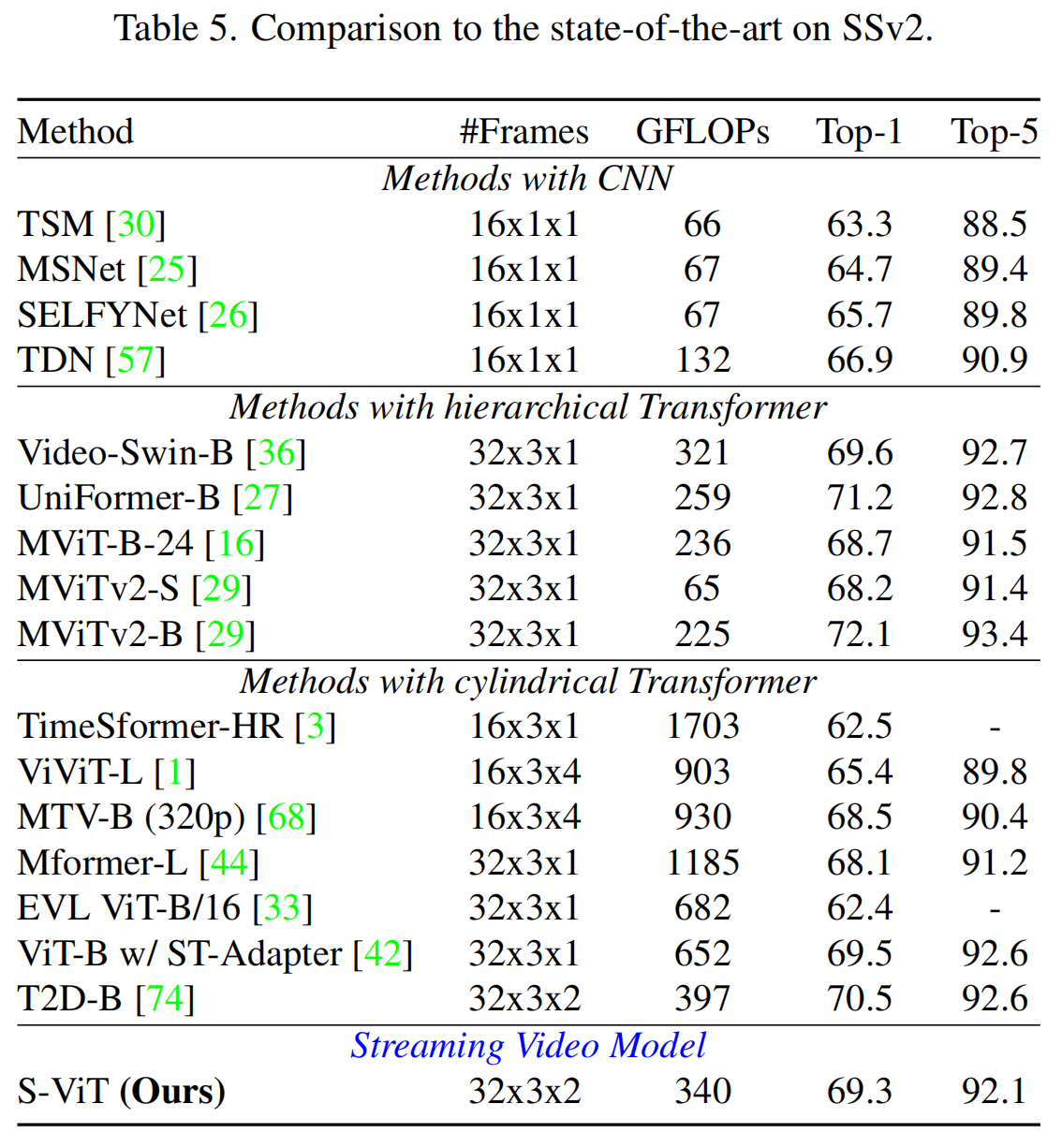
SSv2没比过T2D-B。
但是作者在论文说她们这个是streaming的模型,当前帧是看不到后续帧的信息的,所以和这些相比能达到同等效果还不错了。
结论
感觉新意不是很足,所谓“记忆”也就是保存了前几帧的信息,各种设计都是借鉴其他论文的,缝合在一起也没有体现出能够处理长视频的特点。而且看论文里所谓长视频也就是32、64帧这样。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!