CVPR2023 Tutorial Prompting in Vision笔记
本文最后更新于:2023年7月5日 下午
CVPR2023 Tutorial Prompting in Vision笔记
学习CVPR 2023的Tutorial:Prompting in Vision的笔记
官方网址:Prompting in Vision (prompting-in-vision.github.io)
我做的合并PPT下载:https://pan.baidu.com/s/1F2XXqTTbhdUb3IFvT6n5Zw?pwd=hwon
Prompting in visual intelligence and generation

过去的AI是一个模型进行一个任务,现在的AI是一个模型通过不同prompt执行多个任务,现在2023年的典型代表有DeepMind的Flamingo、NTU的OTTER、Meta AI的SAM。
Prompt是由CLIP引起的,CLIP有强大的zero-shot能力。为了在某个领域获得更好的效果,有人尝试微调CLIP,发现并不是一个很好的选择,会导致泛化性的下降。所以类似CoOp的这种添加learnable context的方法出现,通过学习prompt而不是手动构建,可以进一步使CLIP适配领域。
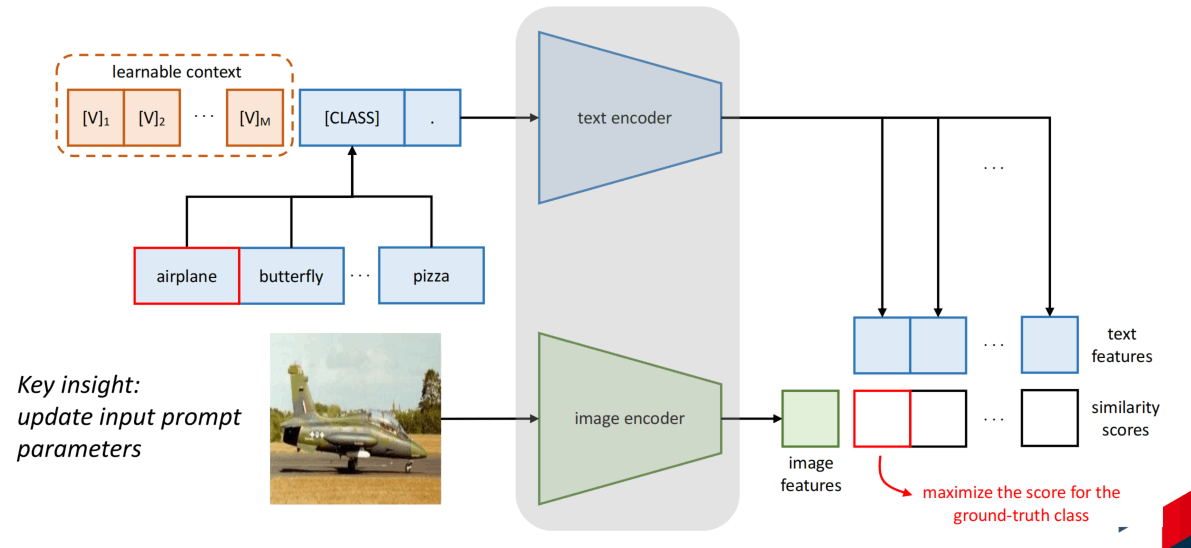
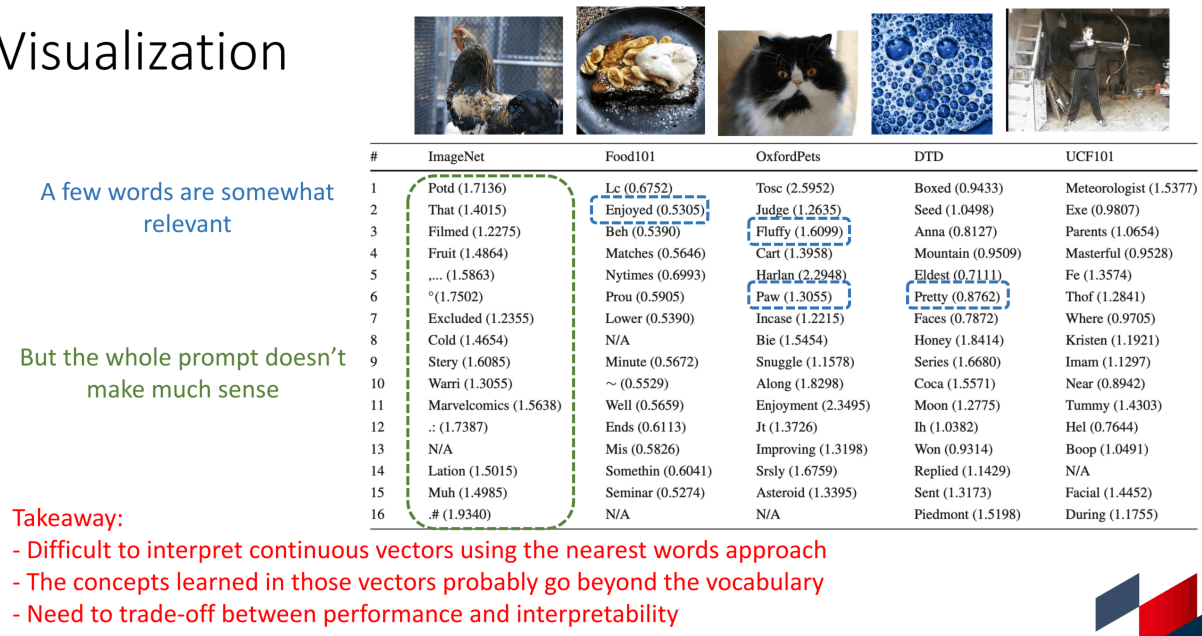
然而,CoOp的可解释性并不是很好,如下图所示,学习到的prompt通过nearest words方法可视化之后发现大部分都prompt都不怎么相关,可能是因为学习到的概念超越了vocabulary。并且研究还发现,CoOP学到的prompt在面对未见过的类别时还可能发生性能的下降。
随后CoCoOP这种给文本侧添加图像相关prompt的方法出现,还有同时添加视觉和文本prompt的方法。
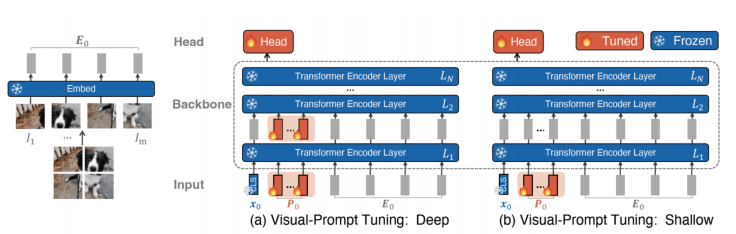
这种可学习的prompt扩展为了PEFT或者adapter系列,比如Adapter、LoRA、VPT等。
在Text-to-Image上有更多使用prompt的方法:

作者接下来举了几个例子
-
DALLE
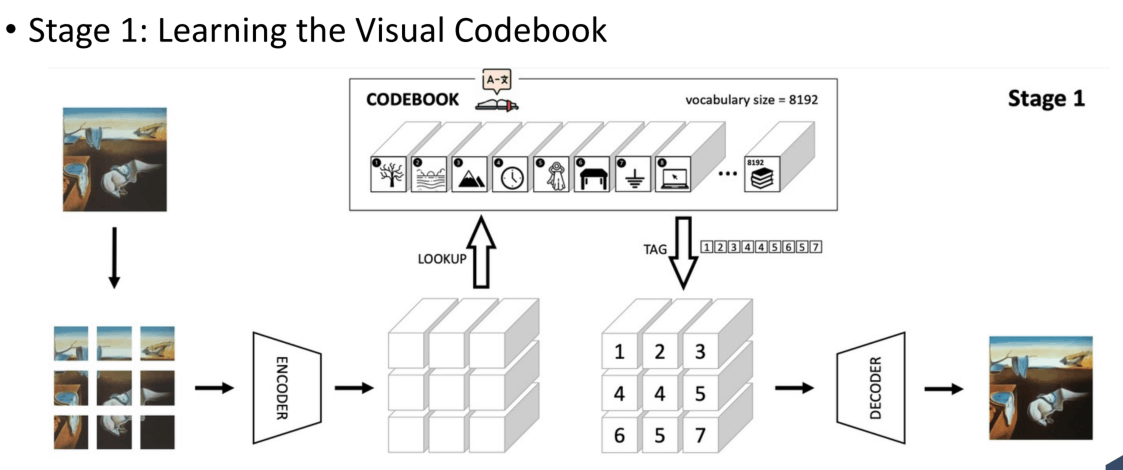
第一阶段训练一个dVAE,也就是途中的CodeBook,它能把图像压缩到的one-hot分布,对应了CodeBook中的8192个视觉概念。
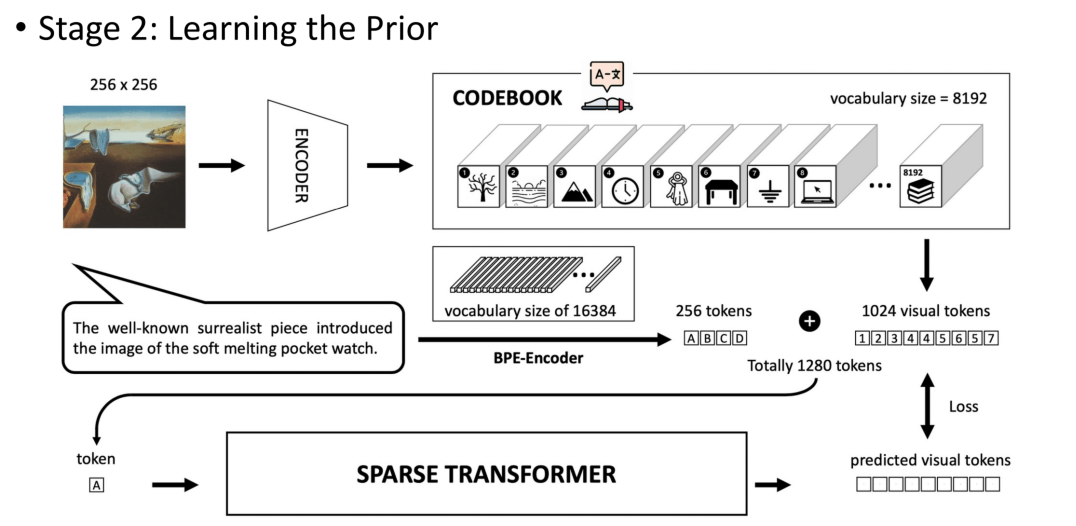
第二阶段,使用预训练的CodeBook得到视觉token,再将对应文本提取出256个文本token,加起来1280个token,经过一个特殊的Transformer进行自回归式生成学习,一次生成一个视觉token,这个特殊的Transformer使用了稀疏的注意力。、
在推理阶段,就只输入文本,然后让Transformer输出预测的视觉token,然后通过CodeBook来解码。
-
GLIDE
通过扩散模型+Classifier-free引导来生成。
-
DALLE2
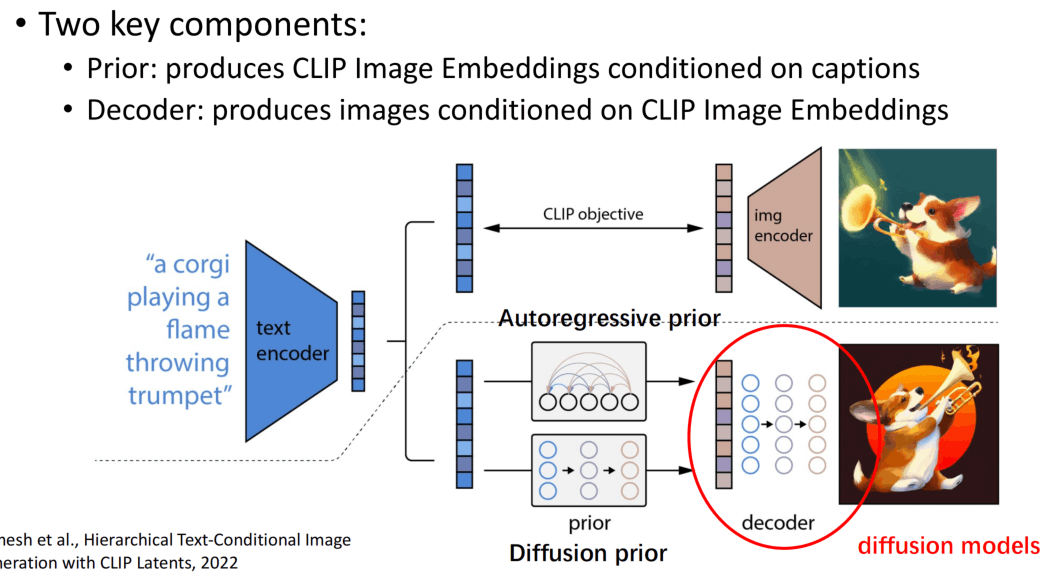
同样是多阶段训练,首先文本的embedding通过prior变成视觉embedding,此处实验了自回归式的生成和扩散的生成,结果是扩散生成跟好,最后通过decoder生成最终的图像。
-
Stable Diffusion
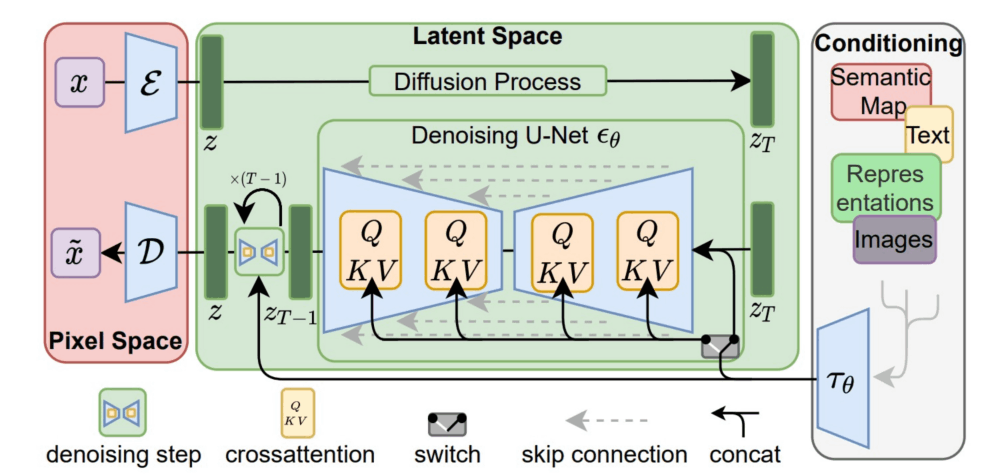
-
GigaGAN
-
Text2Human
例子没有详细解释,因为我也不太懂……
在Text-to-Image中,为了控制外观生成的prompt方法有Textual Inversion、DreamBooth、Tuning Encoder、ELITE、Taming Encoder等。
Textual Inversion就是用单一类别的图像训练一个Text Token,要用的时候加就可以了。
DreamBooth就通过使用一个特殊的少见的token来Finetune一个模型,使模型能够将这个token与新的概念绑定。
剩下几个PPT里给的信息太少就不说了。
为了控制关系的生成,有ReVersion和Collaborative Diffusion等方法。
文章还介绍了很多Text-to-Video、Text-to-3D、Text-to-4D
因为实在不熟悉就看不太懂了。
Teach Language Models to Reason
第二个pre的ppt比较生动,首先说AI应该能够从少量的样例中进行学习,而我们应该像教小孩子一样教语言模型去推理。

作者列举一个简单的任务,即把输入中每个单词的最后一个字母取出,然后发现目前的LLM都无法直接理解这个任务。
但是使用思维链CoT之后就可以了,CoT可以显著提升许多任务的效果,对于CoT的构建成为了重点。
除此以外还有Self-consistency(SC)的方法,即使用多种CoT,并从回答中选择最一致的回答。
对于更难的问题,还有Least-to-most的提示方法,它将复杂问题分解为多个更简单的小问题,然后依次解决。
由于人类容易被不相关的文字所干扰,所以给LLM提示“忽略不相关的上下文”也能提升效果。
有的方法(FLAN2)还使用了1800+种任务来微调LLM。
通过这些方法,可以发现,教LLM推理的方法和教人的方法类似!
Visual Prompting
语言模型的prompt是在不更新模型权重的情况下改变输出,视觉的prompt则应该也类似。
视觉prompt可以是point、box、mask、image等。
为什么要做视觉prompt?因为这样可以提供给人更灵活、更舒适的接口,并且提升人控制的灵活性,还可以方便连接到其它模型。
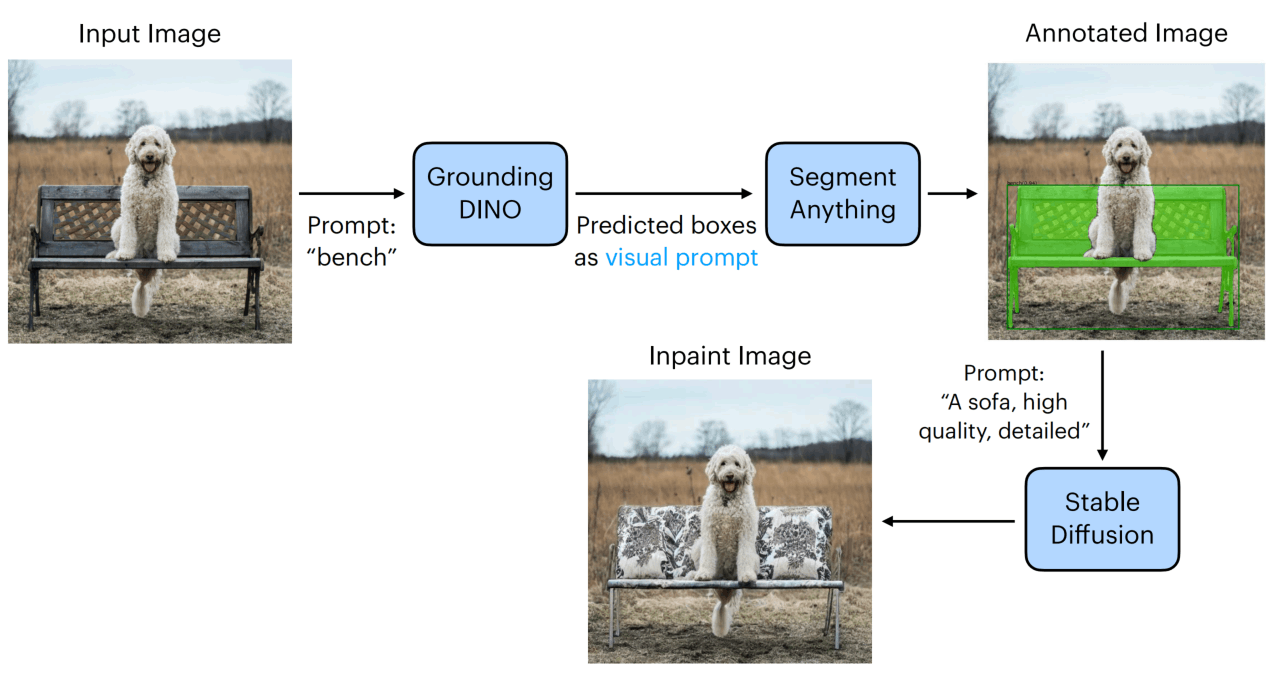
如下图,图像通过目标检测模型得到框,然后根据框使用SAM分割,然后再通过扩散模型修改图像。
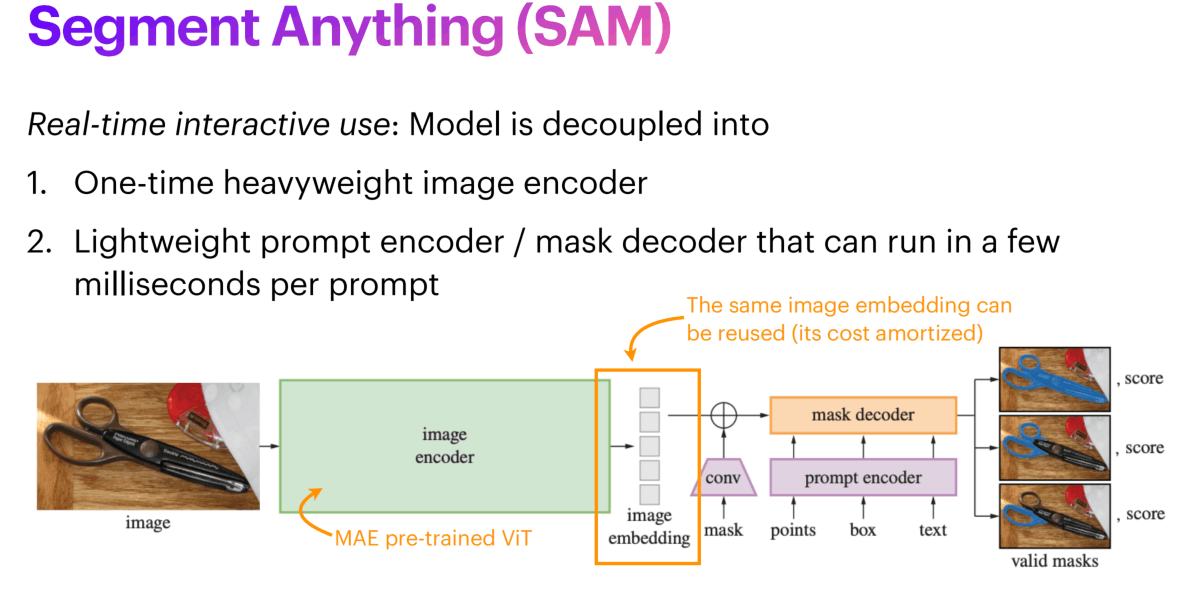
SAM的具体架构如下,通过一个强大的一次性使用的图像编码器(ViT)得到图像embedding,然后通过不同的方式对embedding进行引导,最后通过mask decoder生成mask。
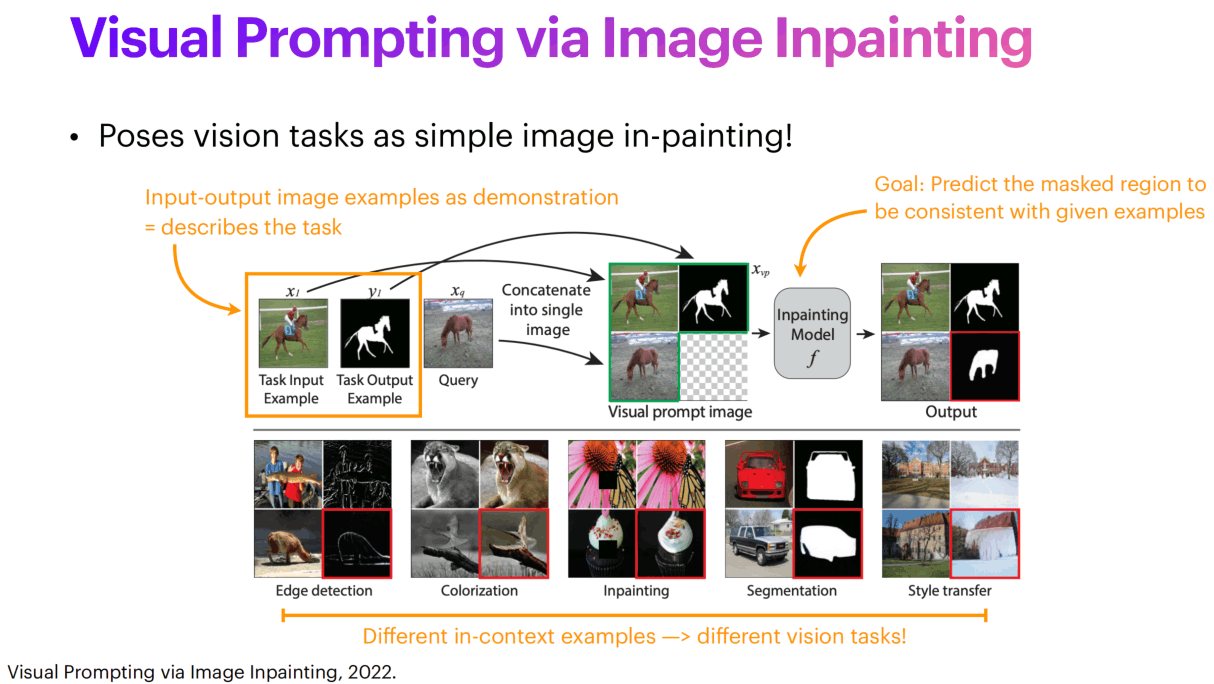
除了SAM以外,还有使用inpainting来做incontext learning的。一个大图分成四块,上面一行是例子,左下角是query,右下角就是inpainting的输出。
GLIGEN则是使用框框和标签来作为提示,控制生成图像的构图。

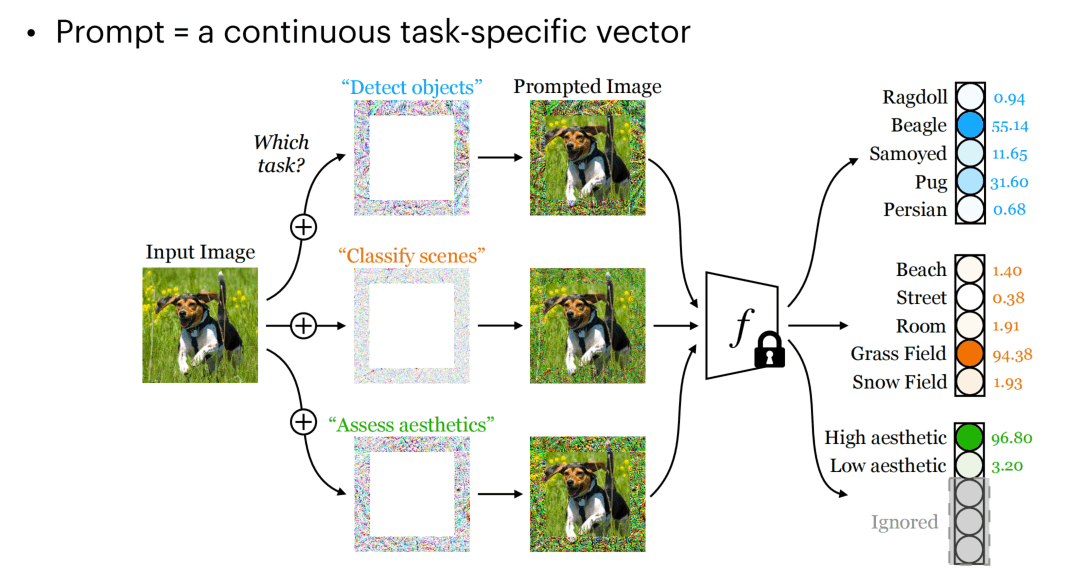
视觉上也出现了类似的pixel visual prompt,在图像外面裹一层编码来控制任务,另模型产生不一样的输出。
还有借鉴于LLM的各种PEFT的方法:
Prompt Generation for Zero-Shot Image Classification
CLIP方式的zero-shot有一些缺点:
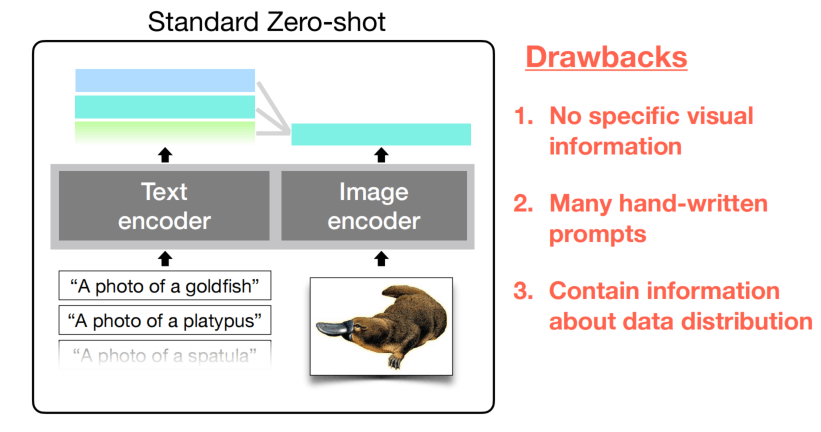
手写的prompt没有包含更多的视觉信息,比如在细粒度分类所需要的描写;并且认为能够构建很多手写的prompt,不知道怎么选;构建出来之后也可能包含一些隐藏的数据分布。
使用LLM来生成prompt可以用更少的prompt获得更好的效果:
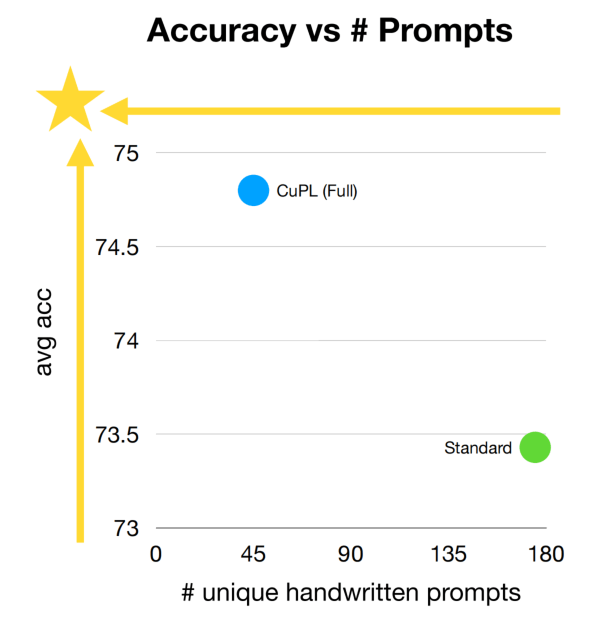

左边的就是普通的prompt,右边的则是更细致、包含定义和额外描述的prompt。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!