多模态哈希检索初见
本文最后更新于:2023年7月5日 上午
多模态哈希检索初见
多模态检索就是使用一种模态的数据对另一种模态进行检索,比如以文搜图等,用来检索的数据叫作query,被检索的库叫作dataset。哈希检索则是将query和dataset的原始特征映射到二进制编码中,从而提升检索速度。
本笔记通过阅读下面这个综述得来,如有错误见谅:
1 | |
基本方法
将多模态数据映射到二进制编码有两种方法:
第一种方法分为降维和量化两步,首先需要将原始信息降低到一个低维空间表示,这个和普通的跨模态检索一样,比如降低到256维的向量。然后再对特征空间进行量化分割,得到二进制的哈希码,将特征转换到紧凑的汉明空间中。
第二种方法直接学习映射到二进制的编码。
目前后面这种直接的方法更优,一些基于Augmented Lagrangian Multiplier(ALM)的方法使用符号函数生成哈希编码。
距离度量
在汉明空间中,两个向量的相似性使用Minkowski Distance度量,其定义如下
当时,就是异或运算的,或者叫汉明距离,
当时,就是曼哈顿距离,在汉明空间里就是加了个根号,
GCN+Hash Retrieval的一种方法
IEEE Trans on Multimedia:Aggregation-Based Graph Convolutional Hashing for Unsupervised Cross-Modal Retrieval
文章提出了一种无监督的Hash Retrieval方法Aggregation-based Graph Convolutional Hashing (AGCH),这个方法包括一种高效的聚合策略来得到更好的相似度矩阵,还有一个包括编码器、GCN、融合模块的模型。
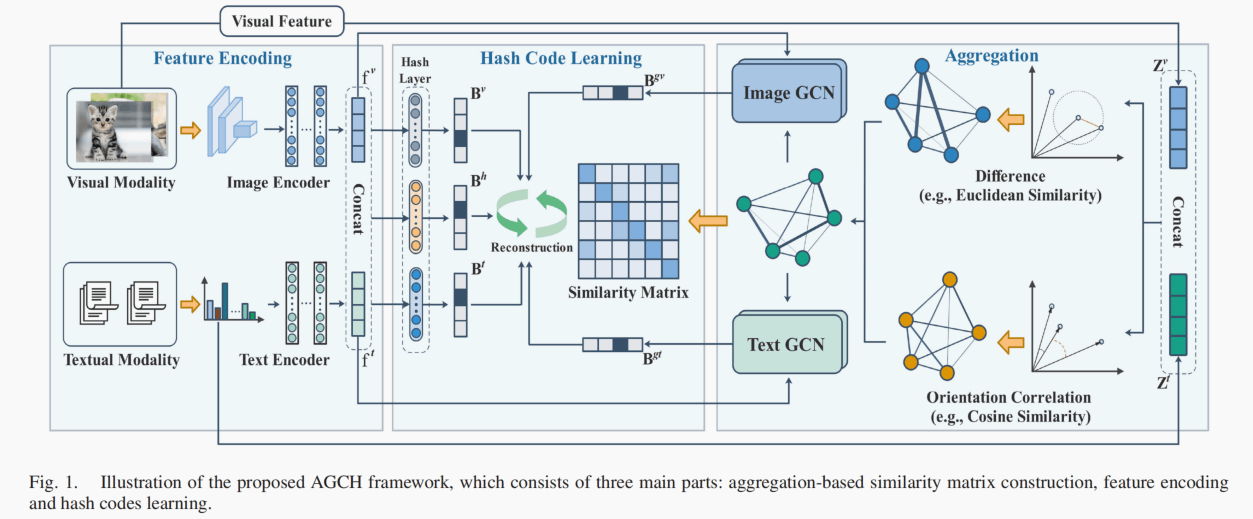
视觉和文本首先通过编码器得到特征,然后拼接在一起得到另一个融合特征,三个特征经过Hash Layer,得到二进制的编码,Hash Layer就是几层MLP,最后使用得到之间,推理时正数为1,负数为-1。
其次视觉和文本还通过另一种预训练的方法得到特征,然后计算多种距离组合在一起得到一个相似度矩阵,这个矩阵作为GCN的邻接矩阵进行编码。
视觉和文本都有GCN,也是分别编码得到二进制编码。
最后这些二进制的编码和相似度矩阵互相监督一下用来优化。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!