多模态语言模型发展观察
本文最后更新于:2023年5月8日 晚上
多模态语言模型发展观察
这篇博客介绍的多模态语言模型指:通过视觉提示生成器将其他模态(图像)的数据转换为Prompt Embedding,再提供给大型语言模型(LLM),从而构建出来的具备多模态对话能力的模型。
本文对这些模型的基本方法和贡献进行简单介绍,将涉及以下模型:
- ✔️BLIP-2:2023.1.30
- ❌Flamingo:2022.12
- ✔️LLaVA:2023.4.17
- ✔️MiniGPT-4:2023.4.20
- ✔️mPLUG-Owl:2023.4.27
- ✔️VPGTrans:2023.5.2
BLIP-2
代码链接:LAVIS/projects/blip2 at main · salesforce/LAVIS (github.com)
Demo:官方HF Demo,但是已不可用、非官方HF Demo
我之前写过一篇详细介绍BLIP-2的博客:论文笔记 BLIP-2 - Kamino’s Blog,这里再简单介绍一下。
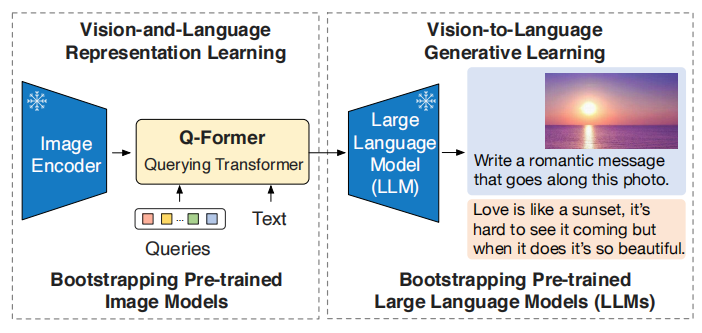
BLIP-2的整体架构如上所示,使用Image Encoder(现在很多也叫作visual foundation model)提取图像特征,然后通过一个Query Transformer(Q-Former,现在也叫visual prompt generator)将特征降维并凝练,之后通过一个映射层,得到固定数量的visual prompt,再送LLM中。
BLIP-2的训练分为两个阶段,第一阶段进行视觉-语言表征学习,即利用Image Encoder和Q-Former进行语义对齐,使Q-Former能够提炼到关键的视觉特征。第二阶段进行视觉-语言生成学习,引入LLM,将提炼的特征作为visual prompt,进行LM生成任务。
在整个过程中,占参数量大头的Image Encoder和LLM都冻结参数不进行训练,从而使BLIP-2的学习效率上升。使用这种方法,可以在不训练LLM的情况下,将LLM打造成多模态LLM。
数据上,BLIP-2使用了来自COCO、VG、CC、SBU、LAION的129M的图像,使用BLIP的方式获得对应的文本。预训练模型的选择上,Image Encoder选择了ViT-L和EVA ViT-G,LLM选择了OPT和FlanT5的多个版本,整体参数从3.1B到12.1B。训练效率上,16张A100(40G)在第一阶段6天,第二阶段3天。
BLIP-2使语言模型初步获得了多模态的能力,为将来的发展探索出了一条高效率的道路,但是训练数据不包含对话,外部知识也不够全面,目前只能问一些简单的问题。

LLaVA🌋
论文链接:Visual Instruction Tuning (arxiv.org)
项目主页:LLaVA (llava-vl.github.io)
这篇文章主要贡献在于构建了一个多模态的instruction-following数据集和使用这个数据集训练出来的LLaVA模型。致力于对标GPT-4的性能。
这篇文章使用ChatGPT来帮助构建Visual Instruction Data,如下图所示,Response的类型包括对话、详细描述和复杂推理三类,使用众包收集人类标注的成本过于高昂,所以通过提供图像的Caption和Bounding Box标注,让ChatGPT来生成数据集。
具体的构建过程可以查看论文,他们总共收集了158K个样例,其中58K是对话、23K是详细描述、77K是复杂推理。

这篇文章以数据为重点,于是只设计了一个简单的模型如下图所示。其中,是图像,是使用Visual Encoder()得到的特征,特征经过一个简单的映射矩阵得到visual prompt,其与语言模型的Embedding维度相同。之后,添加Instruction送入LLM里面进行训练。
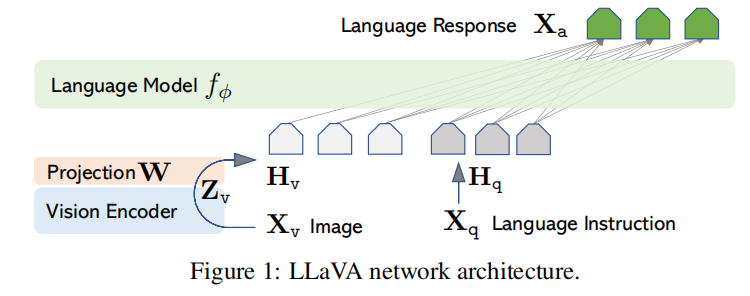
训练过程分为两个阶段,第一阶段为了特征对齐,冻结了Vision Encoder和LLM,就是为了学习一个好的Projection矩阵,使用了CC3M中的595K个图像文本对。第二阶段开始使用instruct的数据,训练映射层和LLM。
LLaVA使用CLIP ViT-L/14作为视觉编码器,使用指令微调的Vicuna作为LLM。
在项目主页有Demo可以随意尝试例子,这里就放一个论文里的:

这篇文章在结尾放出了一些将来的工作:
- 数据量扩大。这种自动生成的数据集构建流程可以利用更多的数据集来构建Instruction数据。
- 连接更多视觉模型。比如连接SAM。
MiniGPT-4
论文链接:MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models (arxiv.org)
项目主页:Minigpt-4
这个比LLaVA更露骨地体现了要对标GPT-4的想法,和LLaVA差了三天发布。MiniGPT-4使用了BLIP-2的架构,引入了经过调优的Vicuna模型,并构建了一个规模较小但是质量非常高的数据集。同时,MiniGPT-4也注重了训练时间,在4张A100上训练10小时就够。

上图是MiniGPT-4的基本架构,和BLIP-2就是一样的。MiniGPT-4和LLaVA一样采用了两个阶段的训练,第一阶段也是通过图像文本对来训练一个好的映射层,这里使用了5M个图像文本对,训练了10个小时,是最耗时间的一步。第二阶段使用自建的高质量数据集,在单卡上就训练了7分钟就能达到很好的效果。
MiniGPT-4的数据收集方式比LLaVA简单,它在第一阶段训练结束后,使用
1 | |
这个prompt让模型详细地描述约5000张图像,然后使用ChatGPT来修复生成中的语法错误并润色。之后,他们手动过了这5000个样本,从中选取了3500个样本并施以润色,保证了数据的高质量……
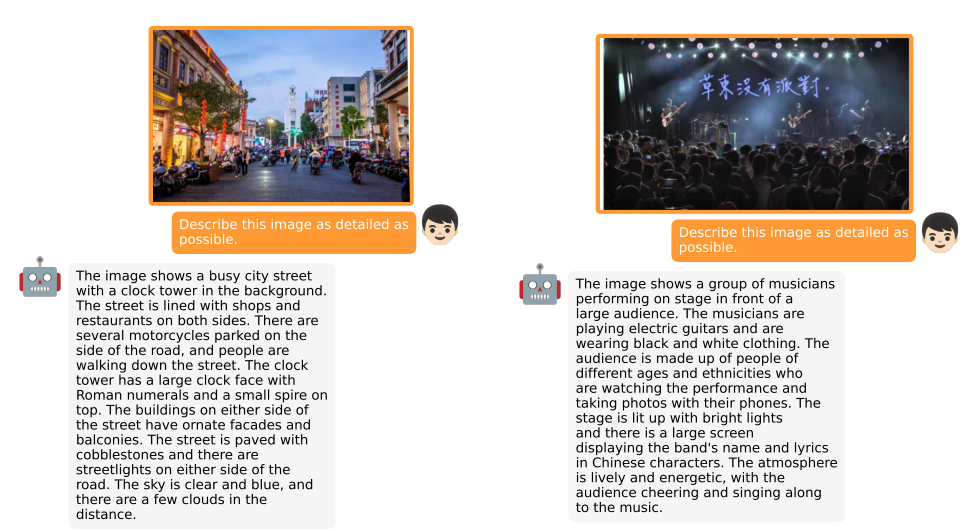
同样,MiniGPT-4给出了很多样例和在线的Demo,这里从论文摘一张图:
mPLUG-Owl🦉
论文链接:mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality (arxiv.org)
论文Demo:mPLUG-Owl Multimodal Chatbot · 创空间 (modelscope.cn)
国产多模态LLM,来自阿里达摩院,mPLUG系列模型使用模块化的训练,这个模型也使用了类似BLIP-2的架构,但没用他们自己的mPLUG-2,和其他工作不一样的是,他们还做了LLM的PEFT。除此以外,这篇文章还构建了一个Instruction Evaluation set,名为OwlEval。
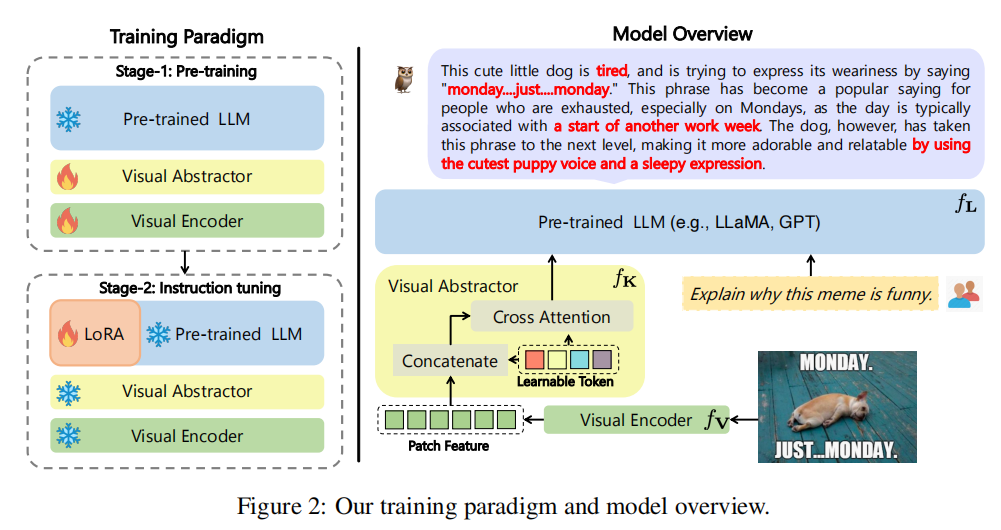
模型的整体框架如上图所示,图像经过视觉编码器之后得到patch级别的特征,然后通过一个视觉摘要器得到降维特征,这里和BLIP-2的思想类似,但是论文里居然没有介绍清楚??
他们的mPLUG-2模型我也写过博客介绍,那篇论文的模型框架在文中就没有解释清楚,这篇论文的Visual Abstractor也只是在论文里给了个图,两篇论文的一作都相同,感觉赶工严重,有为了专门蹭上热度的嫌疑。
总之,得到视觉的prompt之后,和Instruction组合成输入,送到LLM中让模型输出。
他们也是进行两个阶段的训练,第一阶段为多模态预训练,他们说提出了一种新颖的训练范式(但是……别人都已经用了,没怎么新颖啊……),学习和,冻住。第二阶段是指令微调,冻住所有原本的参数,在LLM上进行LoRA微调。他们说这也是一个新颖的视觉-语言联合指令微调策略。然后还说这种方式不需要视觉-语言模型的重新对齐(你都把视觉编码器和提示生成器一起训练了,那肯定不需要重新对齐了呀……)
mPLUG-Owl使用ViT-L/14作为视觉编码器,使用没有经过指令微调版本的LLaMA-7B来训练(用来证明模型的有效性和泛化性,同期的miniGPT-4和LLaVA都用了Vicuna),总参数量7.2B。
第一阶段的训练使用了LAION-400M、COYO-700M、CC、COCO,以2.1M token的batchsize训练(好像没见过以token计数的batchsize)。第二阶段的训练同时使用文本的指令数据和多模态的指令数据,文本的来自Alpaca、Vicuna和Baize,多模态的来自LLaVA。训练没有突出时长的。
对于实验结果,他们构建了OwlEval评价数据集,呃……其中包含50张图片、82个人工构建的问题,部分图片还有多轮的问题。问题包含了自然图像理解、表格、流程图、OCR、多模态创造、知识QA、 referential interaction QA。因为缺少较好的评价,所以使用了另一个论文Self-Instruct中使用的人工评估方法。
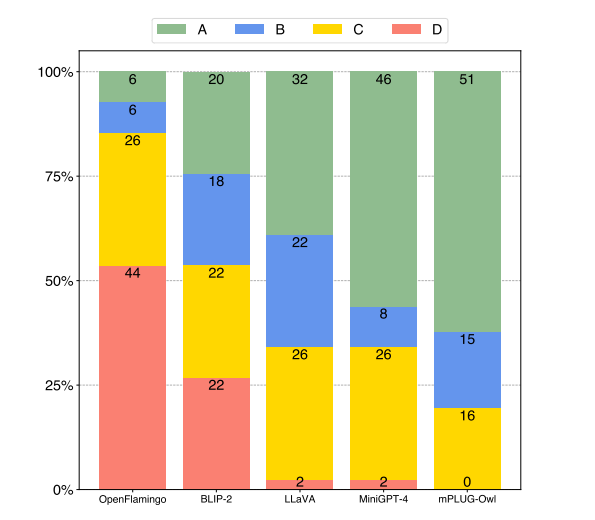
同样,他们提供了Demo可以自己跑例子,这里给出比较有趣的多语言的例子:

**除了论文里说的,他们还进行了多图/视频数据的训练和多语言的训练,但是没有发布。**在5.5号他们在HuggingFace上的Demo已经可以支持视频输入了,但是实测效果不是特别好。
总的来说,作为国产的模型,开源做的还是很不错的,但是论文撰写和实际效果还是有点差,让人觉得像是在赶工,希望在沉淀之后这个模型能更好。
VPGTrans
论文链接:Transfer Visual Prompt Generator across LLMs (arxiv.org)
项目主页:VPGTrans
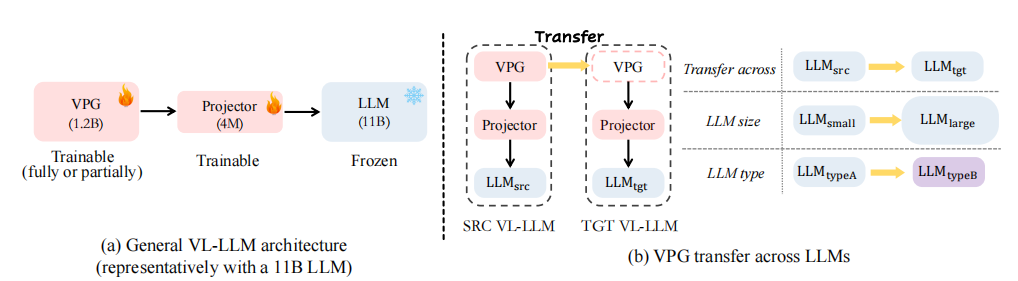
清华和新加坡国立大学的合作论文,这篇文章将现在的多模态LLM划分成了视觉提示生成器(Visual Prompt Generator,VPG)、Projector和LLM三部分,VPG用来提取视觉Prompt,Projector用来转换维度。这篇文章的主要贡献在于提出了有效的在多个LLM之间迁移VPG的方法,可以在更少训练数据和时间的情况下得到相当或更好的结果。同时,这篇文章的写作虽然有点花里胡哨,但是整体逻辑十分清晰,汇报了许多有趣的发现。

论文一开始总结了多模态LLM的预训练范式如下表:

论文主要研究如何在不同的模型中迁移VPG,他们使用了两阶段的迁移学习策略,接下来根据他们行文逻辑进行介绍。
作者首先通过实验发现使用其他模型训练好的VPG初始化可以加速训练。这个发现比较普通,因为有更好初始化参数肯定就学地更好。
然后,作者发现对projector进行warm up可以加速训练,这里warm up就是冻住除了projector以外所有参数先训练个3轮。但是warmup也是一个耗时很长的步骤,所以论文之后会使用更好的方法,这里先按下不表。
作者之后又发现,只调projector是不能得到很好的迁移效果的,毕竟参数量小。
由于视觉prompt其实就接近了word embedding,所以作者尝试学习一个简单的word embedding converter,通过余弦相似度作为损失,将LLMsrc每个词的embedding转化为LLMtgt。实际上,就是将一个模型的嵌入语义空间转换到另一个模型的嵌入语义空间,学习到这个转换的函数后,就可以将新的projector替换成旧的projector+converter,在数学上后者可以合并,所以就和原来的形式相同了。作者在实验这个方法后发现有效,但是又发现这个方式并不能取代warm up。
所以作者又探索有没有更快的warm up的方式,他们惊讶地发现使用5倍与原始值的大学习率来warm up projector可以得到快速的收敛。(原文说是Extremely large learning rate,但是……学习率不是按照10的倍数调吗?5倍好像也没有特别大吧)。
根据上面的实验经历,作者得出了正式的二阶段的VPG迁移方法:
- 阶段一:Projector Warm-up
- 继承VPG的参数
- 使用Converter的方式进行projector的初始化。Converter的训练十分简单,以余弦距离为损失,最小化每个词在转化后与对应词的嵌入特征距离。最后合并。
- warm-up训练,使用5倍学习率训练1轮足以。
- 阶段二:直接微调
- 冻结LLM,直接对VPG和projector进行微调。
作者整体使用BLIP-2的框架,进行了大量的实验,包括从小模型迁移到大模型,从一种模型迁移到另一种模型,证明了这种方式的有效性,具体可以看原文。最后,他们使用这种方式,把BLIP-2与预训练的OPT6.7B迁移到了LLaMA7B上,得到了VL-LLaMA7B模型,相同的方法还构建了VL-Vicuna模型,并使用了MiniGPT-4的数据来微调。
总结
BLIP-2开创的这一套由LLM构建多模态LLM的训练范式十分有效,在将来这种范式可能会被更多的研究。目前进行多模态LLM的训练,数据上有LLaVA的大多模态指令数据集,也有MiniGPT-4的小人工多模态指令数据集,可以初步支持多模态LLM的训练。而且LLaVA使用的一套数据集构建流程还可以扩大到更多的数据,以取得更好的效果。训练上,VPGTrans提出了一套高效的迁移策略,mPLUG-Owl使用的更大范围的微调也能提升性能,进一步降低了研究的门槛。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!