论文笔记 mPLUG-2:A Modularized Multi-modal Foundation Model Across Text, Image and Video
本文最后更新于:2023年3月21日 上午
mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
论文链接:mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video (arxiv.org)
代码链接:(即将开源在这里,和前作在同一个库)alibaba/AliceMind: ALIbaba’s Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab (github.com)
我的介绍其前作mPLUG模型的博客:论文笔记 mPLUG Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections - Kamino’s Blog
阿里巴巴达摩院于23年2月发布的大规模视觉-语言预训练模型——mPLUG-2,相较于前作mPLUG,本次将模型拓展到了视频领域,总共在30多个下游任务上进行试验,并取得很多SOTA。并且本作没有像前作那样突出减少运算时间,而是在训练效率和有效性上有长进。mPLUG2是一个多模块结合的模型,通过不同的模块能够应对“模态纠缠”的问题,不同任务可以选择性地使用部分模块。
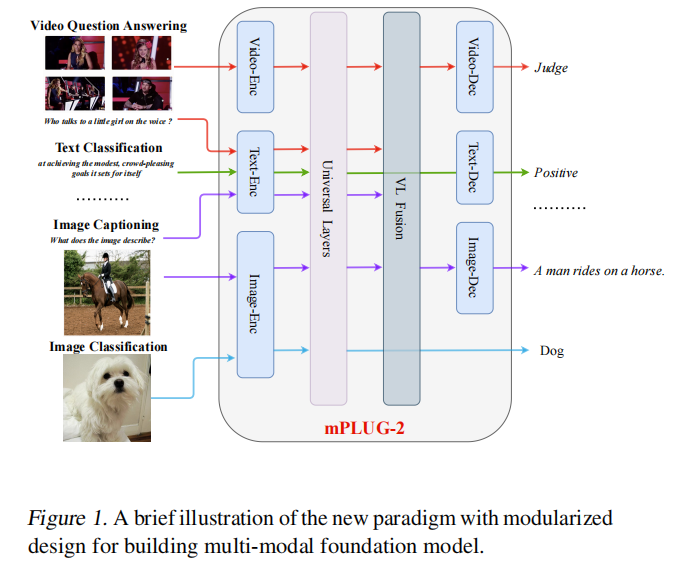
简介
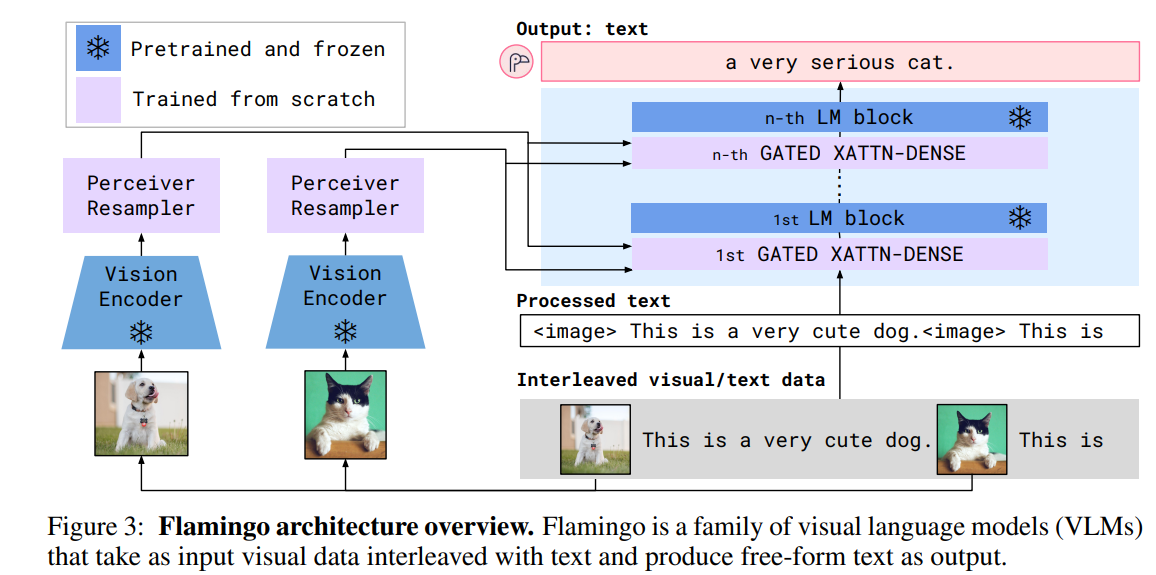
之前的foundation模型(如下图的Flamingo模型,用一个统一的解码器)使用单个网络来处理多模态数据,企图达到多模态间的合作,然而这样会因为不同模态任务之间的差异而造成“模态纠缠(modality entanglement)”,模态纠缠指的是不同模态的信息会互相干扰,单模块的网络很难做到权衡不同模态对某个特定任务的影响。
不是很理解模态纠缠,但是至少人家是这么说的,并且有一篇相关文献,假如我读懂了会更新到博客上:What makes joint training of multi-modal network fail in deep learning?(provably).
mPLUG2相较于Flamingo的话,就是把不同模块分开了,有共享参数的编码器Universal Layer,也有多模态融合的Fusion Layer,还有用来做生成任务的解码器。这个灵活的框架使该模型比其他模型涵盖的任务更加广泛:
最终作者在保证模型大小和数据量大小还算正常的情况下,打败了各路之前的SOTA,作者特别吹了一下在Video Caption任务和Video QA任务上的成果,由于我是做Video Caption的,他这个成果可以说是非常SOTA了,超过了之前我在另一篇博客介绍的GIT模型。
方法
整体框架
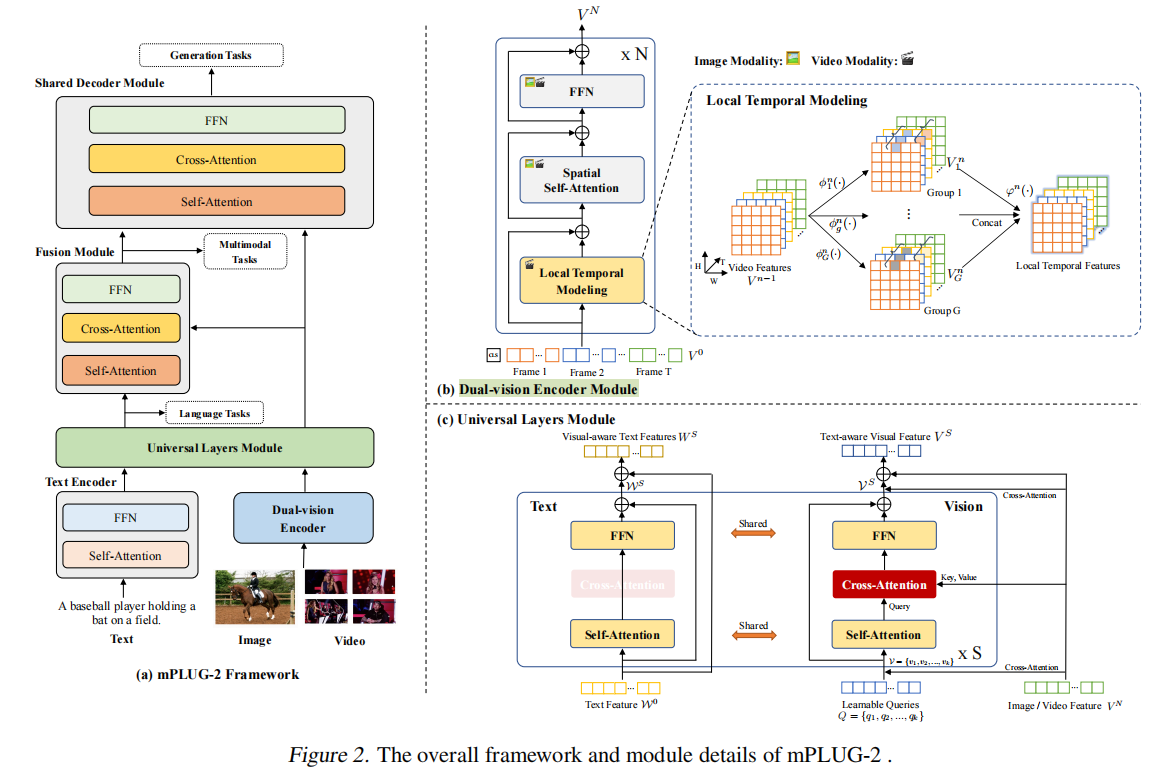
图2是mPLUG更详细的整体框架图,从下往上看:首先文本侧有一个比较普通的编码器(基于BERT),视觉侧为了适配视频进行了改进,是一个Dual-vision编码器,这个编码器会建模视频的空间和局部时序信息。之后,两个模态的表征会送到Universal Layers Module中,这个模块将不同模态通过编码映射到共享的语义空间中,并在此处进行多模态语义对齐,这个模块还没有进行特征融合,所以可以用在各种单模态的任务上。对于多模态任务,则需要一个额外的融合模块来融合不同模态的信息。要做生成任务时,无论是融合了的还是没融合的特征都可以通过Shared Decoder Module进行解码。
这种搭积木式的网络能够适应多个任务,下面据一些例子:
- 语义情感分类:只需要文本的单模态任务,将文本通过文本编码器进行编码,然后通过Universal模块进行再次编码,然后接分类器得到结果。
- 图像分类:只需要视觉的单模态任务,将图像送到视觉编码器进行编码,然后通过Universal模块再次进行编码,然后接分类器得到结果。
- Video Captioning:多模态任务,视觉和文本各自送进自己的编码器,然后通过Universal模块再次编码,然后送入Fusion模块进行融合,最后作为Decoder的Cross Attention的输入进行解码。在推理阶段则是自回归式生成,会使用“”What does the video describe?”来作为prompt。
Dual-vision Encoder
这个模块把视频和图像先分成L长的不重叠的token,然后额外添加[CLS],并加上可学习的空间位置编码。要对时空token进行建模需要大规模数据支持,所以作者这里简化了问题,将其解耦为分别学习空间和时间,并提出了一个Local Temporal模块来对局部时序进行建模。
公式上是这样的:
直接看图比较清晰:
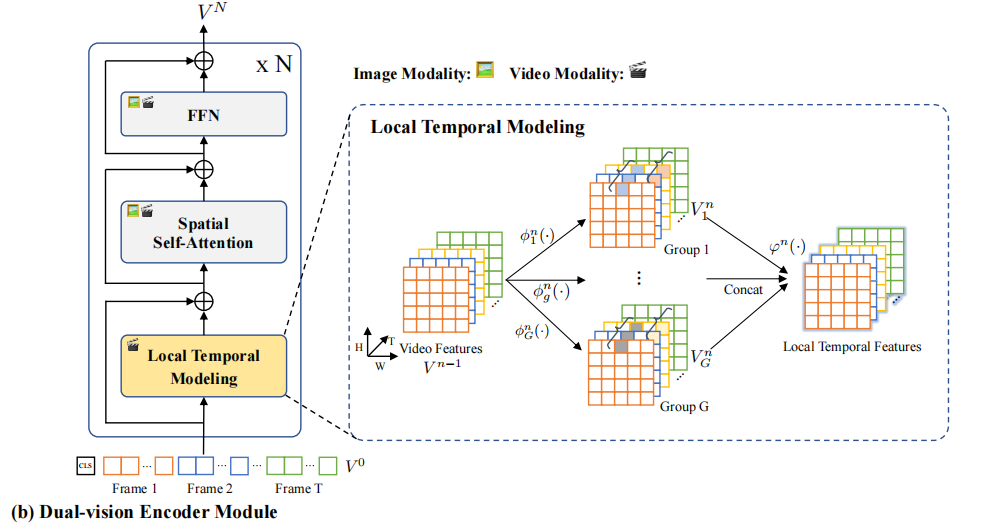
和ViT来说也就是增加了Local Temporal这个模块,这个模块通过对相同位置的token进行分组融合来交换时间信息,该模块公式:
公式省略的层数的,其中是组的卷积核,是将隐藏维度转换到的线性映射函数,然后这个卷积的操作论文里没详细说,反正最后每个组的concat在一起再经过一个线性映射层就得到最后结果了。
这论文也写得太简略了……
Text Encoder
是BERT。
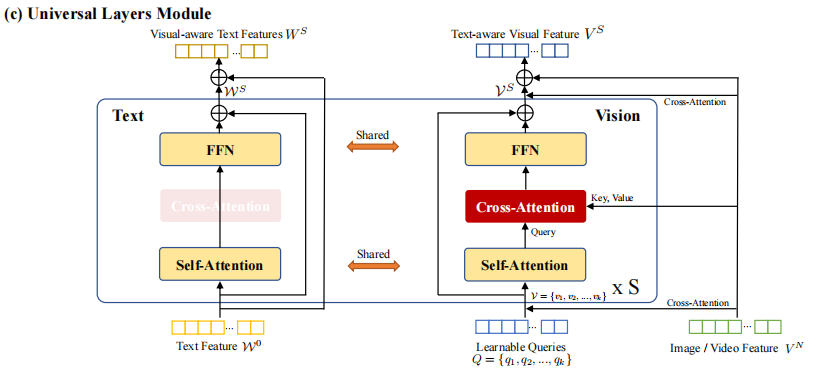
Universal Layers
这里不直接对视觉的token进行self-attention,而是通过k个learnable的query来浓缩信息并提高效率,这一块和BLIP2的结构也很相似。如图,Learnable Query自己之间做self-attention,然后通过Cross-attention来选择性得到Image/Video的信息,然后进入FFN。
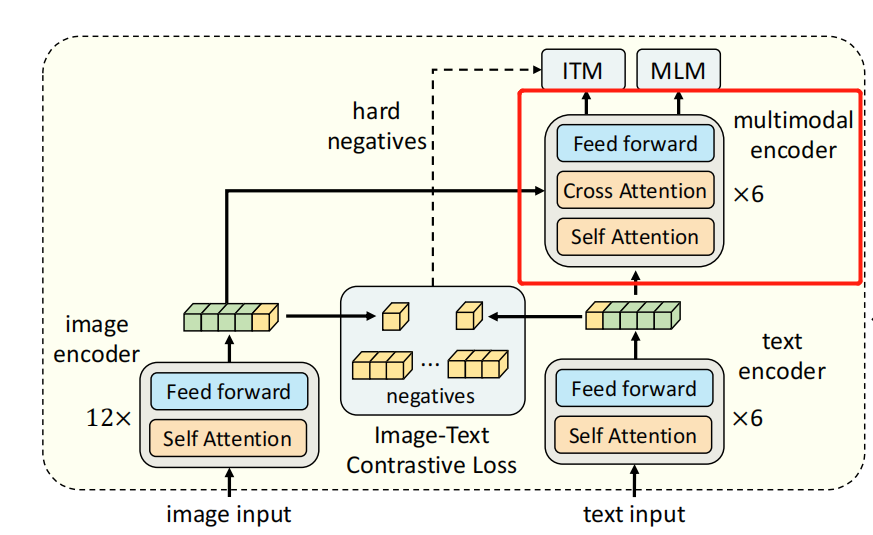
Fusion
这里使用ALBEF的多模态融合模块,如下图红色框框住的部分,视觉侧特征通过Cross Attention进来,文本侧特征则是走Self Attention。
这里原文也很简略,让人不明所以。到底哪个是SA的输入,哪个是CA的输入????
Specifically, the fusion module takes the text embeddings from the universal layers module as the input. Then, the text-aware vision embedding cross-attends to the visual-aware text embeddings in language-shared common space. By cascading the Transformer blocks with cross-attention layers, fusion module is able to yield multi-modal vision language representations
Shared Decoder
一个简单的带CA的Transformer Decoder。
Objective
-
Language Loss
在图中标注的是在universal layer后面进行MLM作为Language Loss,但是文中又说是text encoder的loss。
-
Multi-modal Loss
包括Vision-Language-Matching和Vision-Language Contrastive。都是常规操作。
-
Instruction-based Language Model Loss
就是自回归生成语言的loss,在前方通过一些prompt作为Instruction。
实验
本文进行了非常多的任务,实验也自然有非常多,这里挑选几组实验:
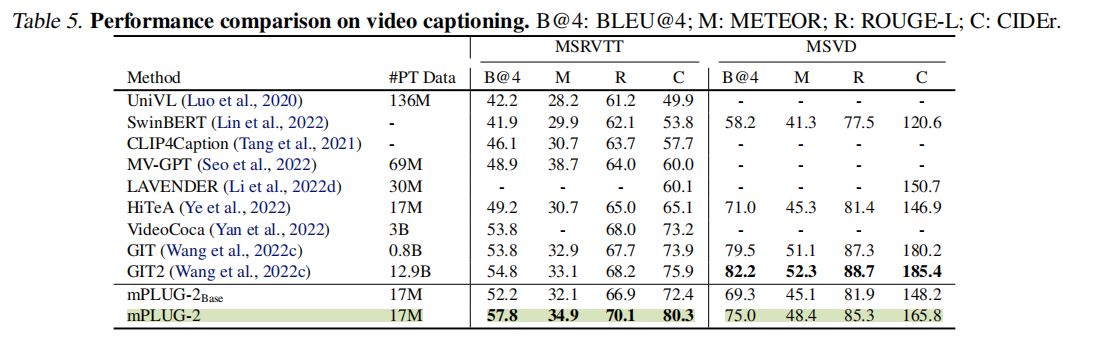
Video Caption
视频描述的任务上可以说是非常SOTA了,在CIDEr上又拔高了一点,此前的SOTA是GIT。
但是这里根据附录来看,mPLUG是默认启用了CIDEr optimization(见我这篇博客介绍的SCST方法),但是GIT没有,假如GIT也进行微调的话,感觉这个模型在指标上并不会超越太多。
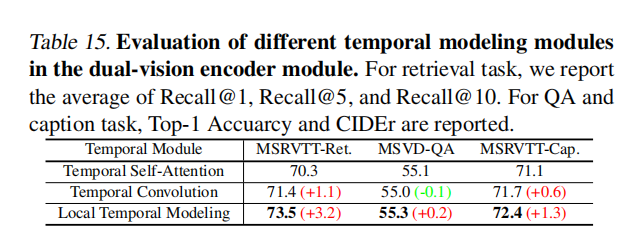
Local Temporal Modeling
作者统一了图像和视频的输入时,使用了Local Temporal Modeling作为时序的建模,而像GIT这种模型只有很简单的附加时序编码,作者的消融实验证明这样添加效果是好的。
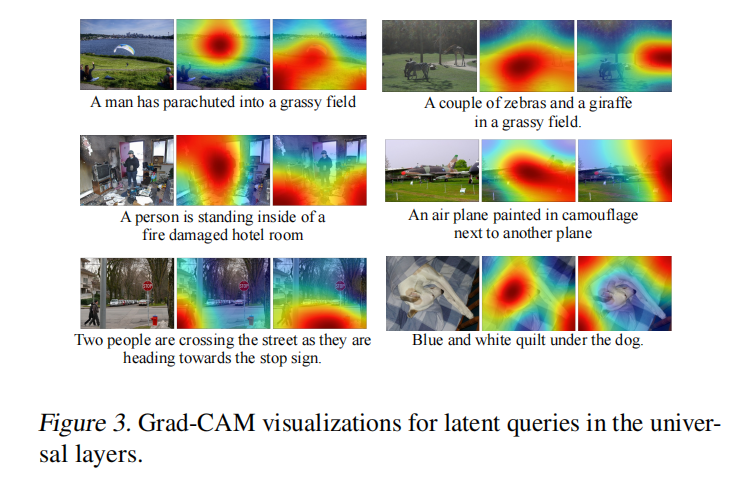
Learnable Queries
作者使用Grad-CAM方法可视化了learnable queries的attention map。
模型大小分析
暂时没给代码,无法分析大小,只能根据论文来猜测。
文章训练了mPLUG-2-base和mPLUG-2两个版本,base版本使用VIT-base和BERT-base作为编码器,而更大的版本则使用ViT-Large和BERT-Large。后面的维度也随之变化,分别为768和1024,universal layer是2层Transformer,fusion模块则分别是3和6层,解码模块都是12层Transformer(这么一看参数还真多……)。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!