论文笔记 BLIP-2 Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
本文最后更新于:2023年3月1日 下午
论文笔记 BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
代码链接:LAVIS/projects/blip2 at main · salesforce/LAVIS (github.com)
Demo:HuggingFace、Colab(免费资源不够直接运行)
Salesforce团队于2023年1月发布的大规模视觉-语言预训练模型,在前作BLIP的基础上发展而来,BLIP2展示了一种利用已有的大型图像编码器(如CLIP)和大型语言模型(如OPT、GPT)的训练方式,其中这两个模型在训练时均不更新参数,而是只学习连接两者的一个仅有186M参数的Q-Former。这种架构能够适应并利用如今的各种图像编码器和语言模型,并且由于冻结了大部分参数,在计算上也有巨大优势。BLIP2最终在各个方面都取得了SOTA的表现,并且优秀的架构设计能适应更多种的应用。
介绍
近年来视觉-语言预训练(VLP)的研究发展迅速,CLIP、ALBEF、BLIP、SimVLM、BEiT、Flamingo等都是很优秀的模型,然而在预训练中的复杂计算仍然是一个问题。视觉-语言的研究正如其名是联系视觉和语言的研究,所以很自然会想到:能不能将视觉上的单模态模型和语言上的单模态模型结合在一起?
BLIP2就是结合两个方面各自的单模态模型的一个工作,具有高通用性和高计算效率的特点。
众所周知,跨模态训练中跨模态对齐很重要,然而由于计划将语言模型参数冻结,而其并没有见到过视觉的数据,所以这种对齐变得十分困难。已有的方法(Frozen、Flamingo)使用了图像到文本的生成损失,本文认为这不足以弥补模态差距。
模型架构
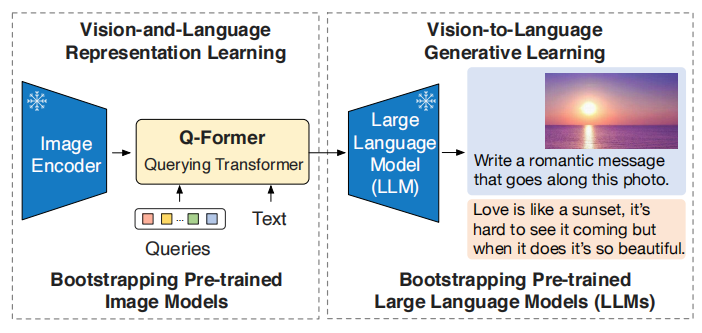
上图为BLIP-2的架构,BLIP-2在冻结的图像编码器和语言模型间加入了一个Querying Transformer,训练也被分成了两个阶段,第一阶段是利用预训练图像编码器的视觉-语言表征学习,第二阶段是利用两个冻结模型的视觉-语言生成学习。
Q-Former
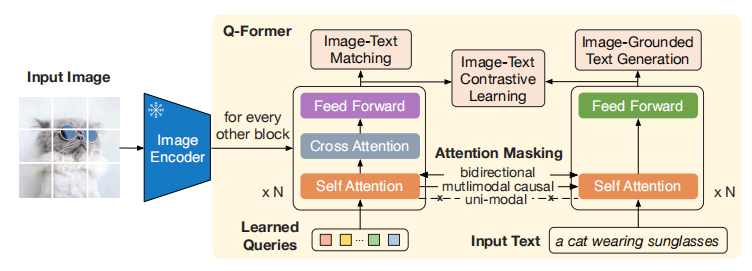
Q-Former的具体结构如上图,其包含了一个共享参数的Self-Attention、一个Cross-Attention和两个不同的前向传播层,类似的结构在前作BLIP中也有体现,他们发现在Transformer中,不同模态的SA层可以共享,而前向传播层分开更好。
模型会学习32个768维的Query,即输入进Q-Former左边SA层的数据,这些token将通过CA层获取到视觉信息,并通过SA层于语言进行交互。从下往上叙述,SA层就是普通的SA,但是使用了三种Attention Mask:双向mask、多模态因果mask、单模态mask。
- 双向mask就是没有mask,每一个输入都能对其它输入施加注意力。这个mask用作之后的Image-Text Matching任务。
- 多模态因果mask就是query只能对query施加注意力,文本端则是做Language Modeling用的因果mask,所以对应的是Image-Grounded Text Generation任务。
- 单模态mask就是每个模态只能对自己模态施加注意力,之后用在Image-Text Contrastive Learning任务上。
CA层query将会学习到图像的知识,此时原本图像的很长的token序列将会被减少到32个,在这个层面也浓缩了信息,降低了计算复杂度。要注意CA层是间隔插入的,比如第0、2、4层。
Feed Forward层根据BLIP之前的研究包含了主要的参数,所以每个模态用独立的前向层更优。
算上32个768维的query,总共有188M可学习参数。
一些小细节:
- 模型的三个任务要前向传播三次
- 论文中使用的Image Encoder是ViT-G(1408维)和ViT-L(1024维),官方只开源了ViT-G的版本,但Q-former主体是768维的,不同维度的特征只会在CA层变成768维。
第一阶段训练:视觉-语言表征学习
此阶段进行三个任务:
- Image-Text Contrastive Learning(ITC)和CLIP类似,视觉侧通过单模态mask来避免了信息泄露,由于视觉测没有
[CLS]token,所以会选择32个query中与文本[CLS]相似度最高的那个来进行对比学习。 - Image-grounded Text Generation(ITG)是生成式的训练,这里用到的多模态因果mask和UniLM的设计类似,文本的输入额外添加一个
[DEC]token来表示解码开始。 - Image-Text Matching(ITM)是细粒度的对齐,判断图像和文本是否匹配的二分类任务,这个过程中32个query会得到多模态的信息,然后每个query通过一个二分类线性分类器得到logit,再平均32个得到最终的分数。这里和其他文献一样会采用hard negative mining策略。
第二阶段训练:视觉-语言生成学习
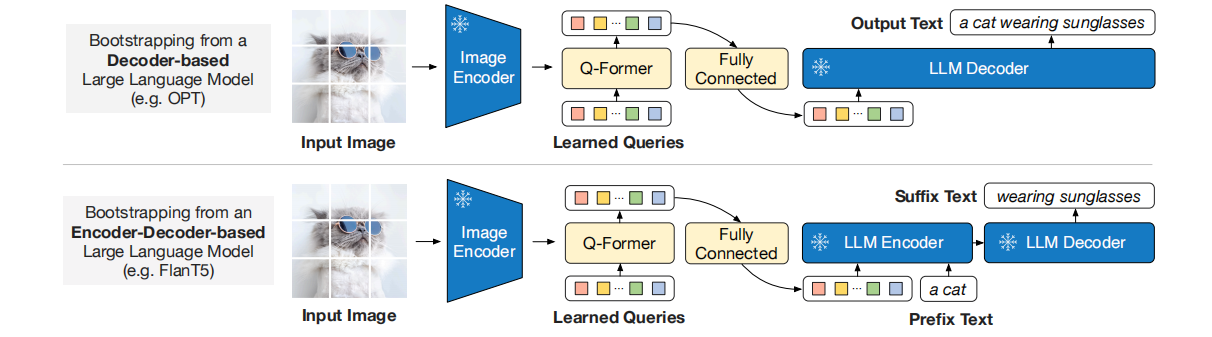
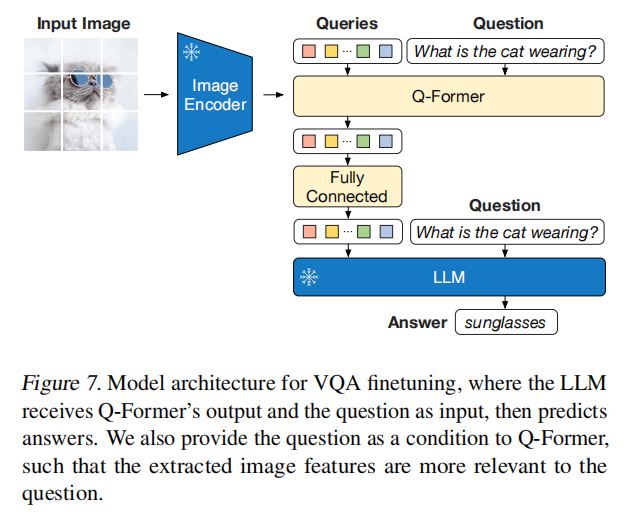
第二阶段还会引入一个冻结参数的LLM,目前的LLM分成只使用解码器的(GPT)和编解码器都用了的(T5)模型,如图是两种训练的方法。对于基于解码器的LLM,经过Q-Former的query通过全连转换维度,然后进行LM训练;对于基于编解码器的LLM,全连后进行前缀LM训练,就是会额外添加前缀文本。
这个阶段中,之前学习到的query被当做了LLM的soft visual prompts,用来控制LLM的输出。
模型训练
训练的数据集使用了129M的图像数据,数据处理和前作BLIP一样,并利用前作的方法来过滤数据。
Q-Former使用BERT-base初始化,图像编码器使用了CLIP和EVA-CLIP(提取特征时,去掉了ViT的最后一层),语言模型使用了OPT(仅解码器)和FlanT5(编解码器)。
使用16张A100(40G),最大的模型在第一阶段训练6天,第二阶段训练3天。
实验分析
Zero-shot
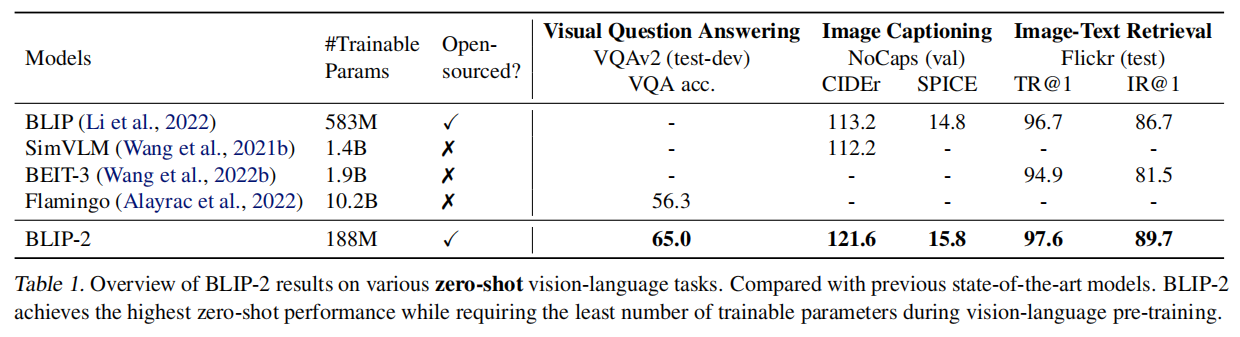
如图,BLIP-2既开源、效果又好,而且徐娜林参数还特别少(特别是和边上那个10.2B相比)。BLIP-2全面支持prompt的应用方式,文本的prompt就添加在LLM的visual prompt后面就行:

上图这些示例的效果还是很不错的,可以在HuggingFace和Notebook中自己尝试,实测速度还是很快的。
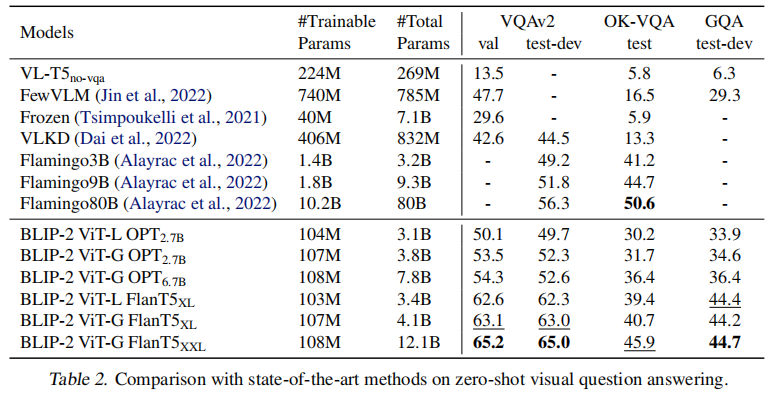
替换视觉编码器和语言模型的结果如上,实验说明更优秀的视觉编码器和语言模型能够带来更好的效果,OK-VQA数据集上的效果没必过Flamingo80B的原因应该是其使用的70B参数的Chinchilla语言模型有更多的知识。
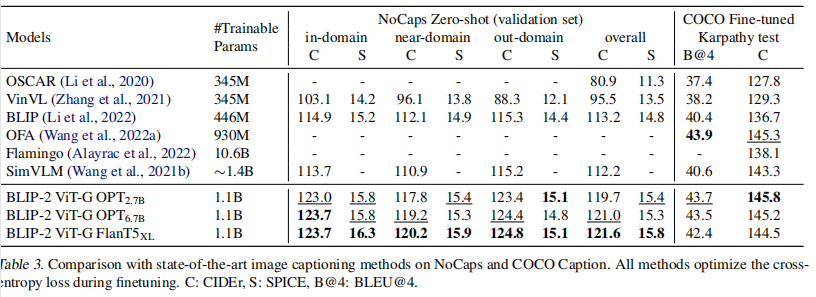
Image Captioning
进行图像描述时,本文微调了图像编码器和Q-Former来得到最好的效果,这一块在NoCaps上表现不错,但是在COCO上不是最好,但也没差多少。Finetune的成本还是略高。
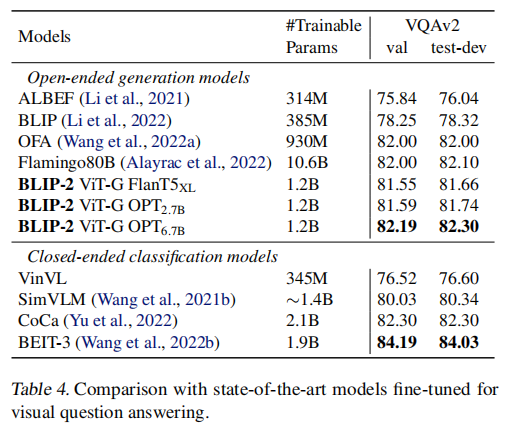
VQA
同样微调图像编码器和Q-Former,和其他牛逼模型一样,将VQA看作是生成式任务,效果很不错,但能微调语言模型的那些模型更好一点,可能是因为数据集的限制,生成的文本要完全符合才算上正确率。
跨模态检索
跨模态检索不需要语言模型,所以使用图像编码器和Q-former进行微调。和其他使用了ITC、ITM的方法一样,先ITC选出前k个,然后使用ITM来进一步判断。
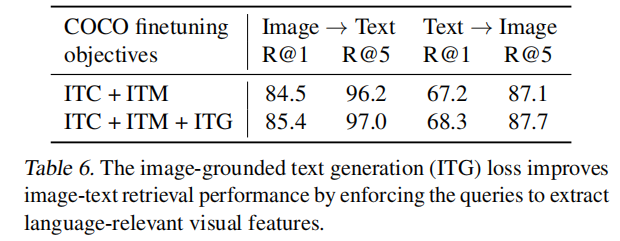
微调时进行了ITC+ITM+ITG三个任务,虽然用不到ITG,但是消融实验证明加上ITG效果更好。
BLIP-2的限制
BLIP-2对于in-context的VQA性能不佳,可能是因为训练数据集缺少类似数据。作者说未来会建立个和Flamingo的M3W数据集类似的数据集。
in-context就是考虑上下文的VQA,会考虑之前的提问和回答。
另外BLIP-2没改掉LLM喜欢瞎编的毛病。
🌀参数分析
Q-former
下面我把Q-former的第一层参数列出来,删除了Qformer.bert.encoder.layer.0的前缀。
可以看到,第一层包含自注意力(attention)和互注意力(crossattetntion),每个注意力层包含query、key、value、layernorm和一个融合多头的dense(但是这里并没有多头),其中互注意力层的key和value由于是视觉侧过来的,要维度变化。
而之后的intermediate就是Feed forward层,先升到3072,再降回768,由于有两个模态,所以也有两个intermediate。
这样的一层有15.16M参数,没有互注意力的层有11.81M参数,每个模态的前项传播层为4.72M参数。
1 | |
EVA CLIP ViT-G
BLIP2用的图像编码器backbone,来自CVPR2023的论文,EVA: Exploring the Limits of Masked Visual Representation Learning at Scale,代码链接
参数1.0B……🤔,论文用的fp16。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!