论文笔记 CoCa 与 VideoCoCa
本文最后更新于:2023年3月22日 下午
论文笔记 CoCa 与 VideoCoCa
本文介绍两篇论文,分别为CoCa: Contrastive Captioners are Image-Text Foundation Models和VideoCoCa: Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners。
CoCa和VideoCoCa都是Google Research提出的多模态预训练模型,前者于2022年年中发布,后者于23年初发布。CoCa的名字来源于Contrastive和Caption,顾名思义就是通过对比学习和生成描述这两个任务来进行训练,从而使模型能够适应更多的包含单模态和多模态的下游任务。VideoCoCa就是将CoCa从图像-文本的训练延伸到视频-文本训练,从而更加适应视频领域的一些任务。
三种多模态学习中利用自然语言进行监督的方法
首先回顾一下多模态学习中利用自然语言的方法,作者将其分成三类:单编码器分类、双编码器对比学习和编解码器描述生成。
单编码器分类就是用交叉熵算分类任务的loss,这个就是和单模态里一样,没什么好说的。
双编码器对比学习就是以CLIP为代表的,通过两个编码器分别对图像和文本进行编码,然后计算InfoNCE的loss。
编解码器描述生成需要模型拥有解码器,才能自回归式地生成描述,在训练时采用teacher-forcing的方式进行训练。有时也会叫做LM或者PLM。
CoCa的Contrastive Captioners Pretraining
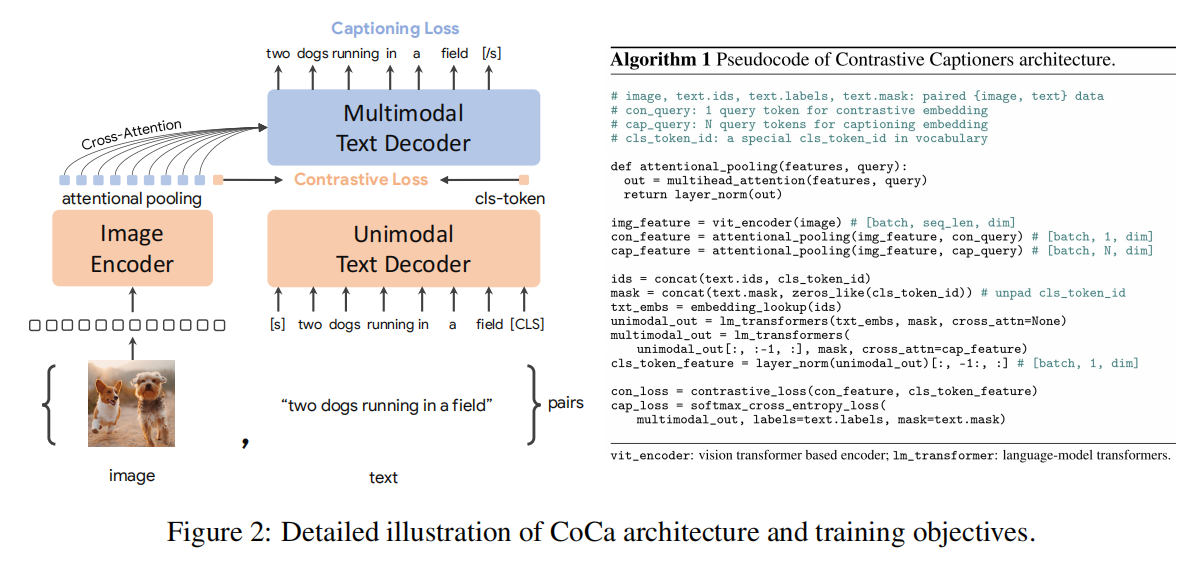
CoCa就提出了Contrastive Captioners Pretraining这个概念,如图所示,模型拥有一个单模态的Image Encoder,还有一个Decoder。Decoder被分成了Unimodal和Multimodal两部分,Unimodal没有交叉注意力,用来编码文本,两路单模态的输出用来做Contrastive,而Multimodal有交叉注意力,用来融合特征进行Captioning。最终的loss如下:
接下来介绍一些模型的细节:
Attention Pooler
上图可以看到,从Image Encoder出来的结果哟啊通过attentional pooling才会进入下一步,这个Attention Pooler就是一层的多头自注意力层,其使用个可学习的query作为Q,Image Encoder出来的token作为K和V,这样就能得到固定长度的query。文中对于Contrastive任务使用1个query,也就是期待这个query学习到整体特征,用来与文本的[CLS]作对比学习。而对于Caption任务,则使用256个query,期待其浓缩一些信息。
Unimodal Text Decoder
这一块其实没什么好说的,但是很重要的一点是,为了在一次forward中进行Caption任务,所以在这一部分就需要使用Causal Mask以防止信息泄露,也就是说每个文本token只能attend之前的token,所以这里[CLS]被放在了最后一位。
这种“反BERT”的行为在编码上肯定是没有双向的好的,但是由于其使用了大量的数据集训练,这个模块见的文本多了应该也没差多少,而节省下来的forward就能提升预训练的效率。
预训练的设置
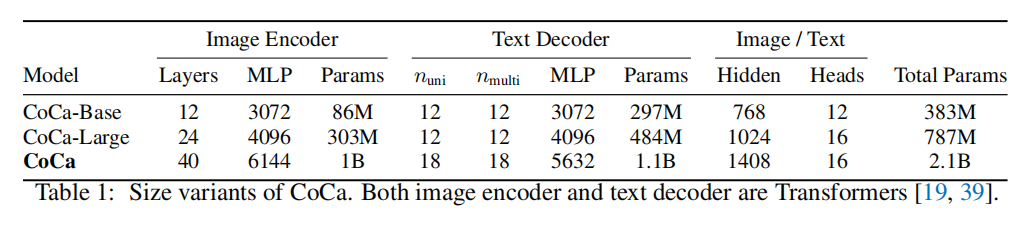
如下表,CoCa有多种模型大小,从383M到2.1B的参数量。
训练数据上,CoCa融合了JFT-3B数据集、ALIGN数据集,并将分类标签组合成prompt进行训练。这里CoCa甚至没有初始化Image Encoder。论文里提到的大规模训练的方法咱也不懂,就不说了。Loss上,Caption的loss权重为2,对比的loss为1。
CoCa for Downstream Tasks

CoCa可以通过如图不同的组合,以三种方式进行利用(Zero-shot、frozen-feature和finetuning)
同时CoCa这篇论文里就也涉及到了Video Action Recognition,zero-shot的方式就是做平均池化,而其他的方式就是在Image Encoder出来后再学习新的pooler层。
结果就是下面这个十一边形战士:
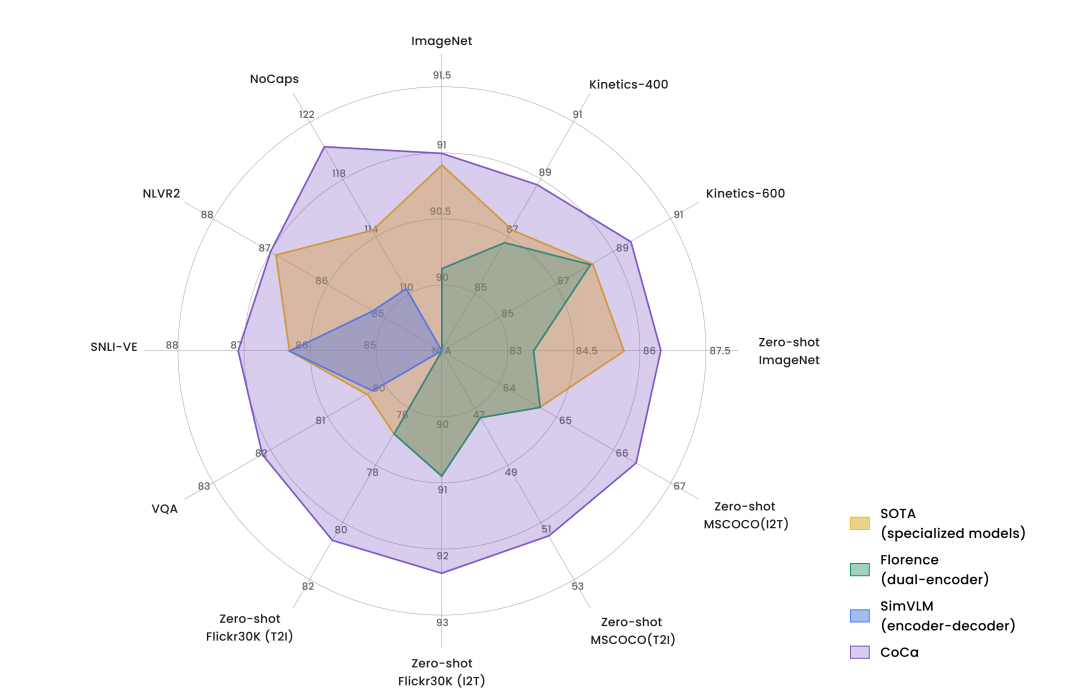
令人震惊的是这种图像专属的模型,在动作识别上展现出了很好的效果,直到我现在在paperwithcode上看(2023/3/21),CoCa还是Kinetics-700的第6名,甚至超过了后面为视频做优化的mPLUG-2(介绍可看我另一篇博客论文笔记 mPLUG-2:A Modularized Multi-modal Foundation Model Across Text, Image and Video - Kamino’s Blog)
由于实验太多,而且很多方向都不了解,所以就不列出来了,下面着重看一下消融实验:
消融实验

- (a)是分类任务和描述生成任务的实验,这里在JFT上训练分类任务,结果发现prompt+Caption的任务能包含图像分类任务。
- (b)是训练目标的消融,在算力消耗不增加太多的情况下提升性能。
- (c)是训练目标比例,发现Caption这个loss还挺重要的。
- (d)是保证总decoder层数为12的情况下,改变单模态的层数,发现一半是最好的
- (e)是
[CLS]的设计,只用1个[CLS]就够了,不需要平均多个[CLS]或者平均整个句子token。 - (f)是attention pooler的实验,parallel是同时提取caption和contrastive的,cascade则是在caption的256个token的基础上再提取到最后的1个,实验证明后者更好。对于caption的query数量也做了消融,结果证明query越多越好(就是把Image的全部encoder弄去做CA),最后为了考虑计算量,使用了256个query。
从CoCa到VideoCoCa
VideoCoCa探索了将CoCa以最低的成本用到视频领域的方法,从李沐老师的衡量论文的角度来说,这篇文章新意度不高,但是比较有效地解决了视频上多个任务的问题。
VideoCoCa实验了四种将CoCa适配到视频领域的方法:
-
Attentional Poolers
通过Image Encoder得到patch级别的特征,之后继续按照原来CoCa的方法进行pooling
-
Factorized Encoder
这个方法在Pooler上添加了新的Transformer Encoder层,通过contrastive pooler之后能得到frame级别的特征,然后通过层Transformer编码器,之后送到CoCa的Decoder中。
-
Joint Space-Time Encoder
将Image Encoder扩展到处理个token,就是把多帧的token一起送到Image Encoder里面,原来只用处理个token,现在要处理个,计算量大幅增加,属于特征的早期融合。
-
Mean Pooling
和CoCa中用来做Zero-Shot Video Action Recognition的方法一样,平均池化掉时序维度,然后送到Decoder中。
在训练上也有四种方法:
- Finetuning(FT):加载参数后训练整个模型
- Frozen Eocoder-Decoder tuning(Frozen):只调节Pooler的参数
- Frozen tuning then finetuning(Frozen+FT):先只调节Pooler的参数,然后再全部参数finetune
- Frozen Encoder tuning(LiT):冻住Image Encoder的参数,调节剩余其他参数。
在模型的大小上,VideoCoCa不仅用了原来的3个版本,还增加了一个Small版,就是把Base版的Deocder从24层降到了12层。
VideoCoCa实验
适配方法
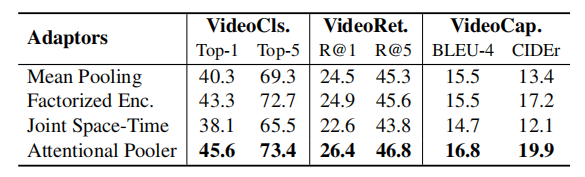
对于四种适配方法,作者在VideoCoCa-Small版上通过finetune的方式进行训练,可以发现Attentional Pooler的方法最好,无需添加任何新的模块就能达到最好的效果。
训练方式
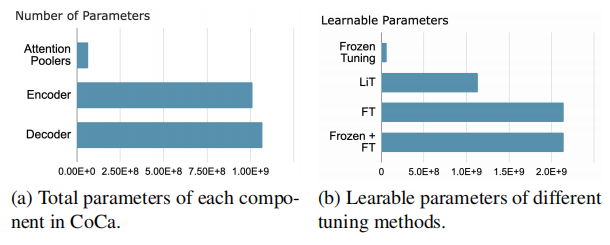
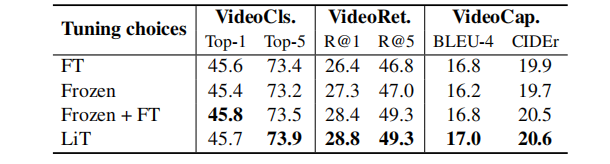
训练上的四种方式也进行了实验,Frozen的参数最少,效果在视频分类和视频描述上比FT更差,但是在检索上好一些,而结合Frozen和FT的在各个指标上都超过了两个单独的,但是最后的效果也没有LiT这种训练好。LiT的实验表明了原来CoCa的强大的ImageEncoder已经够用了,再训练下去反而效果不会更好。
训练数据混合
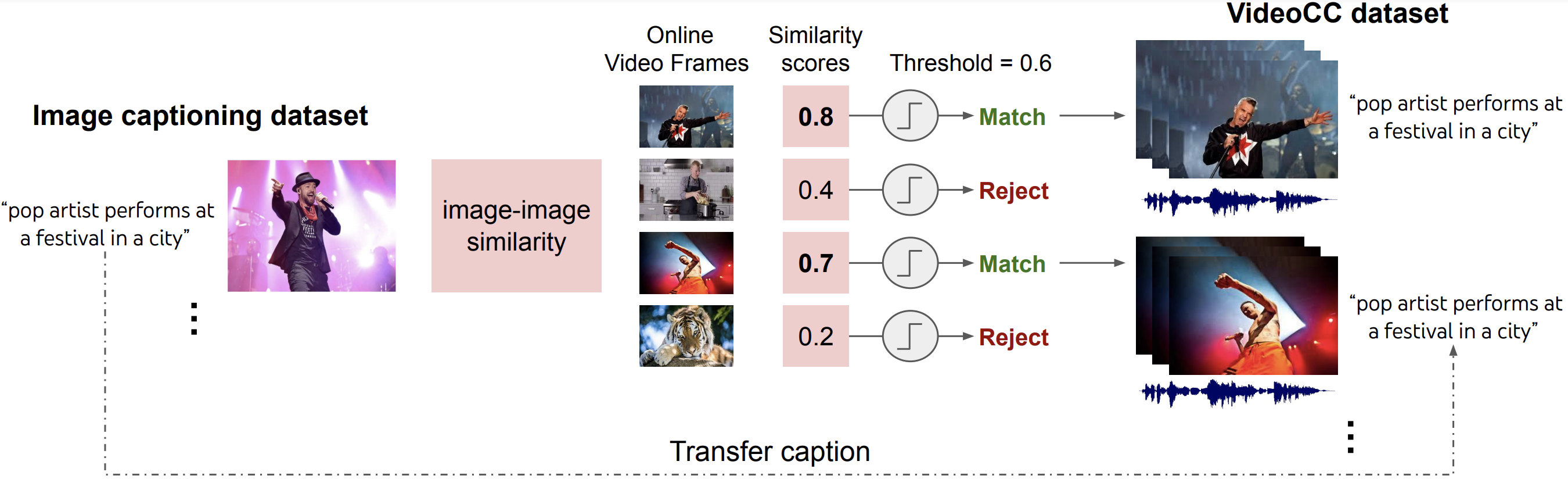
一直没提训练数据,VideoCoCa的训练数据尝试使用了VideoCC3M和HowTo100M这两个数据集,其中VideoCC3M是通过下面这种方式得到的,它利用Image Caption的数据集,通过图搜图的检索方式找到视频库中类似的帧,然后采取该帧附近的视频构成了VideoCC数据集。而HowTo100M就是教程性的视频数据集。
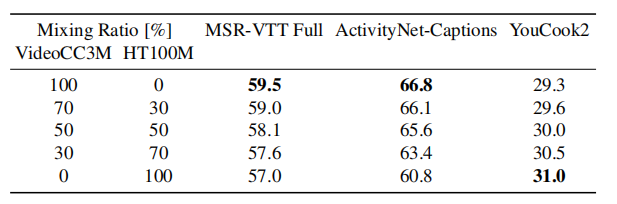
在混合的时候,作者发现越往HowTo100M上靠,YouCook2这种做饭教程类的效果就会越好,MSR-VTT这种开放域的视频数据集效果就会越不好,作者无法找到一个对三个数据集都是最好的比例,所以干脆就只用VideoCC3M数据集了(包括上面的实验都是用VideoCC3M)。
主要结果
下面的结果中:VideoCoCa默认是最大的2.1B的模型,VideoCoCa-Small用的是224和16patch的分辨率,而其他用的都是576和18patch的大分辨率。
VideoCoCa可以被用来做zero-shot的视频分类、跨模态检索任务和描述任务,还有finetune的描述任务和问答任务。在Zero-shot上,VideoCoCa的效果非常好,目前是在paperwithcode上位居前列。

以少量TFLOP上升的代价,VideoCoCa的各个参数版本在所有指标上都超过了CoCa(想必也是……),值得注意的是,VideoCoCa-L版本在一定指标上还比2.1B的CoCa更好。

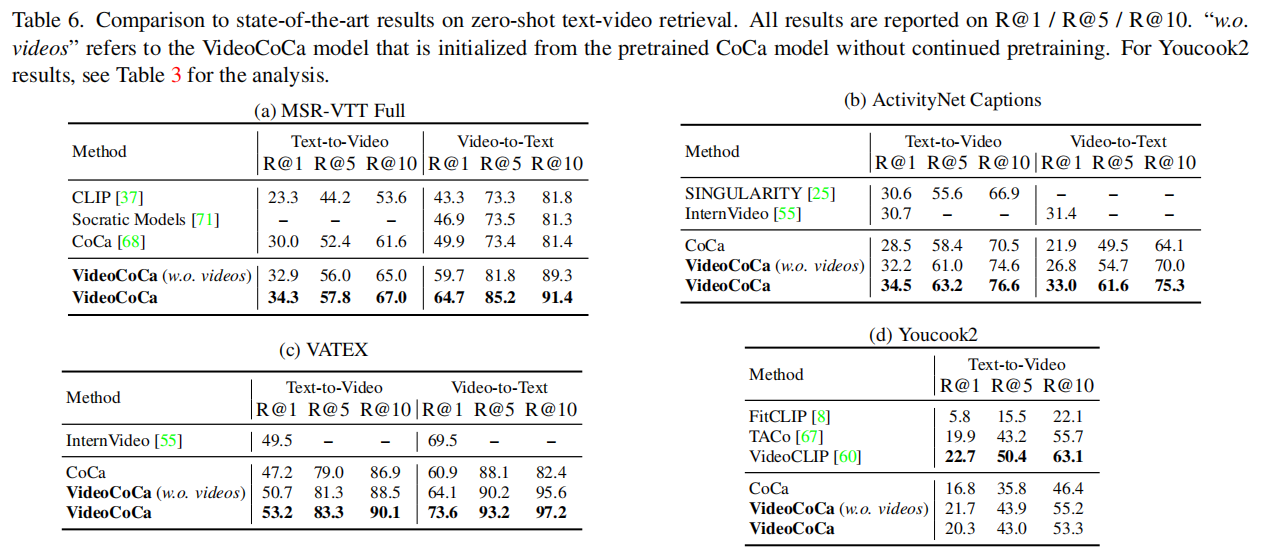
下面这个表是做zero-shot检索的,VideoCoCa在没有见过视频数据(就只是把token凑起来送进Pooler)的情况下,效果就有挺大的上升😓,然而还好在训练之后上升的更多了(YouCook2上不太好)。这里体现CoCa本身就有处理视频的潜力,特别是检索这种比较简单的任务。然后因为没在HowTo100M上训练,领域内的YouCook2数据集上效果就不太好。
下面是描述任务的结果,这里做zero-shot的貌似没多少,在finetune之后效果还是很好的(虽然用的是最大的模型)。

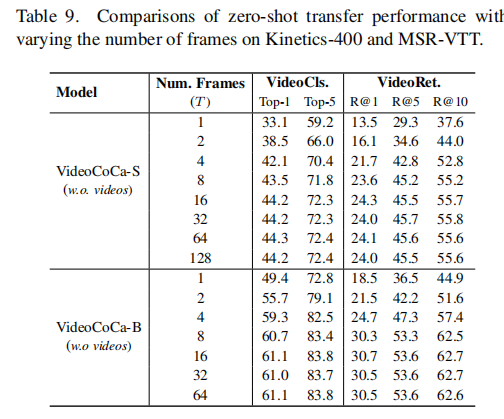
最后作者还做了个采样帧数的实验,说8帧这个数字很不错:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!