论文笔记 STOA-VLP:Spatial-Temporal Modeling of Object and Action for Video-Language Pre-training
本文最后更新于:2023年3月21日 上午
STOA-VLP:Spatial-Temporal Modeling of Object and Action for Video-Language Pre-training
论文链接:STOA-VLP: Spatial-Temporal Modeling of Object and Action for Video-Language Pre-training (arxiv.org)
代码地址:(刚建库,到目前尚无内容)whongzhong/STOA-VLP (github.com)
哈工大、腾讯、鹏程实验室于2023年2月挂到Arxiv上的多模态预训练模型,其通过对视频中的目标和动作进行时空建模来提升视觉-语言模型细粒度性能。模型提出了一个建模目标轨迹的模块和一个建模动作的模块,并相应添加了对齐目标轨迹-语言和对齐动作-语言的损失函数。
总的来说,这篇论文通过WebVid2M训出来的Baseline比较高,根据消融实验,几个添加的部分的贡献都不是很大,相同参数水平有GIT-L模型比它更强。并且,为了对目标和动作进行建模,这篇论文用上了目标检测模型,增加了模型复杂度,但感觉并没有得到预期的回报。并且实验中也没有对学习到动作轨迹的可视化。但是模型的主要思路还是可以借鉴一下的。
方法
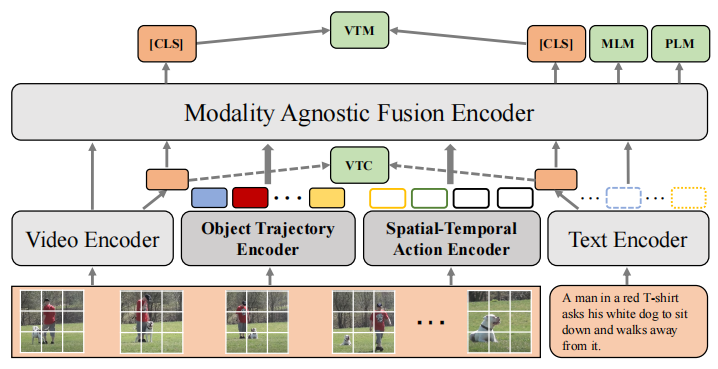
如图,模型整体由Video Encoder、Object Trajectory Encoder(OTE)、Spatial-Temporal Action Encoder(STAE)和Text Encoder组成。Video Encoder和Text Encoder就是普通的Transformer,就不详细介绍了。此外图中没提到的还有一个目标检测器——VinVL,用来预先提取好目标检测的标签和区域特征。(感觉全文有意淡化目标检测器)
Object Trajectory Encoder
视频中抽取T帧,每帧通过目标检测器提取置信度最高的top-K个目标,得到其标签和经过RoIAlign之后的区域特征,并添加上spatial-temporal positional embedding。之后再根据每种目标的所有帧的置信度总和来选择出top-N个用来建模运动轨迹的目标,那样就会得到一个长的目标特征。对于生成其相同长度的个Mask,每个Mask对应一种目标,且该目标的位置为1,其余为0。最后,在前面添加一个[CLS]作为整体特征,一个Object Trajectory序列就做好了,之后送进自注意力得到。
Spatial-Temporal Action Modeling
理解视频中行为的关键是理解场景中的目标、他们之间的联系和他们的移动。本文将图像编码器的中间层特征和object特征拼接成一个的序列,然后初始化M个可学习的action token作为query,将query与每一帧的个token计算相似度,再以相似度作为权重得到帧级别的特征,最后每一个query会得到的向量。
之后也是在前面加上[CLS]之后通过自注意力得到每一个query对应的整体特征。
Modality-agnostic Encoder
把上面的各种token凑到一起来训的普通Transformer。
目标函数
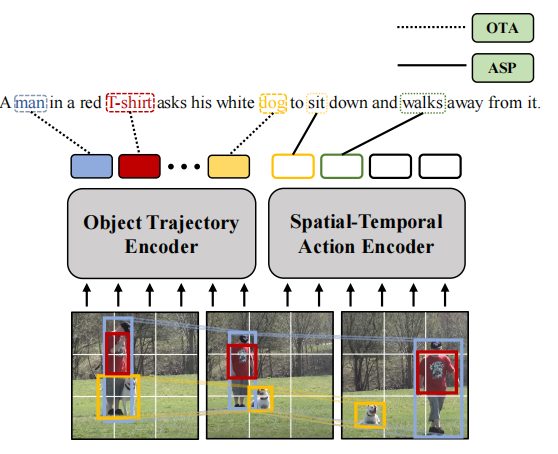
作者设置的目标函数较多,包含常规的Video-Text Contrastive、Video-Text Matching、Mask Language Modeling、Prefix Language Modeling。作者还根据这两个任务添加了Dynamic Object-Text Alignment和Spatial-Temporal Action Set Prediction两个额外的目标函数。
Dynamic Object-Text Alignment先通过SpaCy得到文本中的名词,然后通过匈牙利算法来匹配名词和目标轨迹特征,然后名词的特征和目标轨迹特征之间计算MSE作为损失。
至于Spatial-Temporal Action Set Prediction就也差不多,提取文本中动词,然后和之前用query提取的M个动作的特征进行匹配然后算MSE。假如动作不和任何名词匹配,那么就和句子整体特征匹配算loss。
总体目标函数朴实无华地是6个loss的直接相加。
实验
数据集
使用了WebVid-2M数据集,包含2.5M个版权视频(就是那种专门做视频素材的版权库)。实际上整个数据集有10M。WebVid-10M (m-bain.github.io)。数据集的视频质量很高(指拍得好),但是有水印、分辨率不高,描述也有噪声。

Implementation
视觉和语言编码器都是12层Transformer,视觉是CLIP ViT-B/16,动作轨迹和运动编码器都是2层Transformer,最后的fusion模块是6层Transformer。整体参数挺多,而且那么多目标函数计算也比较复杂。在128张V100上训练。
定量实验
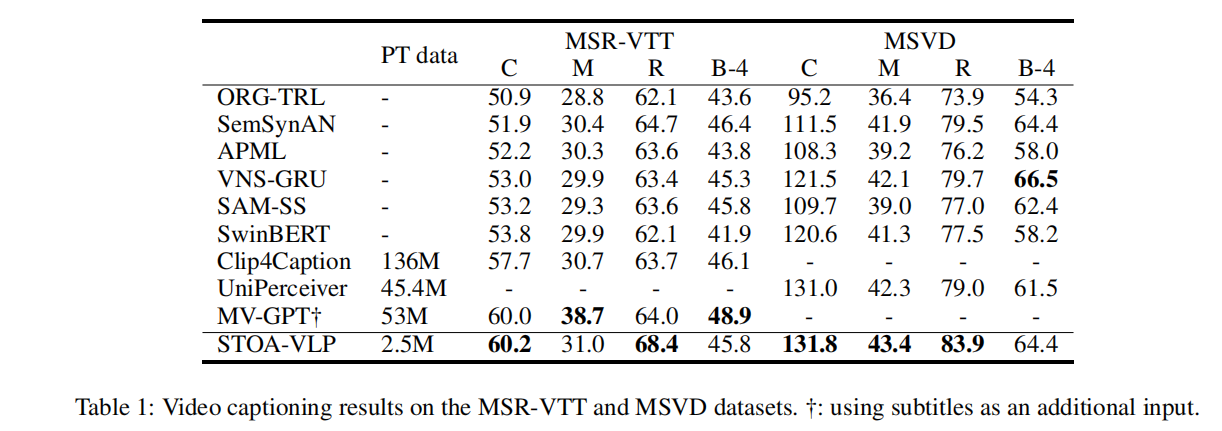
Video Captioning的实验,缺少了一些SOTA(GIT、mPLUG2),看上去效果一般。
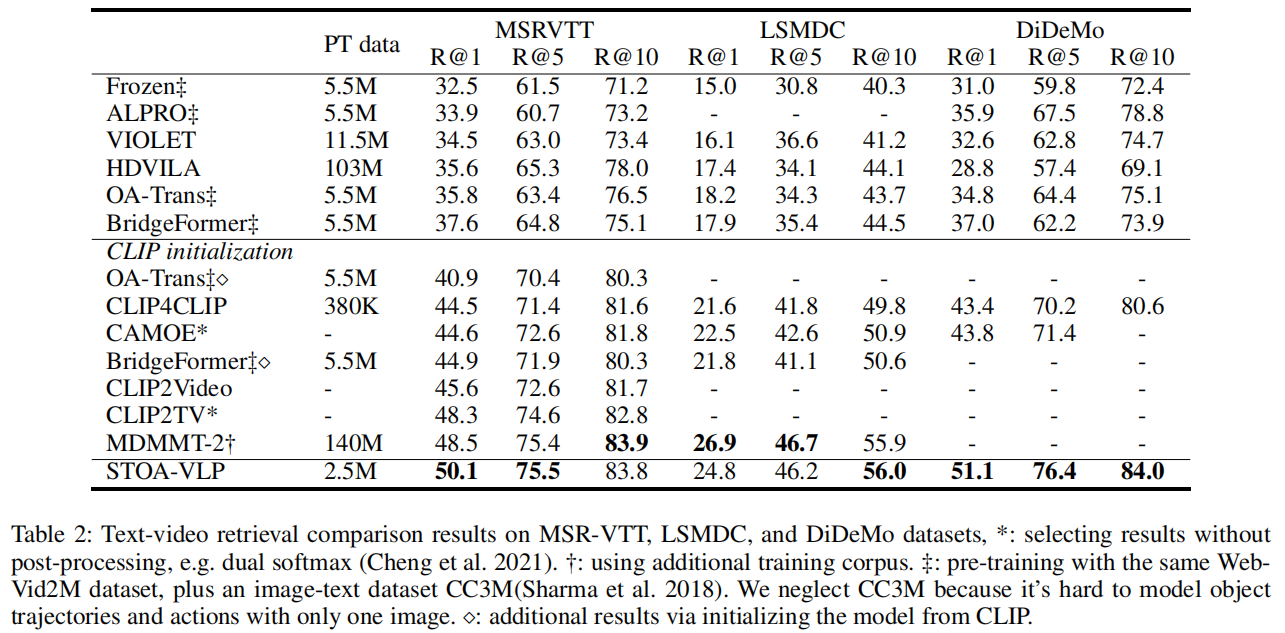
检索的实验,这一块看上去在预训练数据量少的情况下,效果还不错
消融实验
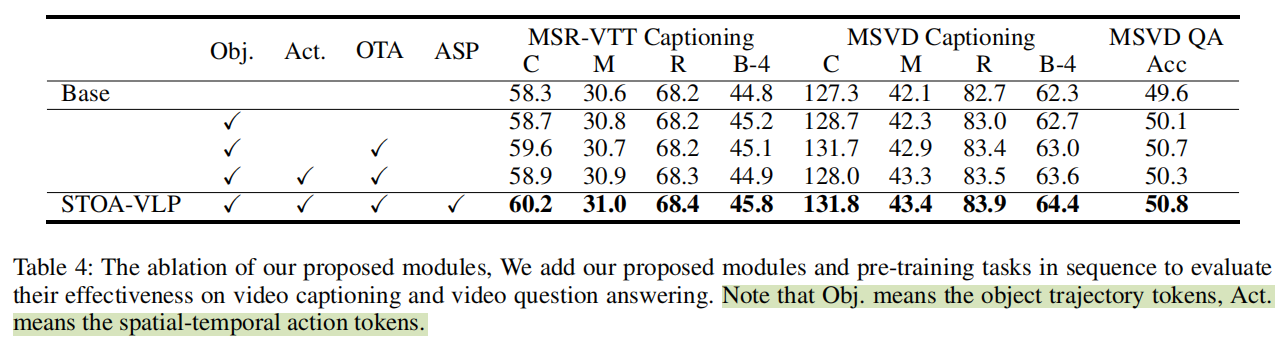
Base版本和最终好像也差不了多少……,添加了Object特征之后效果涨的比较多,剩下几个都感觉不怎么样了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!