近期LLM+视觉下游任务方法总结
本文最后更新于:2024年6月19日 晚上
近期LLM+视觉下游任务方法总结
最近,使用大语言模型(LLM)和多模态大语言模型(Multimodal LLM, MLLM)进行视觉下游任务的方法越来越多,本文对相关文献进行初步的调研,并形成了一篇总结的文章。(因个人水平,无法覆盖全,望谅解)。
什么是LLM/MLLM?
LLM的概念大家都知道,基本上就是GPT-3.5、LLaMa、Vicuna这样的模型,规模一般是7B、13B往上,处理文本任务。
MLLM(Multimodal Large Language Model)这个词可能不同文献有不同的说法,本文中将其定义为:相较于LLM来说,还能够输入图像/视频,并能够理解视觉内容并进行对话的模型。注意,虽然是说是多模态,但是我这边定义的MLLM基本都是处理图像的,并且只能输入图像而无法输出图像,比如MiniGPT-4、LLaVA这种模型。
MLLM一般是通过额外的视觉编码器(基本都是CLIP)得到图像patch级别的特征,然后作为LLM的embedding输入。部分使用BLIP-2的结构,通过一个Q-former对CLIP提取的特征进行降维(将非常多的patch特征降成固定例如32个特征),使用这种方法的有Video-LLaMA[1]、TimeChat[2]、AutoAD III[3]、InstructBLIP[4]、MiniGPT-4[5]等。还有的直接将CLIP的特征通过简单的相信层映射到LLM的空间中,比如LLaVA[6]。还有少部分位于其中,比如Flamingo[7]使用了交叉注意力的方式嵌入LLM,KOSMOS-1[8]和KOSMOS-2[9]使用了相同的Attentive Pooling方法来进行Q-Former的任务。
LLM在视觉下游任务的问题
在NLP领域,LLM将翻译、总结、生成、问答等任务都统一为生成式对话任务。在CV领域,目标检测、图像分割、视频检索、目标跟踪、图像/视频生成、视频总结、异常视频检测这些任务的输出是异构的,任务之间趋于独立,需要额外的模块或新的大模型架构。
比如目标检测需要得到框,即至少两个图像坐标;图像分割则需要得到mask,是像素级别的数据;视频检索则是得到视频的表征向量,或者利用MLLM生成的文本来进行检索……这些任务很难统一。
目前的两大解决方法

如上图所示,LLM在视觉下游任务可以分为以大模型为主体和以大模型和任务特定模型为主体的两类方法。
以大模型为主体
KOSMOS-2[9]将图像的不同坐标离散化为token,虽然有一定的量化误差,但是能够支持用户输入框,模型也能输出框。

LITA[10]处理视频,将视频的timestamp离散化为T个token,能够让模型输出视频的相对位置。比如<1> <3>就是从1%到3%的区间。
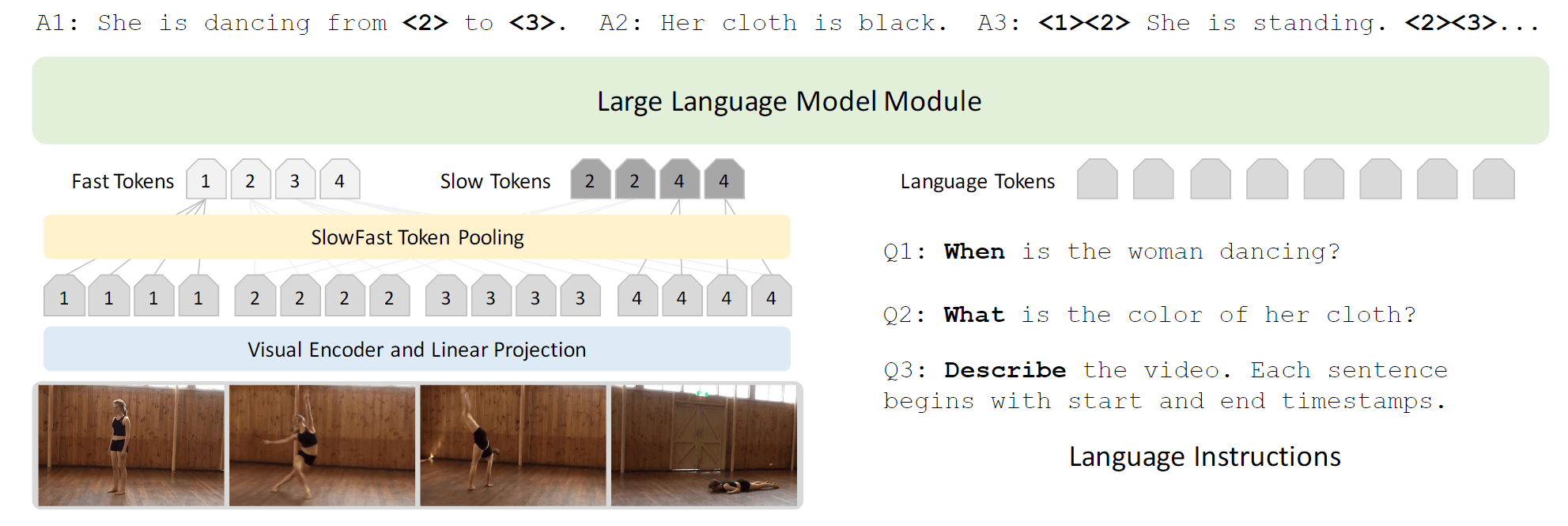
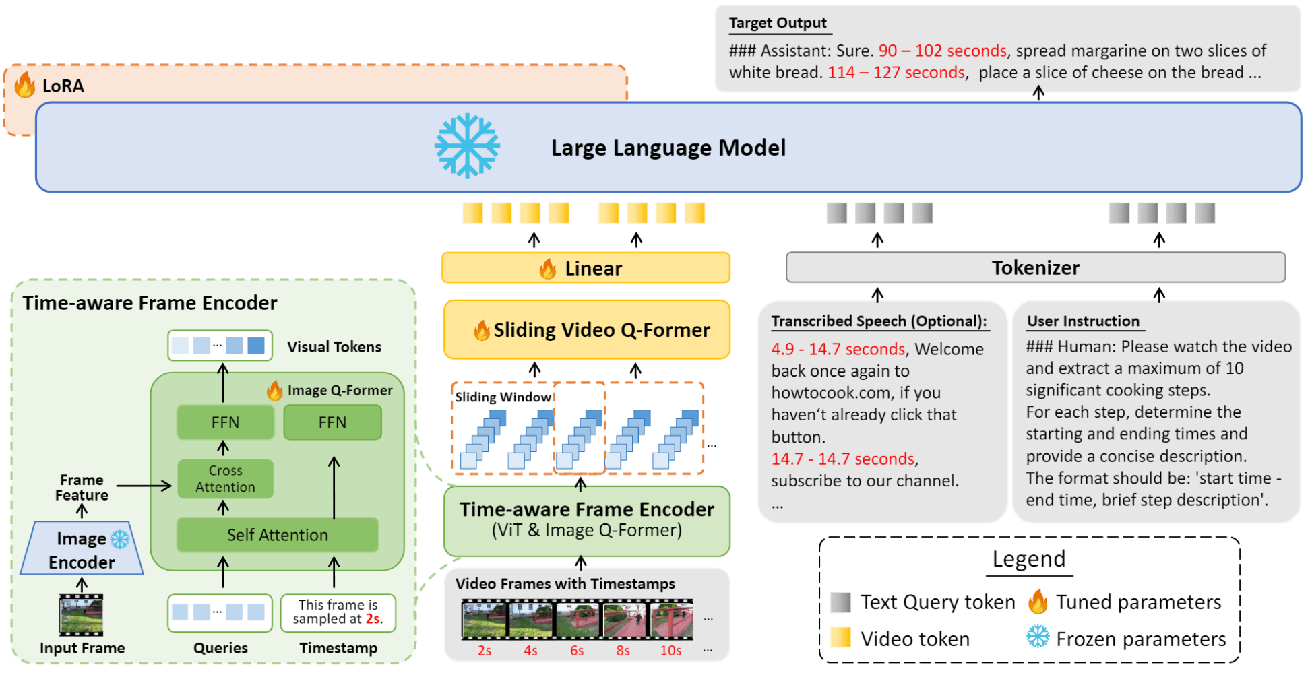
TimeChat[2]也是处理视频的,但是它输出绝对时间。
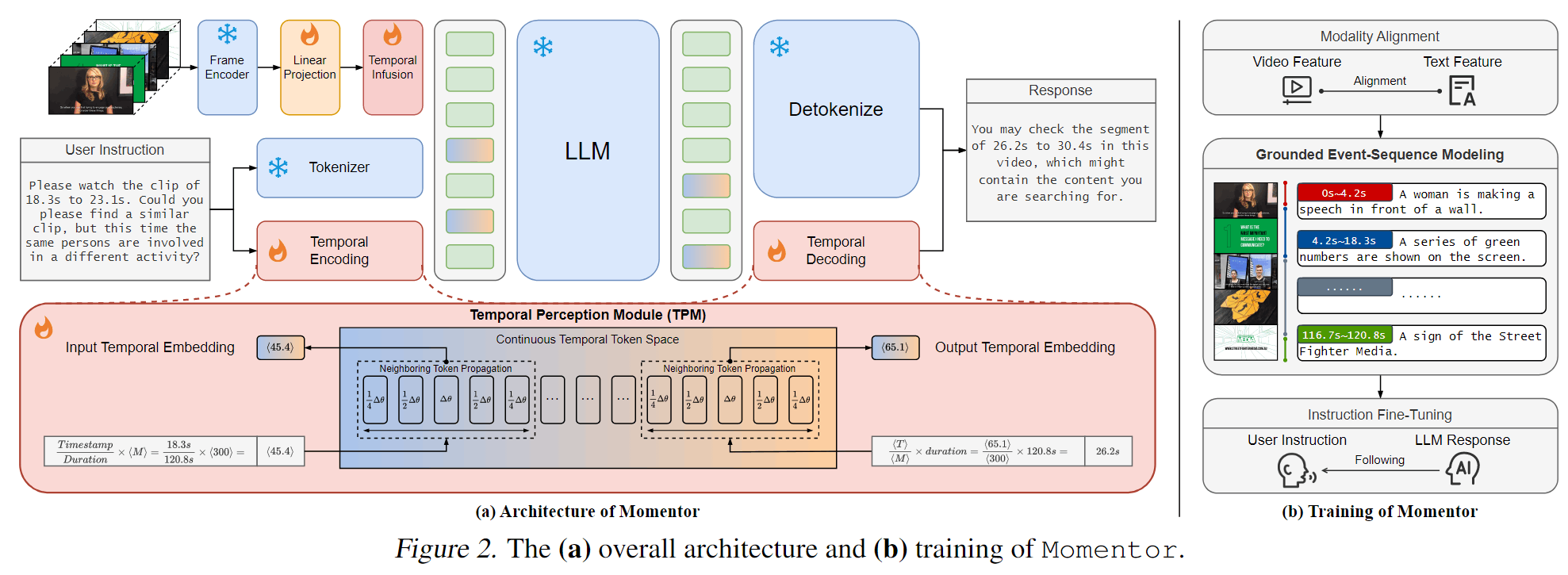
Momentor[11]在训练时将时间戳token进行了优化,将每个时间戳token融入相邻时间戳的梯度,并通过插值可以得到任意时间点的特征,避免了量化误差。
以大模型和任务特定模型为主体
然而,单纯使用大模型进行特定任务是有极限的,对于某些任务就不太合适了。同样举几个例子:
【LLM+图像生成】DreamLLM
DreamLLM[12]将LLM赋予了图像理解和生成能力。对于生成来说,它使用了一批dream queries,这些queries和BLIP-2的learnable queries一样,属于模型可学习的一组参数。这些queries在编码之后,就会得到一批embedding,这批embedding将会作为Stable Diffusion模型的condition,进行图像生成。对于理解来说,它会和别的模型一样将图像通过编码器得到特征输入到LLM中。
训练时,DreamLLM使用Interleave的数据(即像本博客一样,图文交叉的形式)。当需要图片输入进去的时候,会在前面添加一个特殊的<dream>token,然后输入一批dream queries,之后再将图片通过视觉编码器编码为visual embedding,再进行接下来的生成。
特别的,图像生成的时候,使用了DreamFusion[13]中的Score Distillation Sampling(SDS)作为图像生成部分的损失函数。直观的来说,SDS就是将扩散模型作为了一个现有的评价模型,这个评价模型不更新参数,但它会给你一个loss,告诉你的condition生成得好不好。
具体来说,它用的SDS损失如下所示,对于从正态分布中采样的噪声、以及从0~1随机选择的扩散步数,需要使估计噪声与真实噪声MSE最小。而估计噪声是根据、扩散模型参数以及DreamLLM给的condition决定的。
根据文献[13]的结论上面这个loss在不变时等价于下面这个。这个公式先看
,逗号,再看|,也就是两个条件概率的KL散度,第一个条件概率是扩散模型+(可能不准确的)condition得到的图像分布,第二个则是扩散模型原本的分布,最小化这个KL散度,就能够学到一个合理的condition。
本质上就是给原图加上一些噪声,然后提供给扩散模型一点提示(condition),让他能够去除这个噪声。到了测试的时候,就可以从纯噪声根据学出来的condition来一步步恢复原来的图像。

总之,DreamLLM通过一个外置的扩散模型,得到了图像生成的能力。
DreamLLM引用了三篇论文[14][15][16],都是使用类似的外置SD的方法,也都是生成对应SD的condition,只不过没有用SDS。
【LLM+图像分割】LISA: Reasoning Segmentation via Large Language Model

LISA[17]的架构如上,非常简单,下路的MLLM+LoRA是LLaVA的微调 ,上面的VIsion Backbone+Decoder是SAM的微调。SAM的Decoder可以接受prompt,这个prompt就被改成了一个特殊的<SEG>token。
利用LISA可以实现模型进行Reasonal的分割,即使用户没有明说要分割什么,也可以利用LLM的推理能力进行分割。

对于LISA,也有进化后的模型,比如清华的GSVA[18],字节的PixelLM[19],美团的LaSagnA[20]。

【LLM+多模态生成】

X-VILA[21]将LLM与更多模态连接起来了,不同模态能够映射到同一个Textual Embedding Space,使用LLM进行交互,然后再映射到不同生成模型作为condition,从而生成图像、视频、音频。
- Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding, EMNLP’23 ↩
- TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding, CVPR’24 ↩
- AutoAD III: The Prequel - Back to the Pixels, CVPR’24 ↩
- Instructblip: Towards general-purpose vision-language models with instruction tuning, NeurIPS’24 ↩
- MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models, ICLR’24 ↩
- Visual Instruction Tuning, NeurIPS’23. ↩
- Flamingo: a Visual Language Model for Few-Shot Learning, NeurIPS’22 ↩
- Language Is Not All You Need: Aligning Perception with Language Models, NeurIPS’23 ↩
- KOSMOS-2: Grounding Multimodal Large Language Models to the World, ICLR’24 ↩
- LITA: Language Instructed Temporal-Localization Assistant, ArXiv/2403.19046 ↩
- Momentor: Advancing Video Large Language Model with Fine-Grained Temporal Reasoning. ArXiv/2402.11435 ↩
- DreamLLM: Synergistic Multimodal Comprehension and Creation, ICLR’24. ↩
- DreamFusion: Text-to-3D using 2D Diffusion, ICLR’23 ↩
- Generating Images with Multimodal Language Models, NeurIPS’23 ↩
- Emu: Generative Pretraining in Multimodality, ICLR’24 ↩
- Planting a SEED of Vision in Large Language Model, ICLR’24 ↩
- LISA: Reasoning Segmentation via Large Language Model, ArXiv/2023 ↩
- GSVA: Generalized Segmentation via Multimodal Large Language Models, CVPR’24 ↩
- PixelLM: Pixel Reasoning with Large Multimodal Model, CVPR’24 ↩
- LaSagnA: Language-based Segmentation Assistant for Complex Queries, ArXiv/2404.08506 ↩
- X-VILA: Cross-Modality Alignment for Large Language Model, ArXiv/2405.19335 ↩
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!