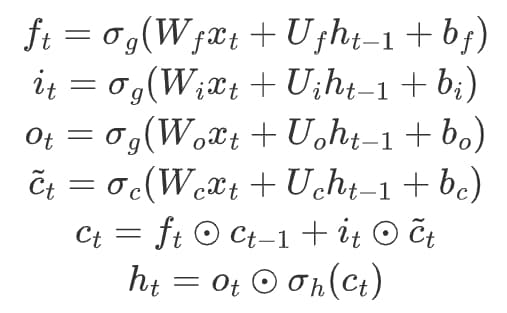本文最后更新于:2024年4月6日 下午
论文笔记 RWKV:Reinventing RNNs for the Transformer Era
EMNLP23的一篇文章,一作是Bo Peng,在知乎比较活跃,提出了RWKV模型,其将RNN和Transformer的思想进行结合,使时间复杂度降低到了线性,同时其性能在不同参数量(高达14B)下均得到了验证。
代码链接:BlinkDL/RWKV-LM: RWKV is an RNN with transformer-level LLM performance
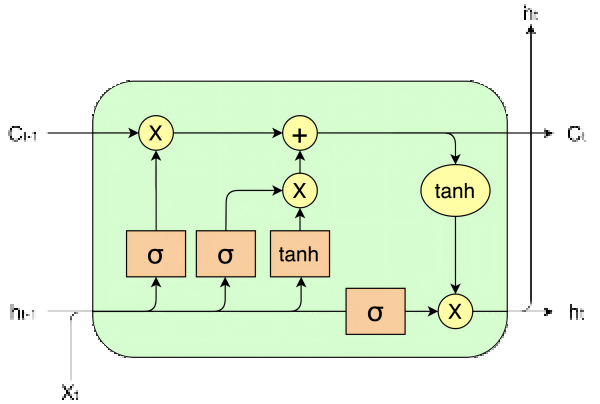
如上图和上式所示是经典RNN——LSTM的架构。
LSTM内部保存hidden和context两种状态,在一次处理中,首先会通过相同的方法,用不同的权重得到4路当前输入和h状态的线性变换(前4个式子)。其中,前3路会使用sigmoid函数激活,得到遗忘门ft、记忆门it和输出门ot,用来作为权重控制遗忘程度、记忆程度和输出程度。
第4路是主要的信息通路,使用tanh函数进行激活,得到当前的信息向量c~t。随后,这个信息向量会与之前的c状态进行线性组合,用到的就是之前生成的遗忘门和记忆门。这一步得到的结果就是新的c状态,由于c状态是与之前状态的叠加,所以表示long-term的状态,改变较平缓。
第6个式子则是利用c状态+输出门来得到当前的h状态,由于其是直接生成的,和ht−1没有直接的叠加关系,所以表示short-term的状态,改变较剧烈。
⚠️LSTM类的模型由于依赖前一时刻的输出作为当前输入,所以无法并行,且其保存的状态信息量过少,长期记忆性不好。
✅ 为了解决长期依赖性的问题,Transformer中的自注意力机制带来了全局的点积注意力运算:
Attn(Q,K,V)=softmax(QK⊤)V=∑i=1Teqt⊤ki∑i=1Teqt⊤ki⊙vi(1)
⚠️然而,Transformer的这种机制带来了QK矩阵相乘的平方复杂度,这是我们不想要的
✅所以我们要对注意力机制进行进一步的分析,从论文中,我们将注意力机制泛化为:
attnt=∑i=1Tsim(qt,ki)∑i=1Tsim(qt,ki)⊙vi(2)
其中,sim(qt,ki)在Transformer中是exp(qt⊤ki),而这个操作是可以替换的,只需要保证sim:R2×F→R+。所以,我们可以通过ϕ(x)来构建这么一个泛化的相似度比较函数(核函数)sim(q,k)=ϕ(q)⊤ϕ(k),写到注意力机制中即:
attnt=∑i=1Tϕ(qt)⊤ϕ(ki)∑i=1Tϕ(qt)⊤ϕ(ki)⊙vi(3)
注意分子中三个向量的矩阵乘法可以通过这个规则进行变形:qkv=(qk)v=q(kv),写到注意力机制中即:
attnt=ϕ(qt)⊤∑i=1Tϕ(ki)ϕ(qt)⊤∑i=1Tϕ(ki)⊙vi(4)
经过这个最重要的变形,我们已经将注意力机制的二次复杂度降低到了线性!(1)中随着T的增长,计算一个attnt需要进行2T个点积,总共需要T个输出,所以是4T2个点积,而(4)中∑i=1Tϕ(ki)⊙vi和∑i=1Tϕ(ki)在T个输出中只需要计算一次,即计算2T个点积,然后得到的向量在计算一个attnt也需要进行1个点积,所以总共是3T个点积。
所以,对于线性复杂度的Transformer,我们只需要设计对应的ϕ函数即可。
一般情况下,对q使用的ϕ函数和对k使用的ϕ函数应该是一样的,具有对称性,但是深度学习时代这个对称性是可以被放松的。
✅ AFT(Attention Free Transformer)就是这种范式下的一种注意力机制
AFT的原型如下:
attnt=1(qt)⊤∑i=1Texp(ki)σ(qt)⊤∑i=1Texp(ki)⊙vi(4)
q对应的ϕ被设计成了一个sigmoid函数和一个常数函数,k对应的ϕ则设计成了exp函数。
为了考虑位置先验,AFT把key对应的ϕ加上了一个pair-wise position bias向量:

attnt=σ(qt)⊙∑i=1texp(wt,i+ki)∑i=1texp(wt,i+ki)⊙vi(5)
然而,由于引入的这个向量包含了与t有关的wt,i,所以(5)并不是线性复杂度的。
✅ 在进行生成式任务时,Transformer往往会施加Causal Masking,成为一个因果的注意力,而论文发现这和RNN的形式相似:
s0siziyi=0,z0=0=si−1+ϕ(xiWK)(xiWV)⊤=zi−1+ϕ(xiWK),=ϕ(xiWQ)ziϕ(xiWQ)si(6)
其中状态包括两部分:s叫做attention memory,z叫做normalizer memory,分别对应分子和分母,在逐个计算注意力的时候,实际上就是在不断累积这些memory,输出的时候进行最后一行的运算即可得到结果。
✅ RWKV就是这种范式下的一个新模型,其在AFT的基础上,将w从一个T×T的矩阵改为一个T维向量+位置相关的衰减系数
RWKV
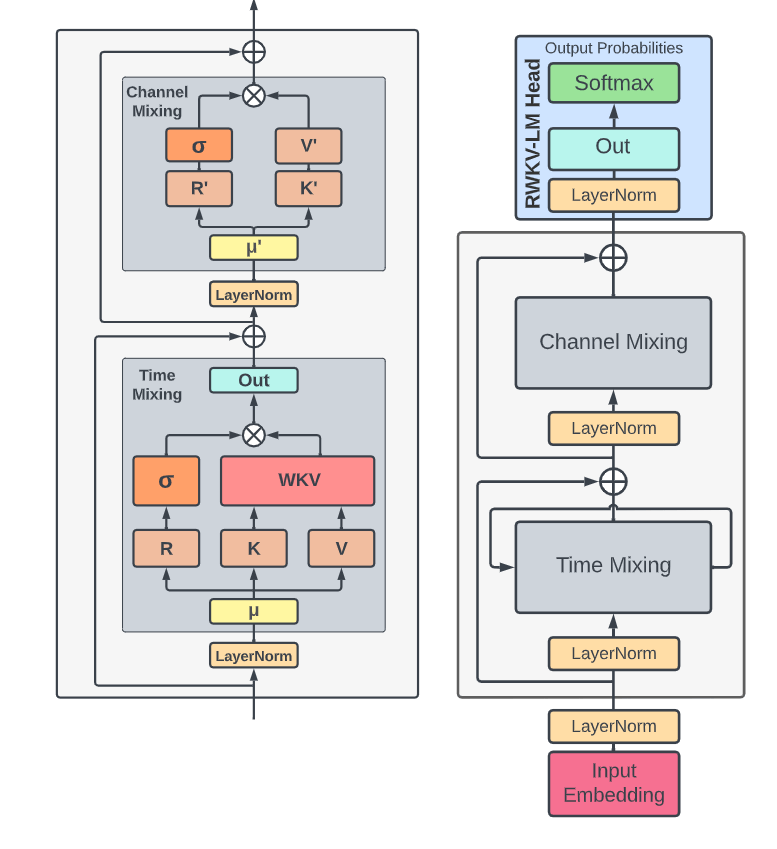
如图是RWKV的整体架构,和Transformer类似(或者说与MLP-mixer类似),token先进行token-level的信息交换(Time Mixing),然后channel-level的信息交换(Channel Mixing)。
RWKV的名称由来如下:
- R:Receptance向量,表示从过去接收的信息(其实和之前介绍过程中泛化的Query类似)
- W:一个可训练的向量,表示根据位置获取信息的参数
- K:和Transformer中的key类似
- V:和Transformer中的value类似
Time-Mixing
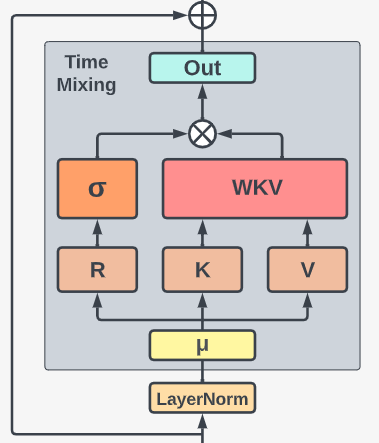
RWKV在mix之前会进行Token shift,time-mixing的输入是当前输入xt和上一步输入xt−1的线性组合的线性映射(类似Transformer中生成QKV的过程):
rt=Wr⋅(μr⊙xt+(1−μr)⊙xt−1)kt=Wr⋅(μk⊙xt+(1−μk)⊙xt−1)vt=Wr⋅(μv⊙xt+(1−μv)⊙xt−1)(7)
之后,K和V进行WKV算子运算:
wkvt=∑i=1te−(t−i)w+ki∑i=1te−(t−i)w+ki⊙vi=∑i=1t−1e−(t−1−i)w+ki+eu+kt∑i=1t−1e−(t−1−i)w+ki⊙vi+eu+kt⊙vt(8)
其中,第一行和(5)比较相似,只不过加上的位置相关的向量改成了channel-wise time decay vector(w)与相对位置相乘。作者令w是一个d维的大于等于0的向量,从而使ewt,i≤1,使其具有“衰减”的含义。即上式中 exp(−(t−i)w+ki)=exp(−(t−i)w)exp(ki),而第一项是一个大于0,小于1的数,随着t−i越大越接近0。第二行是RWKV最终使用的式子,即当t=i时,本来是加上0乘w,但是不太好,所以加上了另一个可学习的向量u。
在得到结果之后,利用rt进行类似LSTM的输出门控:
ot=Wo⋅(σ(rt)⊙wkvt)(9)
结合(8)(9),就非常像(5)了。
和(6)一样,WKV算子也可以写成RNN的形式,这个时候w的设计就非常巧妙了:
a0,b0atbtwkvt=0=e−w⊙at−1+ekt⊙vt=e−w⊙bt−1+ekt=bt−1+eu+ktat−1+eu+kt⊙vt(10)
同样,状态包括分子和分母,分别是a,b。前一步的状态要乘e−w,再加上key与value计算出来的结果。由于(8)中定义了w的形式是相对距离个e−w相乘,所以这里每一步都是乘e−w。到了最后一步输出,也是一个作为分子,一个作为分母,当前时刻额外的是用u。
⚠️在实际计算中,(10)中的指数计算可能面临上溢风险,所以计算的时候会额外使用一个pt来保存at,bt中共享的幂。(具体原理可以看论文附录D)。本来wkv的参数量是4DL的,但是由于计算问题会变成5DL。
RWKV的(8)和(10)带来了time-parallel mode和time-sequential mode两种模式,分别用在训练和推理中。
训练时处理打包成batch的数据,RWKV拥有O(BTd2)的时间复杂度,并且可以并行计算。
Channel-Mixing
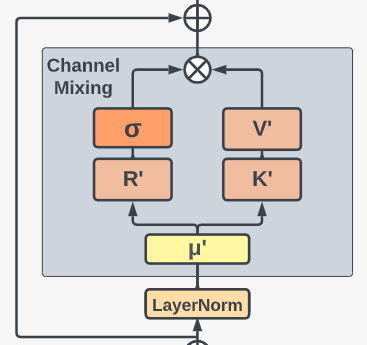
channel-mixing也会进行Token shift:
rt′kt′ot′=Wr′⋅(μr′⊙xt+(1−μr′)⊙xt−1)=Wk′⋅(μk′⊙xt+(1−μk′)⊙xt−1)=σ(rt′)⊙(Wv′⋅σReLU2(kt′))(11)
其中,σReLU2表示ReLU激活后再平方,论文没说动机。
假如把Token shift去掉,上图左侧一路相当于一种channel attention,右侧则像Transformer中的两层FC构成的FFN。
实验
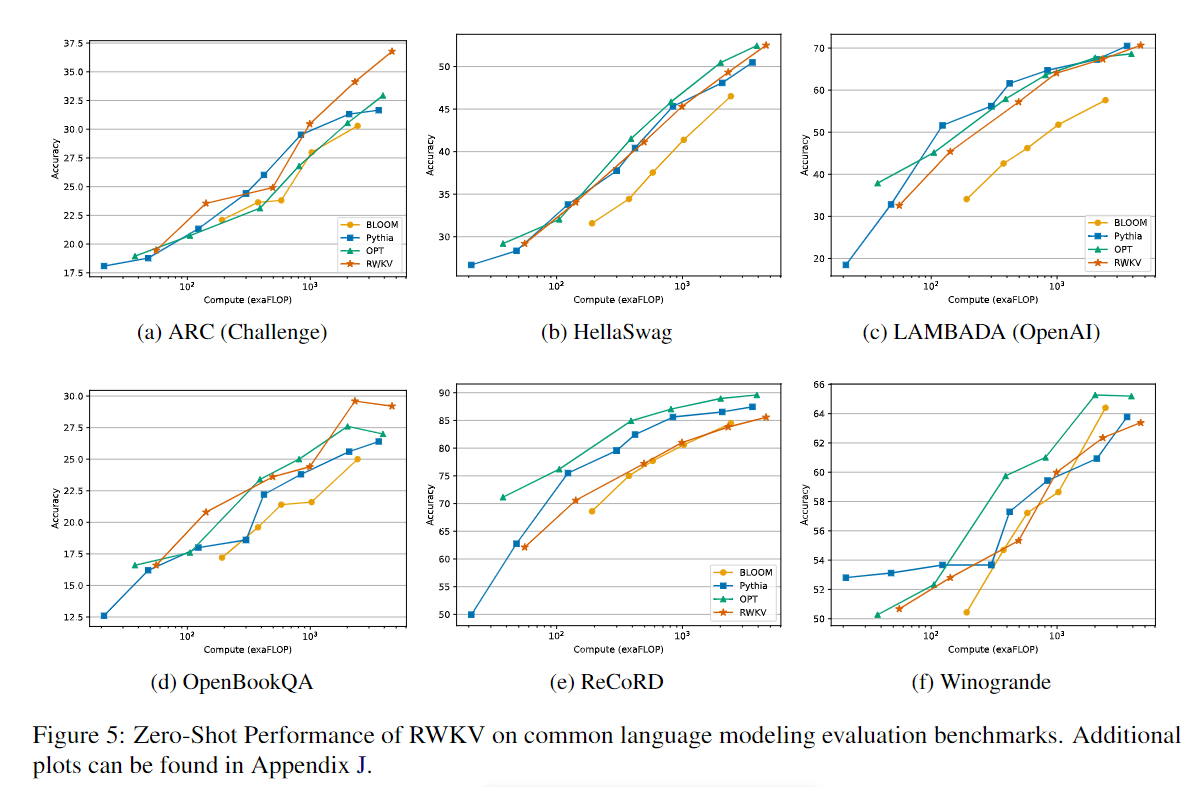
☝️ 不是很懂NLP的评测标注,Fig 5中表现其实一般,但是已经比较有竞争力了。
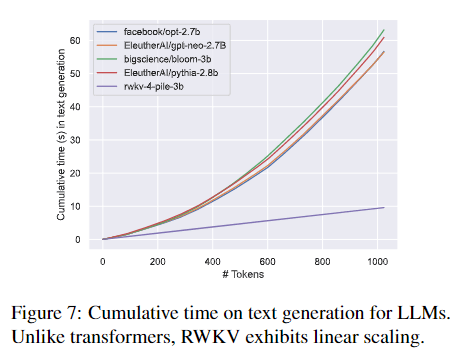
☝️RWKV最有优势的地方就算节省资源,在token数量很大时,仍然保持较快的处理速度。
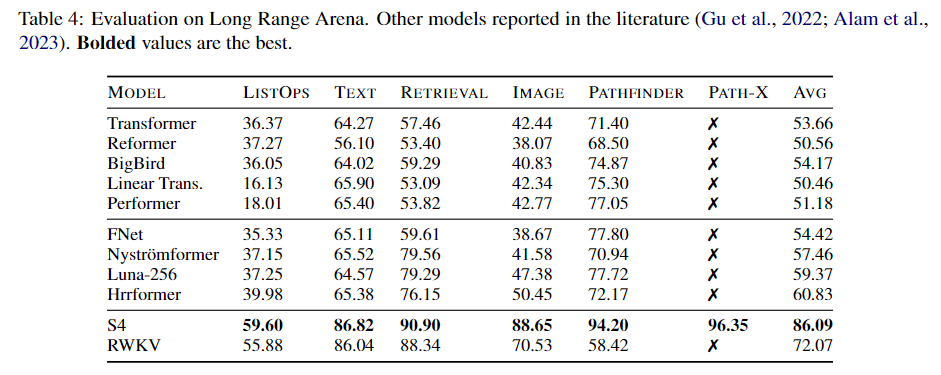
☝️同时,在Long Range的评价标准下,RWKV获得了除开S4外基本最优的性能,但是S4超了很多,
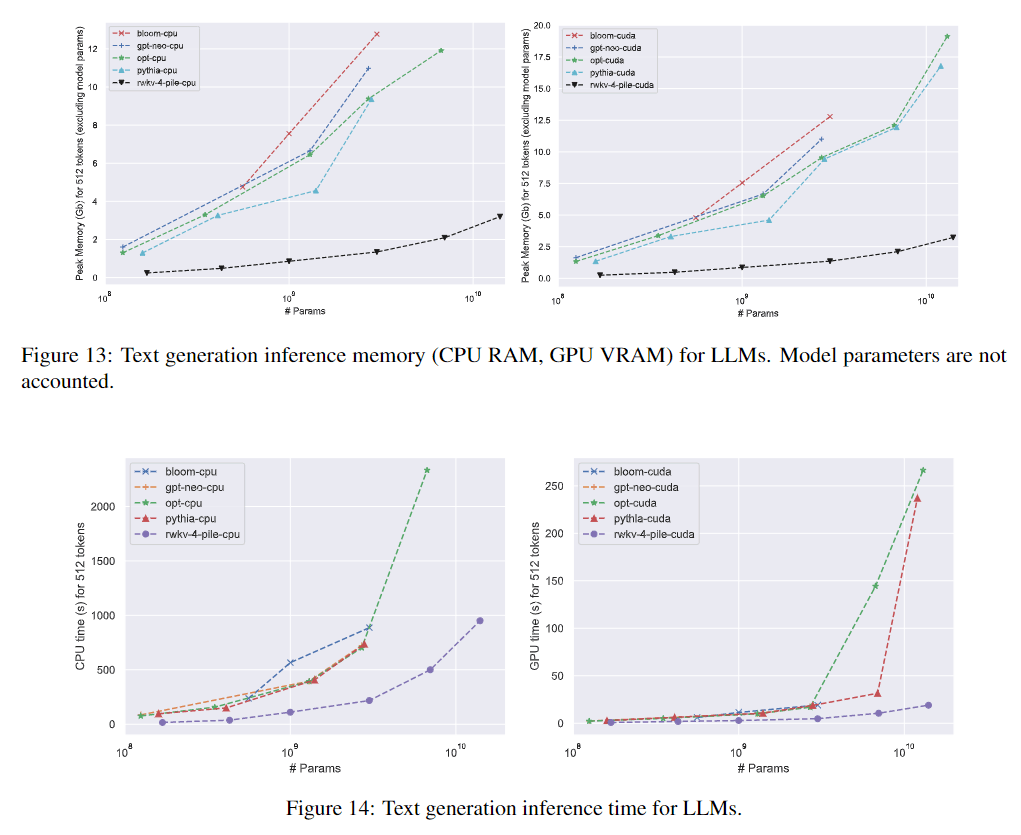
☝️ 在不同参数量模型的推理速度上,RWKV具有非常非常明显的优势。
结论
RWKV展示了线性Transformer的另一种可能,并花费巨大成本,积极在LLM赛道上进行实验。
RWKV目前的不足,作者自己分析是在其相较于Transformer的建模能力的天生差距,此外还有就是RWKV的recurrent的特性也使得其对prompt的要求非常高,prompt的顺序都会影响巨大。
RWKV未来野心勃勃,计划涉及多模态等领域,并提到了其替换cross-attention的目标,但是没说具体怎么做。