论文笔记 MLP-Mixer:An all-MLP Architecture for Vision
本文最后更新于:2024年3月27日 晚上
论文笔记 MLP-Mixer: An all-MLP Architecture for Vision
NIPS2021的一篇论文,对Vision Transformer的架构进行了泛化和改进,提出了一种仅使用MLP的现代的类Transformer的模型,并在多个数据集上取得了非常好的性能,为人们理解CNN和ViT提供了新的思路。
代码链接:google-research/vision_transformer (github.com)
非官方PyTorch版本代码链接:lucidrains/mlp-mixer-pytorch: An All-MLP solution for Vision, from Google AI (github.com)
方法
深度学习的CV是从CNN起家的,而ViT通过顺应移除inductive bias+大规模训练的趋势得到了更好的性能。而作者提出了MLP-Mixer模型,通过极简的设计理念,在不使用卷积和自注意力的情况下,仅通过MLP获得了视觉任务上的高性能。
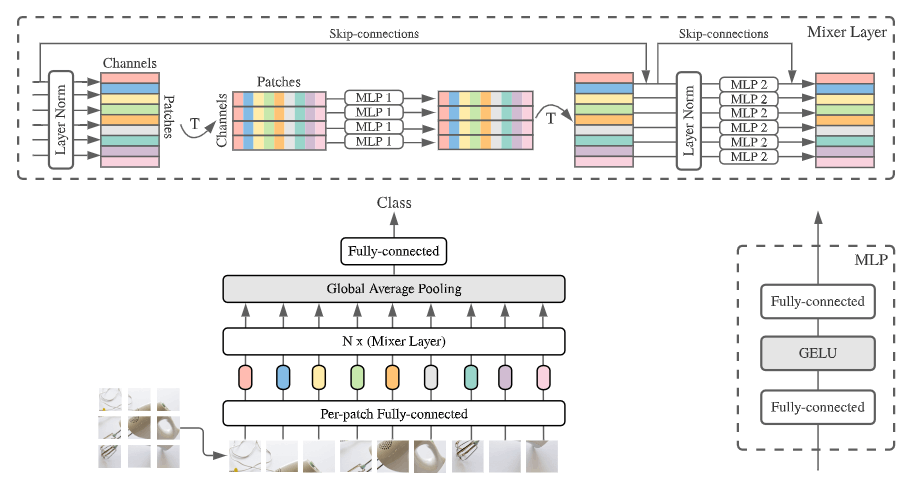
上图是MLP-Mixer的基础架构,可以发现和ViT还是很像的,其包含了将图片划分成patch的过程,以及之后多层的编码器,最后池化并接全连进行分类。对于最关键的编码器,作者分成了Token-mixing和Channel-mixing两个阶段,而这是从CNN和ViT中得到启发的:
- 对于CNN来说,的卷积表示Channel-mixing,而其它形状的卷积则同时进行Token和Channel的mixing。
- 对于ViT来说,其SA层同时进行Token和Channel,FFN层进行Channel的mixing。
- 作者提出的MLP-mixer则进行彻底的解耦,分成Token和Channel两部分,前者对于一个通道的特征,在不同token之间通过MLP进行信息交换;后者对于某个token,在特征维度通过MLP进行信息交换。
如上图所示,一层mixer layer包含了两个MLP,每个MLP就是类似Transformers中的FFN,在进行mixing时,不同空间、通道共享MLP的权重。因此,这种设计提供了位置不变性,和CNN一样,其对于不同空间的特征进行相同的处理。
这种操作和其他方法有类似之处:
- Separable Conv:先进行空间的信息交换,再进行通道的信息交换。然而,这种方法在不同通道时使用的是不同的卷积核。
- Transformer:输入和输出的shape完全一样,而CNN则会通道数越来越多,空间分辨率越来越小。且MLP-mixer也采用了常规的skip-connection和Layer-Norm
要注意的是,MLP-mixer要求序列长度固定,且不需要位置编码,这个和Transformer不一样,也是这个架构的一个缺陷。
实验
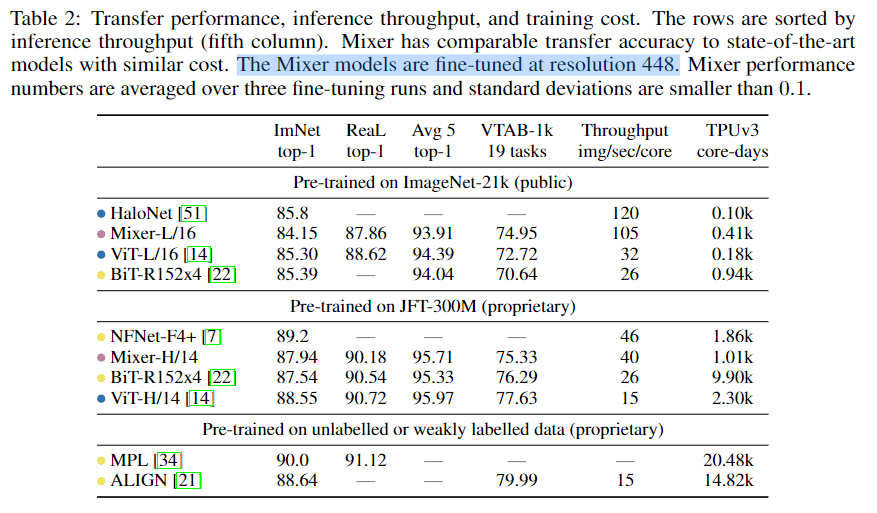
下图是主要的比较表,黄色是基于卷积的,蓝色是基于ViT的。可以发现Mixer与ViT相比,在各个任务上稍微低了一些,但是运行速度提升比较多。作者主要主张他们用这种简单的架构已经能获得非常好的效果了。
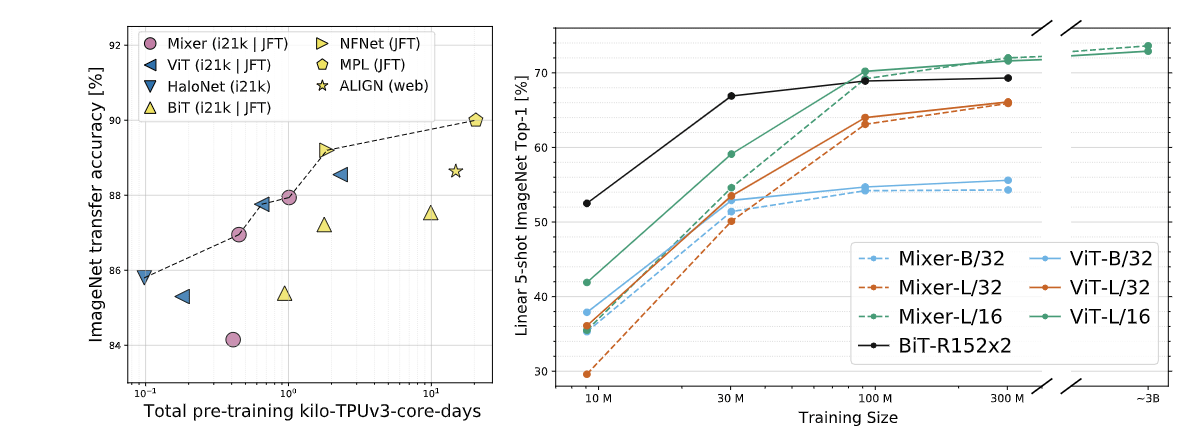
下图则是图形化的比较,和上面的结果类似,但是有意思的是在大模型+大数据下,Mixer比ViT更好一点。
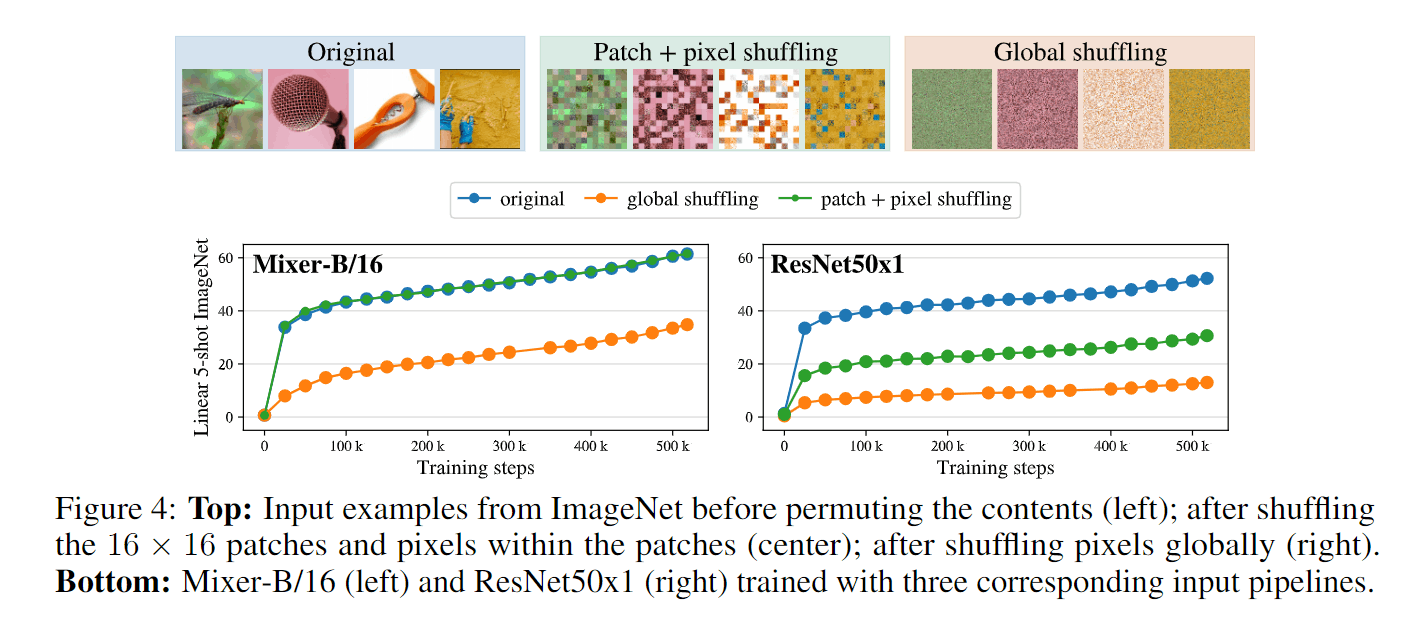
下面这个是一个比较有意思的实验,作者用同样的方式将数据集内图像patch进行打乱或者pixel进行打乱,然后比较训练效果,验证MLP-mixer是自动学习位置信息的,不像ResNet这种CNN一样带来了inductive bias。
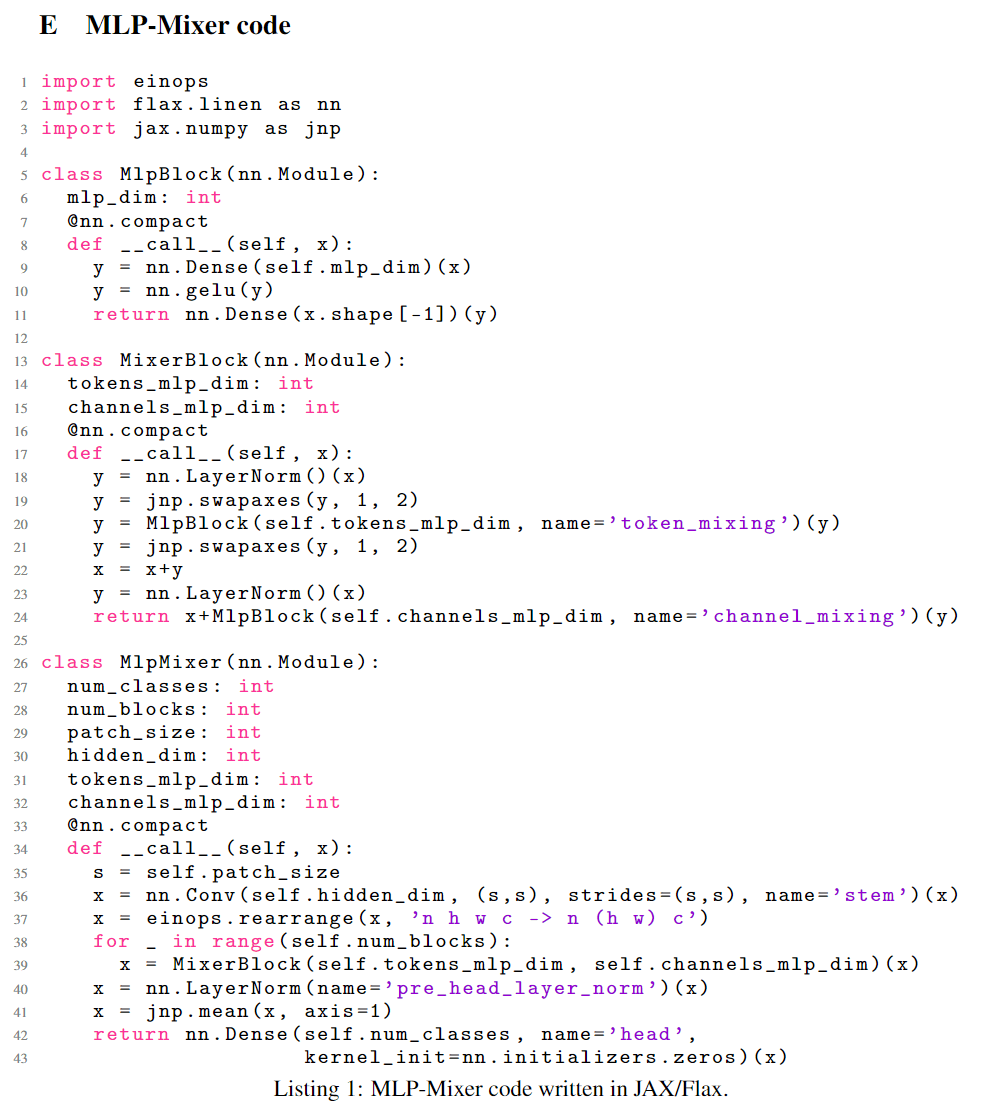
最后,有意思的是,MLP-mixer的方法真的很简洁,模型代码甚至能直接写一页在论文里。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!