论文笔记 InternVideo:General Video Foundation Models via Generative and Discriminative Learning
本文最后更新于:2024年3月25日 上午
论文笔记 InternVideo: General Video Foundation Models via Generative and Discriminative Learning
上海人工智能实验室的OpenGVLab的一个视觉为主的多模态基础模型 InternVideo,2022年12月发布。
本文大致介绍其idea、架构、训练方法和部分实验,由于知识受限,不会过于深入。
研究故事
视觉基础模型中,相较于图像,视频模型更少被探索,主要是因为1. 视频处理难度大 2. 视频Benchmark都可以用图像骨干+时序编码得到。其他工作提出的视觉模型都关注少部分任务,所以需要一个能够执行所有任务的通用基础模型。
InternVideo就是这么一个模型。
它主要利用视频掩码建模(Masked Video Modeling)和多模态对比学习(Multimodal Contrastive Learning)。
- 掩码建模:对视频理解效果好,但是模型规模收到目前解码器的限制
- 多模态对比:嵌入高级语义信息,但是时空建模信息不足。
为了解决(融合),作者结合两种自监督的任务,提出了一个大规模但是高效的统一训练方法,并在39个benchmark上进行了实验,涉及行为识别、视频-语言对齐、开放世界应用三大方面的任务。
具体来说,InternVideo设计了一个统一视频表征学习范式(UVR),探索了掩码建模(后简称MAE)和对比学习(后简称MML)。UVR提升了训练效率,展示了比“图像+时序建模”更好的表征能力。作者先使用两种训练方法分别训练出一个Video encoder,然后使用交叉模型注意力模块来进行特征对齐,此时还会冻结大部分参数。
作者为训练大规模视频基础模型提供了以下贡献:
- 证明VideoMAE是可以进一步扩大训练数据的
- 证明重用图像预训练ViT是有好处的
- 证明行为识别可以作为自监督训练后的第二阶段预训练
- 证明他们的分阶段训练方法是高效且有效的
方法
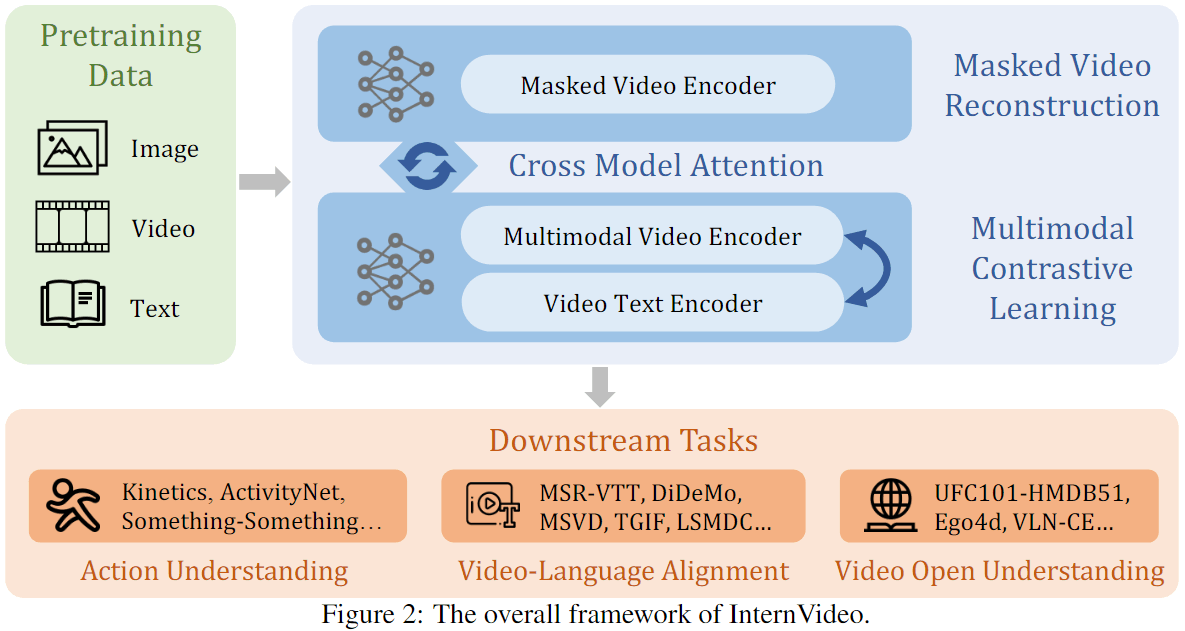
InternVideo整体框架如上所示,训练分成了三个阶段:Self-Supervised Video Pretraining、Supervised Video Pretraining、Cross-Model Interaction。
Self-Supervised Video Pretraining
分成视频掩码建模和视频-语言对比学习两部分。
前者基本Follow VideoMAE的方法。
后者使用了他们前作提出的UniformerV2,并使用ALBEF的方式进行训练。
这些基本没什么好说的,都是使用之前积累的方法,ALBEF大概就是先对齐,然后再加个解码器去进行Captioning。
UniformerV2在后面单独说。
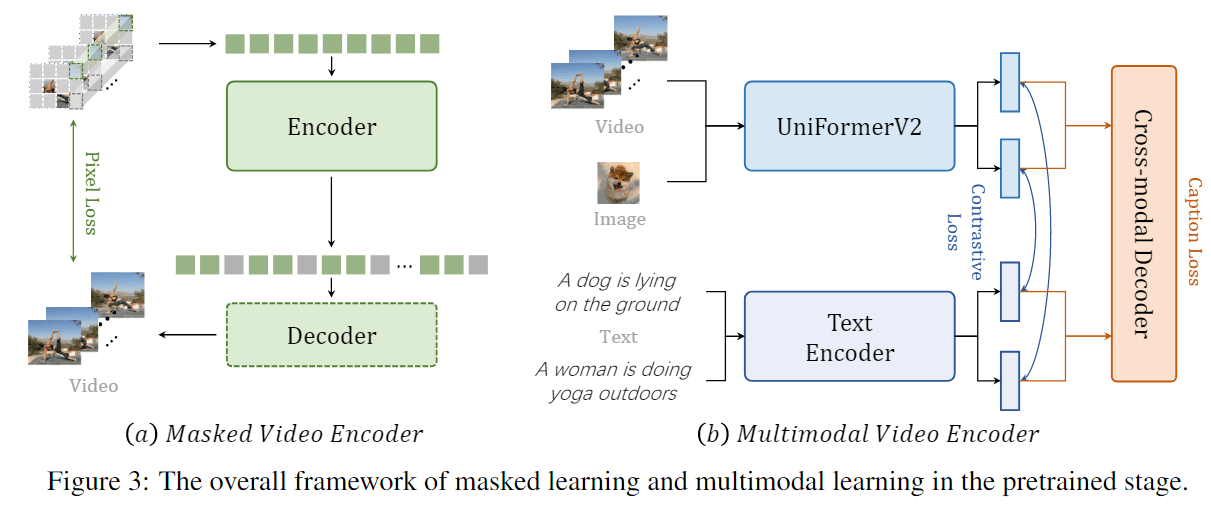
Supervised Video Post-Pretraining
对于MAE,作者使用K710微调。
对于MML,作者使用UniFormer的方式,也在K710上微调。
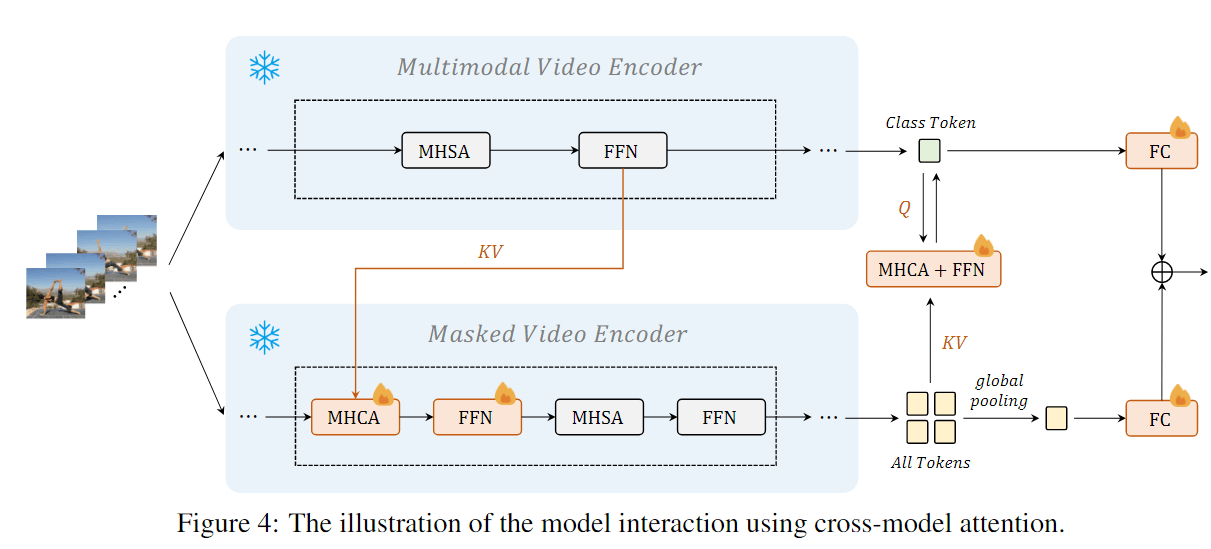
Cross-Model Interaction
如下图所示,先冻结Encoder所有参数,然后在MAE中加入交叉注意力和FFN,使MAE获取MML中的语义信息,最后输出时再通过一层交叉注意力和FFN把信息送到MAE那边。最后,学习一个线性结合来融合两边的分数。新增的模块为了不破坏原本特征,会添加tanh的gating layer。
UniFormerV2
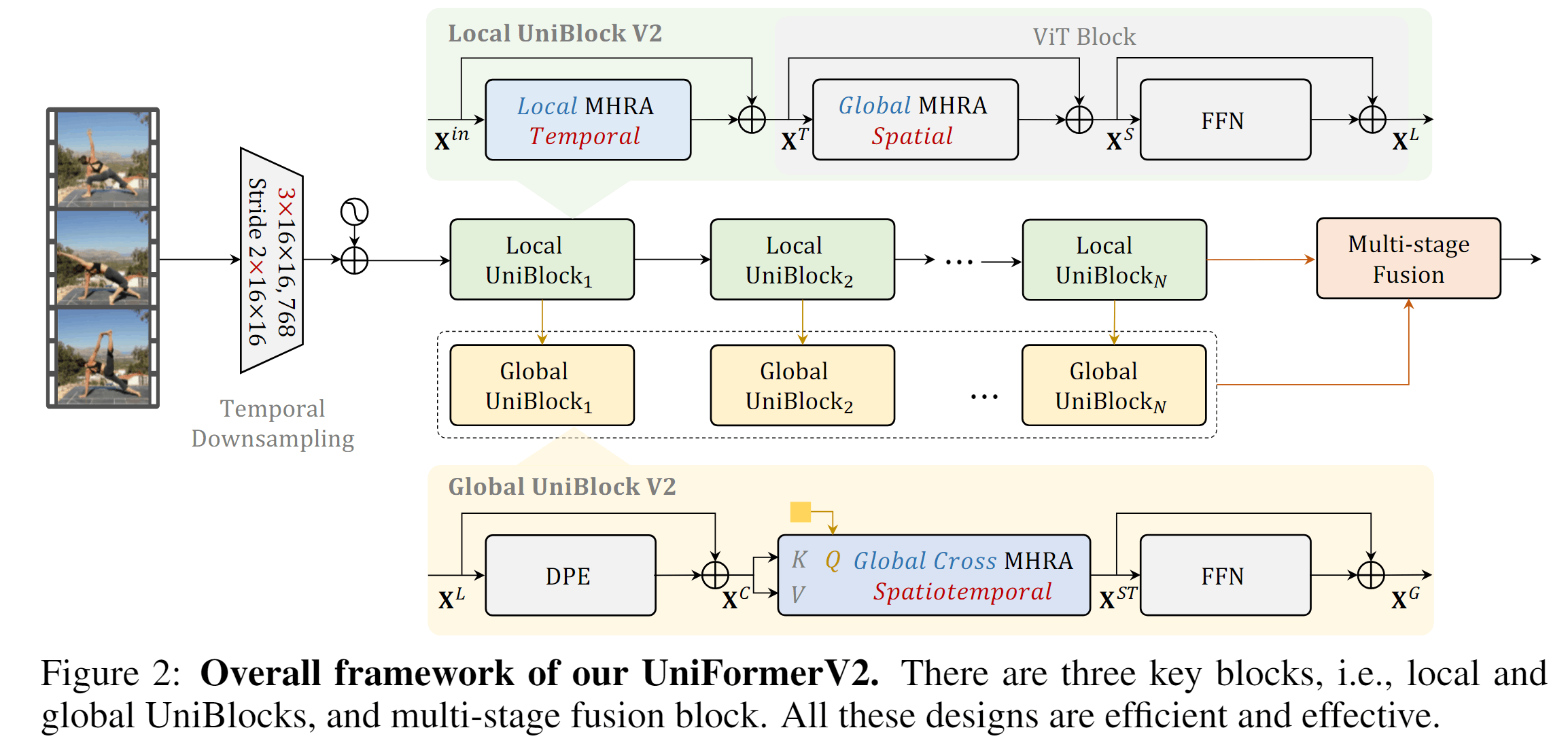
如图为UniFormerV2的整体架构,首先变成patch,然后分别进行两路的Local和Global编码,两路特征最后通过Multi-stage Fusion进行融合。
pathify
首先使用3D大卷积来生成个时空token,具体来就是得到的patch。
Local UniBlock
这一路将ViT进行扩展,用到了UniFormerV1中的MHRA模块,如下图所示,MHRA是Multi-head Relation Aggregator的缩写。MHRA结合了Transformer和3D卷积,解决了浅层网络的redundancy问题和深层网络的dependency问题。
MHRA整体的公式为:
其follow了Transformer的设计,并将其进行了泛化。输入经过线性变换变成,然后根据某种注意力机制得到的矩阵进行加权求和,得到一个头的数据,之后多头进行融合。所以重点是如何得到矩阵。
接下来是重点,作者将注意力机制和卷积进行了统一,在浅层网络,作者使用Local的MHRA,即将定义为3D卷积核,根据token的相邻位置进行卷积核中的加权求和;在深层网络,作者则将定义为传统注意力机制的。

所以,UniFormerV2中Local那一路,Local MHRA Temporal实质上是一个的卷积,Global MHRA Spatial就是ViT中的注意力机制。
这绕来绕去的,最后结果还是挺简单的……
Global UniBlock
全局的UniBlock使用了UniFormerV1中提到的Dynamic Position Embedding(DPE),实际上是一个Deep-wise的卷积,使用了论文“Do We Really Need Explicit Position Encodings for Vision Transformers?”中的结构。在这里,是对每个通道的3D特征图,通过3D卷积核来查询周围token,从而动态生成当前位置的embedding。这个结构满足了位置编码的三大要求:1.表现好 2.输入位置扰乱会导致结果不同 3.高效、方便、non-invasive to 原本的transformer。
DPE之后则是一个基于交叉注意力的MHRA,其使用一个可学习的query向量对所有时空token进行交叉注意力,得到video token。然后,视频一路特征还是通过FFN。
Multi-stage Fusion
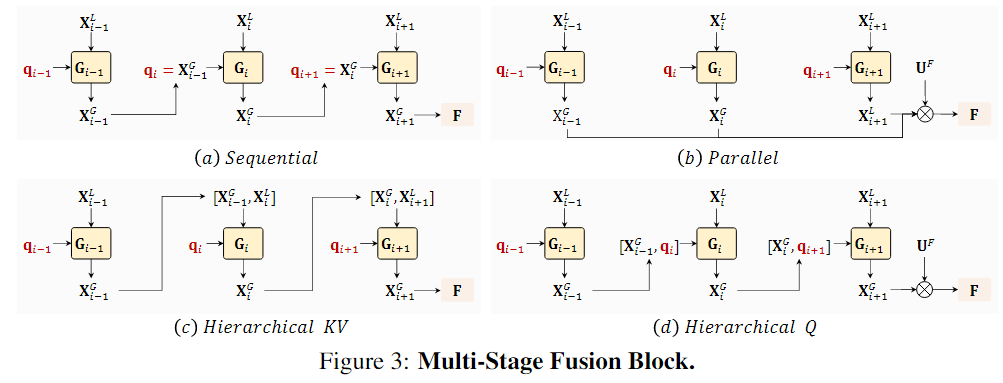
论文研究了如上四种融合方式,是Global一路得到的视频级别query特征,则是每个block的特征,最后得到的特征,这个特征还会根据一个可学习的参数来加权融合Local一路的cls token特征,得到最终最终的特征。
融合方式最终使用了最简单的(a)方法,即自始自终只有一个query,这个query在Global Block中汇聚特征,并作为下一层的输入。
这有一份简化的UniFormerV2的代码:uniformerv2.py · Andy1621/uniformerv2_demo at main (huggingface.co)
InternVideo For 下游任务
模型已经训练出了各种各样的模块,需要什么就选什么。
比如行为识别、时序动作定位这些就直接选VideoMAE-Huge,多模态任务就选多模态对比学习后的……
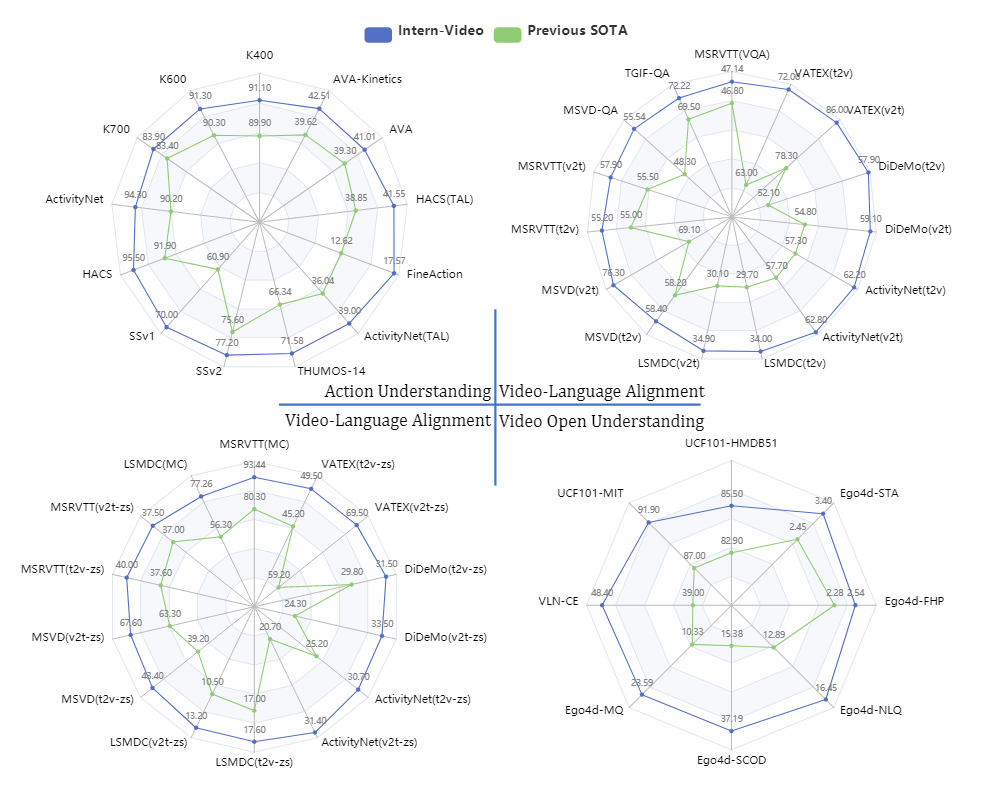
最后是得到各个方面的SOTA,当然参数量也非常之多。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!