论文笔记 ActionFormer:Localizing Moments of Actions with Transformers
本文最后更新于:2024年3月25日 下午
论文笔记 ActionFormer:Localizing Moments of Actions with Transformers
南京大学计算机软件新技术国家重点实验室的一篇ECCV2022论文,提出了时序动作定位(Temporal Action Localization,TAL)领域的一个新的架构,被后面非常多模型作为baseline。
论文链接:ActionFormer: Localizing Moments of Actions with Transformers (arxiv.org)
代码链接:happyharrycn/actionformer_release: Code release for ActionFormer (ECCV 2022) (github.com)
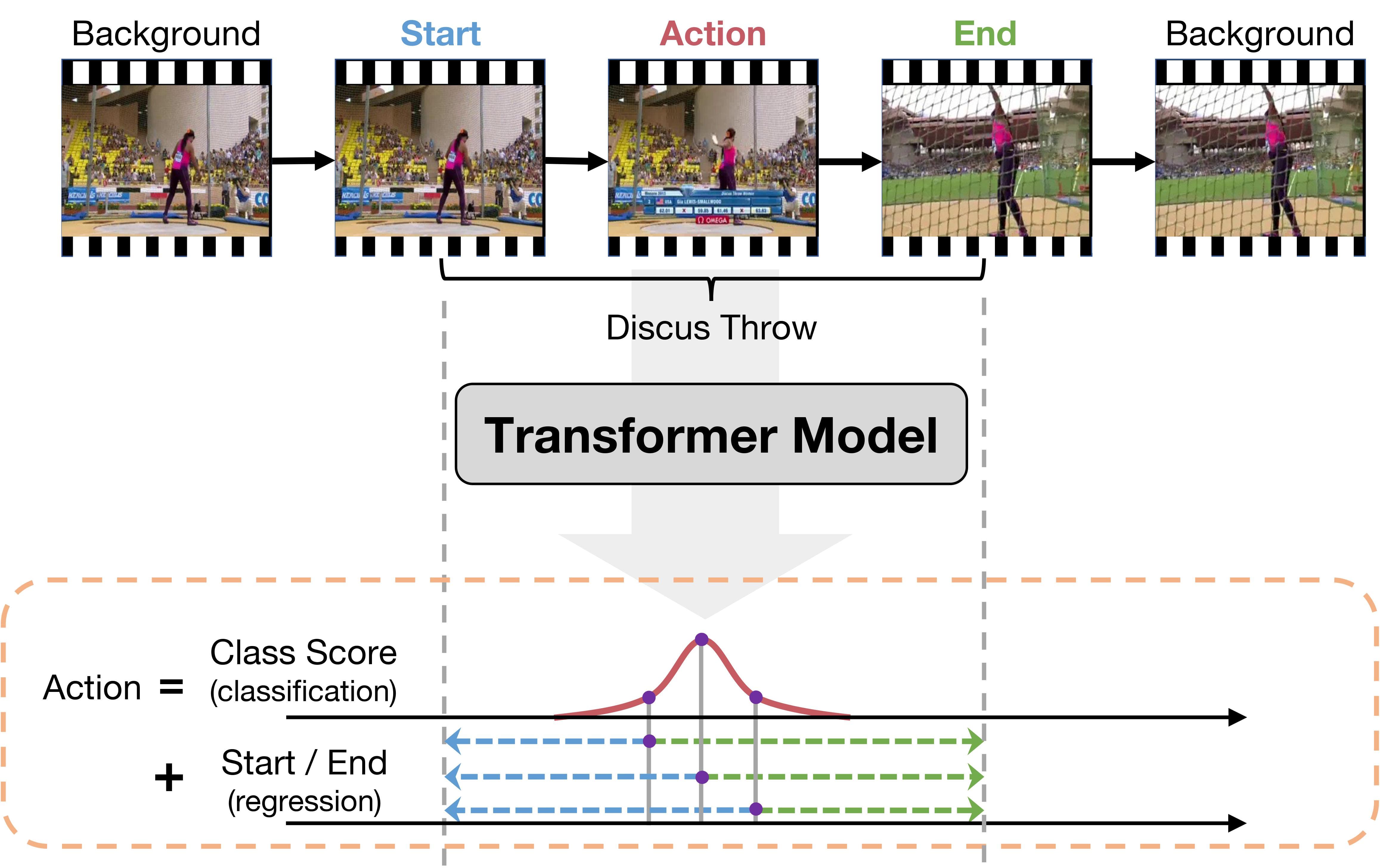
论文主要提出了下面这种动作定位的1-stage范式,视频按帧/片段通过Transformer编码,每个token预测类别分数以及距离开始和结尾的距离。
方法
任务定义
TAL任务对于视频序列,要求预测其标签,其中,每一个,表示视频中的一个动作片段,包含了开始时间(onset)、结束时间(offset)和类别。
而ActionFormer旨在对于每一个时间点的特征,预测,包含类别概率分布、距离开始时间的距离、距离结束时间的距离,这些距离明显都大于0。
ActionFormer预测的结果可以转换成TAL任务的片段:。
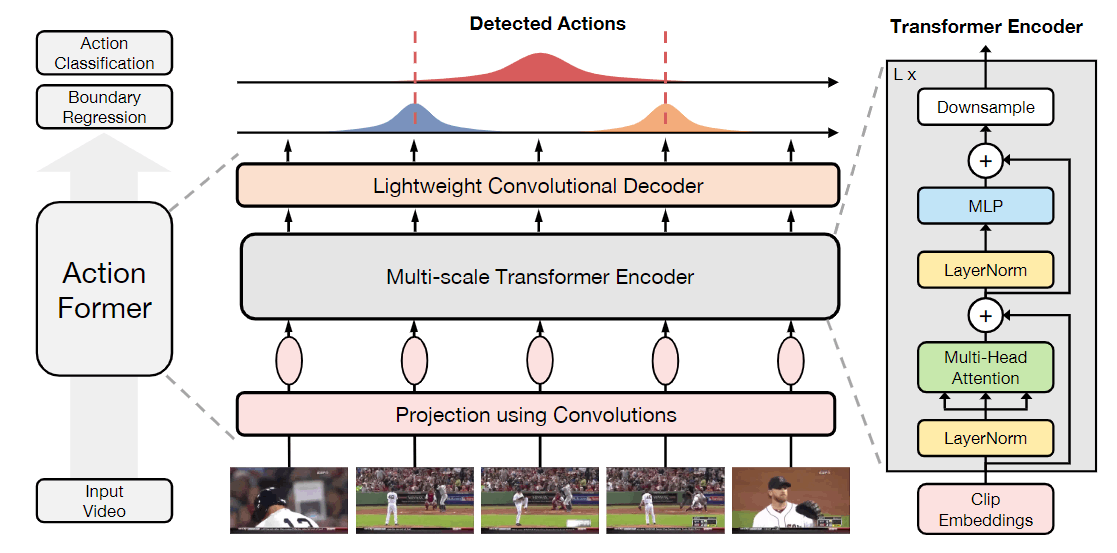
ActionFormer
首先,视频通过卷积网络+ReLU被映射成token,然后加上位置编码,组成token。
其次,这些token通过Transformer的编码器进行编码,特别地,由于计算复杂度的关系,这里限制注意力在一个local window(使用这篇论文方法 Rethinking Attention with Performers,ICLR21)。并且,为了获得多尺度的特征,ActionFormer选择性地在Encoder Layer后加上Downsample层,即一个depthwise的1D卷积,下采样到原来的1/2。
之后,token经过一个轻量的卷积层作为解码器,即通过cls head和reg head进行预测。其中,cls head是3层的kernel size为3的1D卷积(+Norm+ReLU),最后通过sigmoid得到C个类别的分布,对于多尺度特征的每一个token都会预测分布。reg head则对于在动作时间段内的token预测两个距离,和cls head的设计一样,只是最后使用ReLU进行激活。
最后,分类问题使用Focal Loss,回归问题使用DIoU Loss。对于分类任务,作者使用了Center Sampling的技巧,仅将动作中心附近的token看作positive的token,尺度更小时center interval更大,尺度更大时center interval更小。对于回归任务,不同尺度特征对回归范围进行了限制,即令每一层尺度特征预测不同长度的事件。
推理
多个尺度能得到很多action candidates,通过Soft-NMS进行去重得到最终的结果。
实验
本文只看部分消融实验:
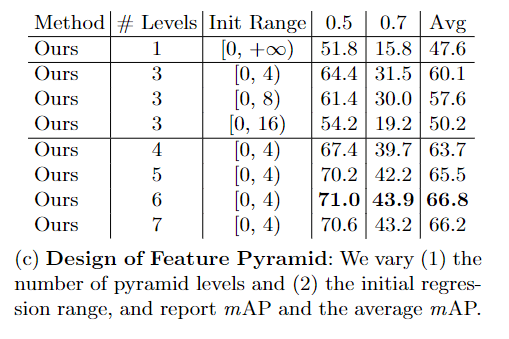
上图是对于特征金字塔和回归范围的消融实验,最后是选择的6个level的特征金字塔,并且回归范围设置成,如下所示

transformer1层的输出是尺度最小的特征,其回归范围为,即检测4s内的事件,而transformers2的范围就变大到,检测4s到8s内的事件,以此类推……

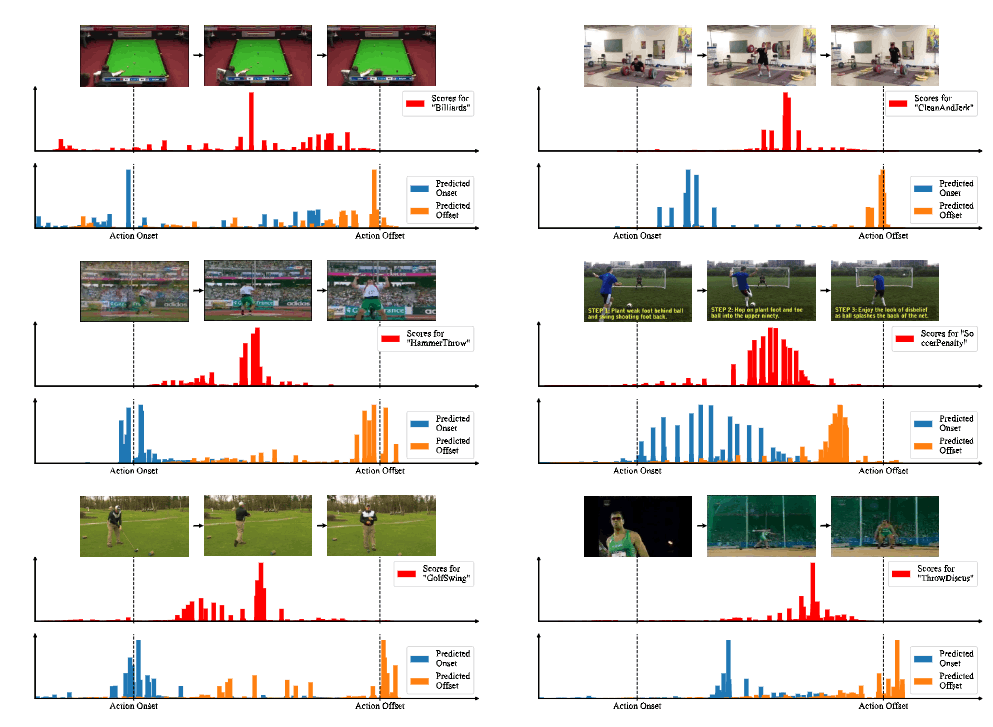
如上图所示是两个例子,第一行是视频,第二行是预测行为分数,可以发现中间部分的分数最高,第三行是对应预测的开始和结束时间,可以发现都在gt的附近。下面是附录中更多的例子:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!