论文笔记 VadCLIP Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
本文最后更新于:2024年1月22日 下午
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
论文链接:VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection (arxiv.org)
论文代码:nwpu-zxr/VadCLIP: VadCLIP official Pytorch implementation (github.com)
西北工业大学王鹏组在AAAI24的一篇文章,提出了VadCLIP模型,利用了CLIP+prompt来加强视频异常检测,属于一种扩展CLIP到VAD领域的方法。
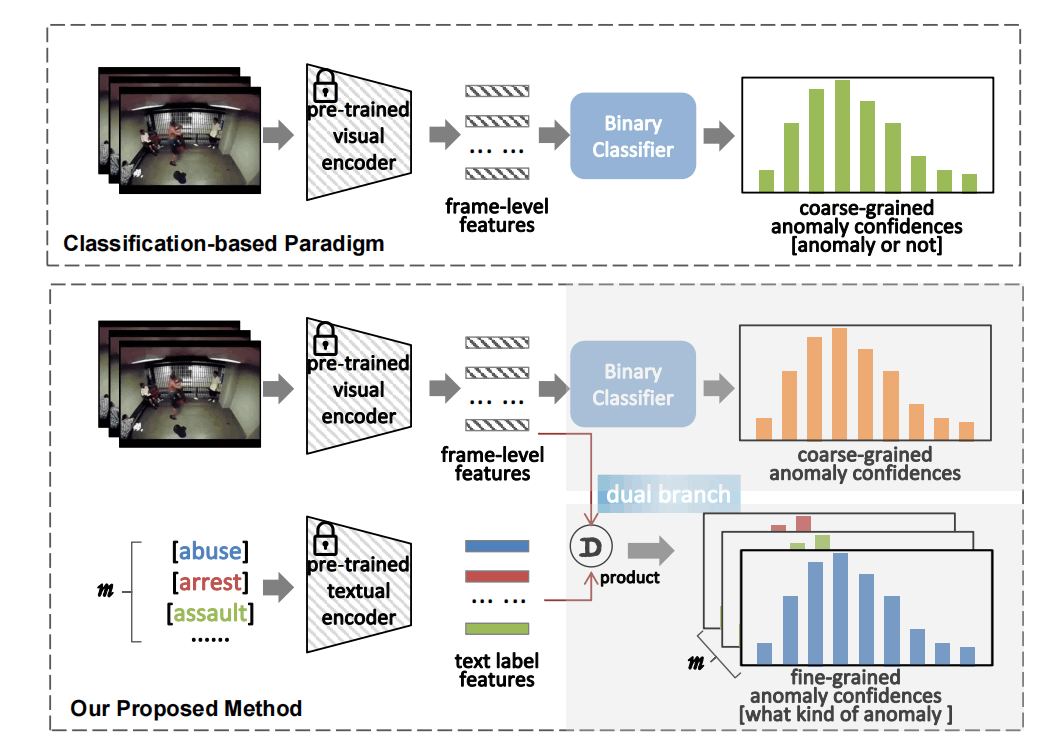
文章考虑了三个问题,第一是如何获取上下文信息、第二是如何利用CLIP的视觉-语言的关联、第三是如何在弱监督下学习。
对于第一个问题,该文章提出了一种local-global temporal adapter(LGT-Adapter)来使用adapter的方式建模时序信息(这里把时序叫做上下文)。对于第二个问题,如下图所示,该文章通过C分支和A分支的两路学习来应对。C分支是粗粒度的二分类问题,A分支则利用了视觉和文本的特征。对于第三个问题,该文章使用多实例学习(MIL),并在A分支额外使用了一种MIL-Align的机制。
方法
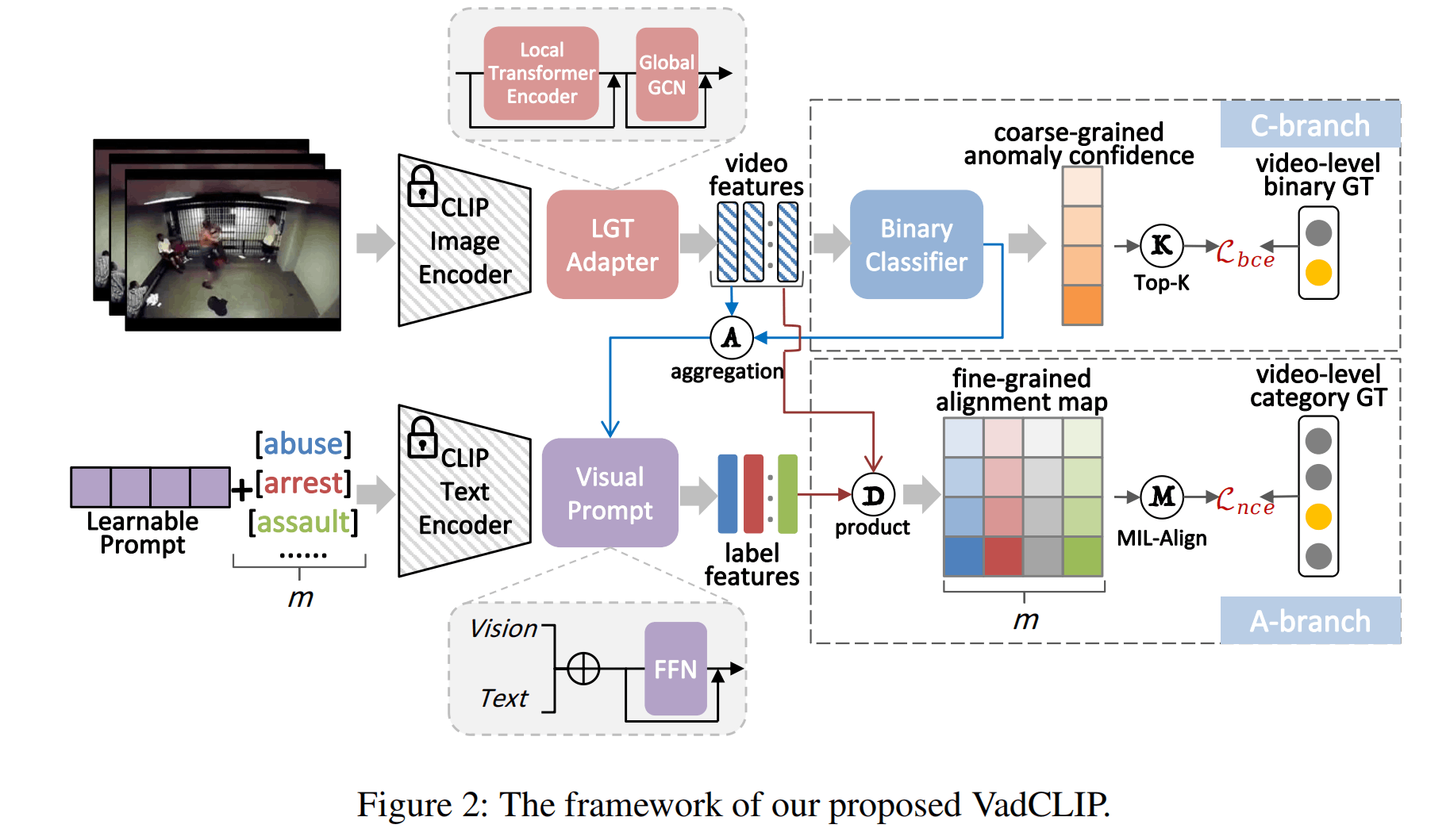
LGT-Adapter
帧级别特征先经过一个Transformer作为Local的信息,这里引用了Swin-Transformer,应该是限制在了局部。
之后紧跟一个GCN作为global的信息,这里引用了之前的一些同样用GCN的文章,GCN在VAD中属于一个不错效果的模块。
是相似度的邻接矩阵,是距离的邻接矩阵,Softmax将每一行归一化,然后根据这个权重与每一个节点(每一帧)的特征相乘,然后再与可学习权重相乘。相似度使用余弦相似度+阈值过滤,距离使用相对距离(相差帧数)+权重系数。
Dual Branch
C-Branch是传统的二分类,A-Branch是新颖的video-text对齐。
C-Branch包括MLP构成的Binary Classifier,没什么特别的。最后用top-K的弱监督MIL损失。
A-Branch是将分类加上Learnable Prompt,送入CLIP文本编码器得到embedding。这些embedding将作为语言知识的先验来服务于VAD。C-Branch得到的异常分数作为权重与之前提取的帧级别特征相乘并标准化得到d维的向量。之后与文本向量叠加再过一个FFN融合得到由类别文本引导的类嵌入,最后与视频帧级别特征计算相似性矩阵(m个label,n帧)。
对于A-Branch的损失,该文章对于的每一行选出top-K个并进行平均,获得视频对于每个类别的匹配度,匹配度使用带温度系数的softmax转换成概率意义,然后使用交叉熵计算损失。
额外的,为了让正常文本嵌入与异常类别的文本嵌入相区别开,会添加一个对比损失,如下所示,就是正常类别与其它类别的余弦相似度之和最小化。
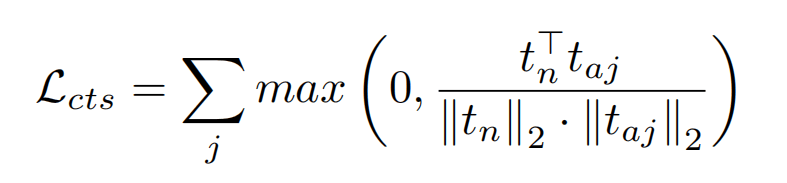
推理过程
对于需要分类的VAD,直接使用。对于不需要分类的VAD,一种方法是用C-Branch,另一种方法是用A-Branch(1 - normal class的概率=异常概率)。
实验
使用了UCF-Crime和XD-Violence进行实验,XD上使用AP、UCF-Crime上使用AUC指标,对于细粒度要分类的任务,文中使用视频动作检测中的mAP@n作为指标。
具体的网络使用CLIP-ViT-B/16,文中的FFN都采用Transformer那样的中间大的MLP,使用单个3090+PyTorch就能训练。
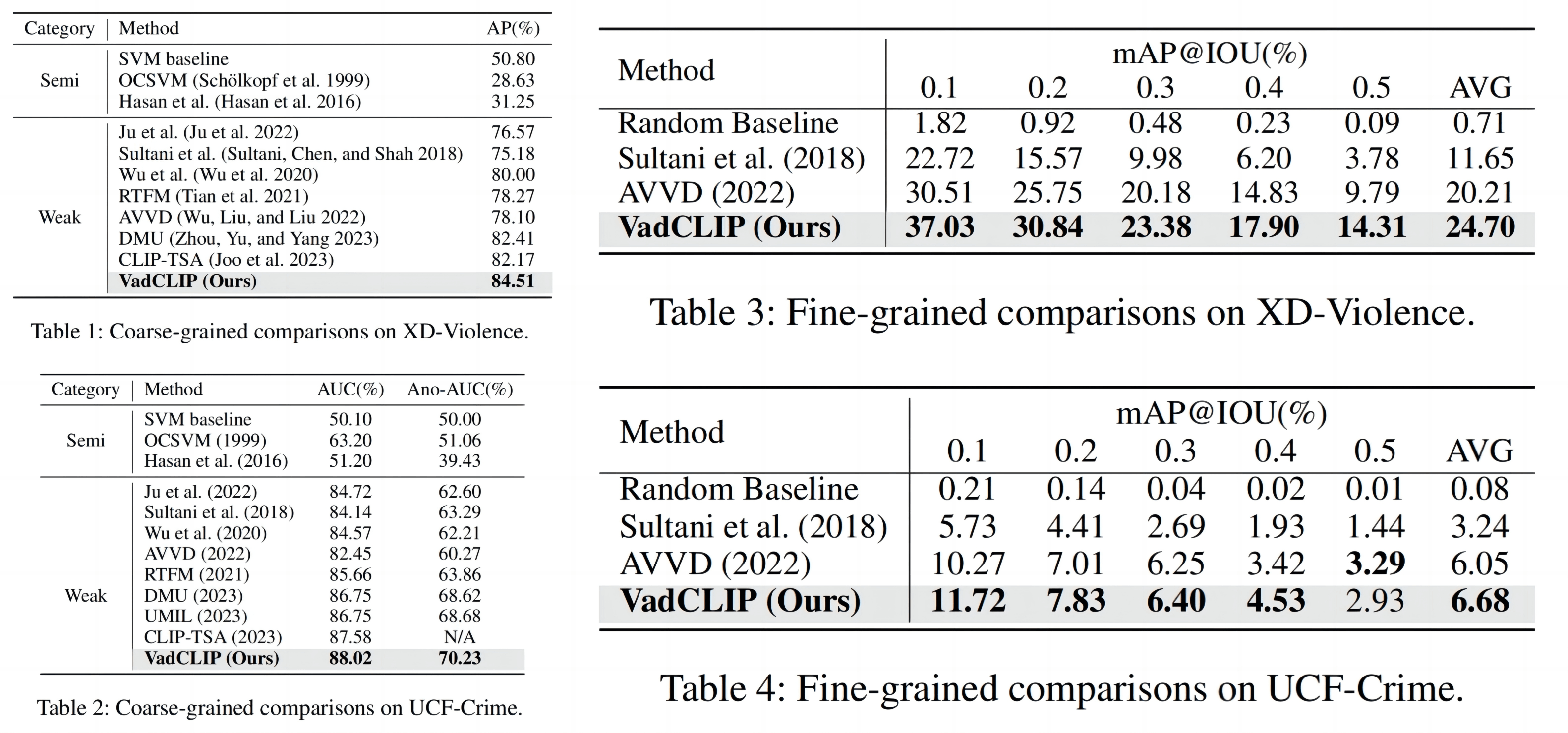
SOTA比较如上图所示,为了公平他只与同样使用CLIP-B特征的方法进行比较,在两个数据集的粗细粒度任务上都SOTA了。
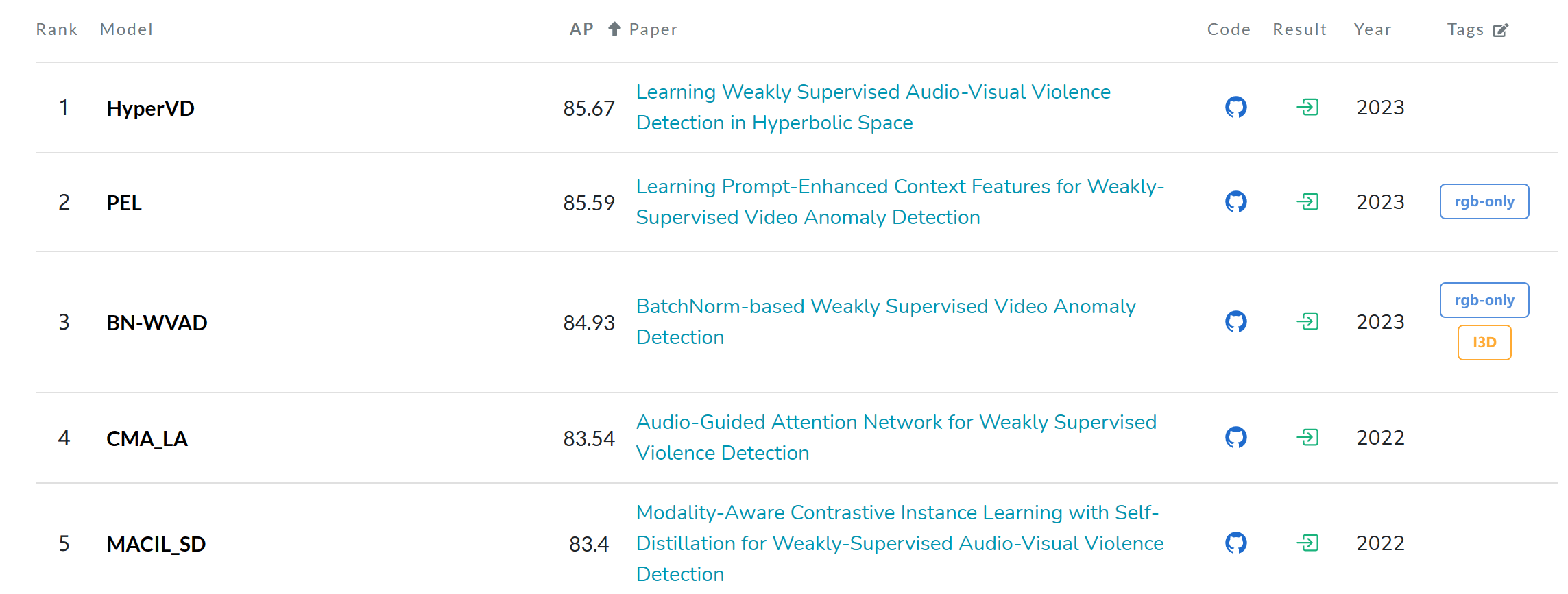
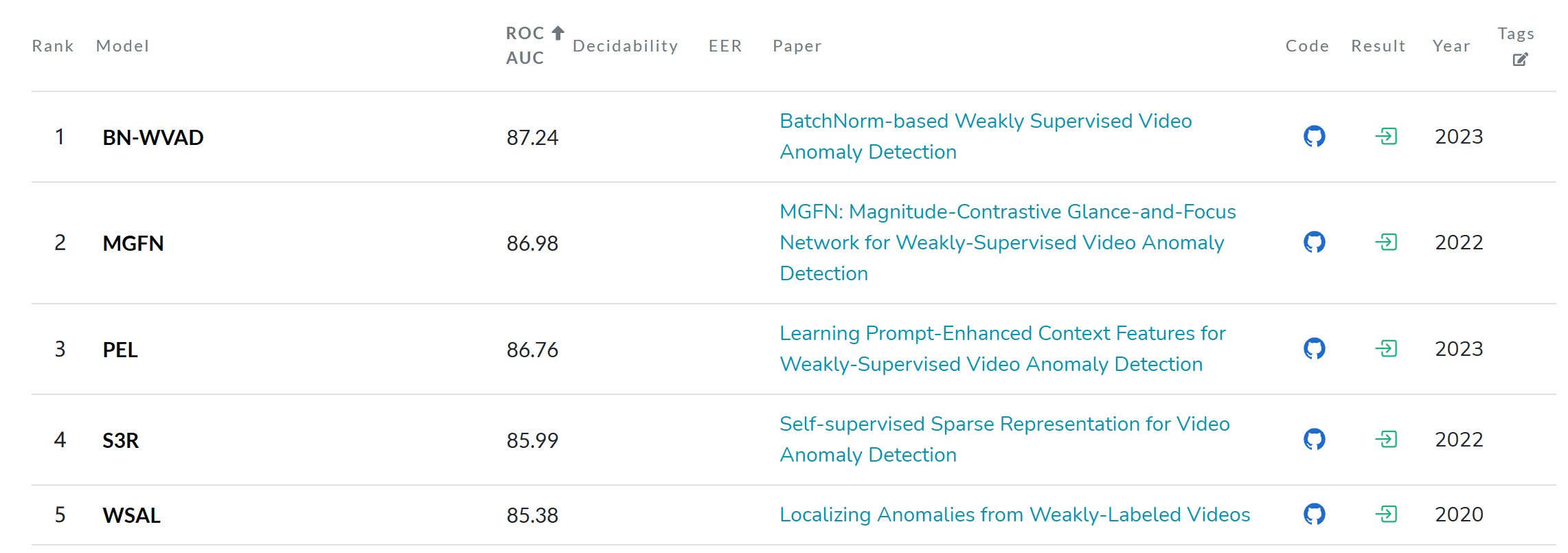
下图是Paper With Code的榜单,Fig1中84.51和Fig2中88.02表现不错,但是其它比较的对象没有选用榜单上的有点奇怪。
下面是一些消融实验:
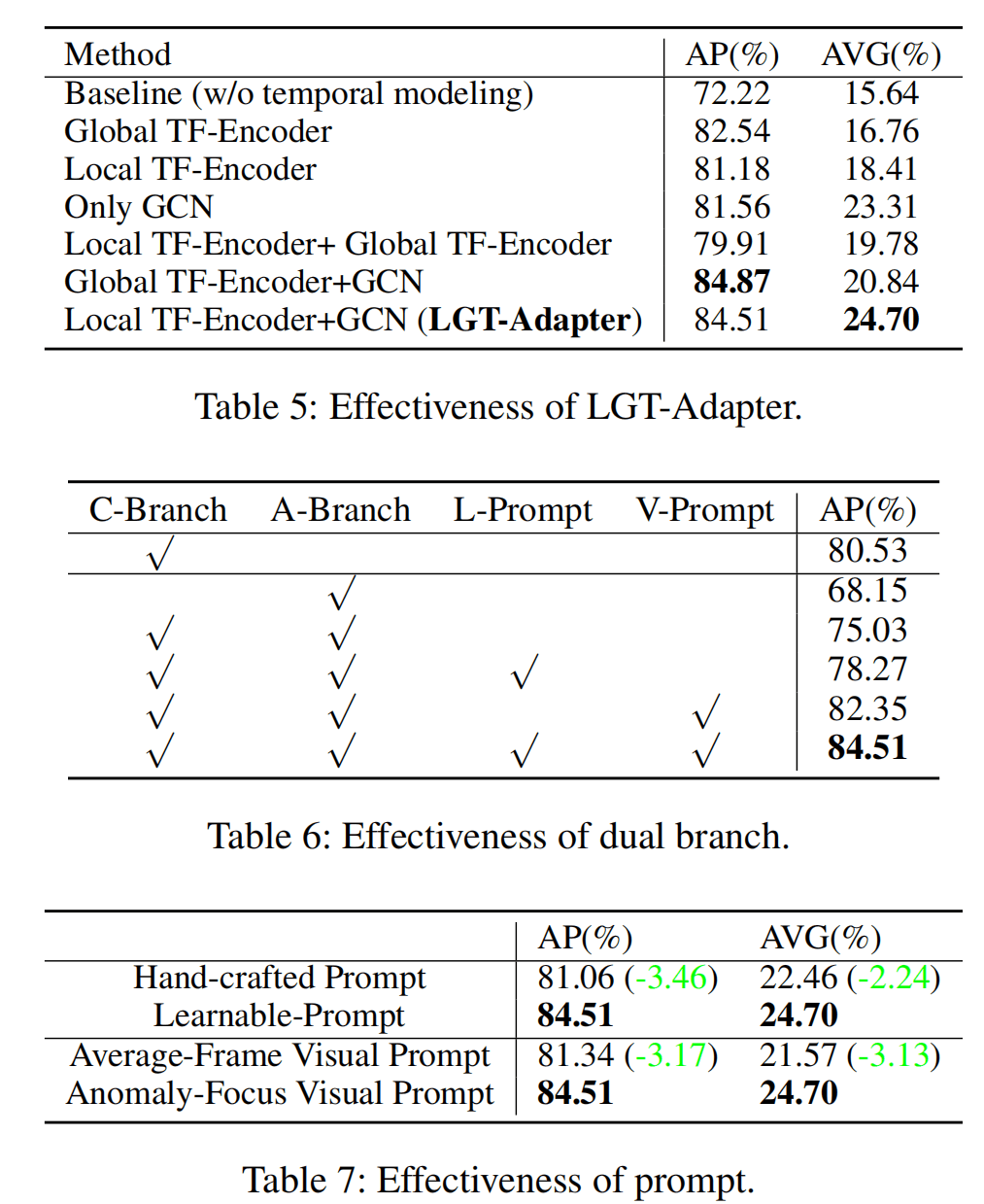
Tab5是LGT-Adapter的选择,别的都显而易见,但是AP最高的倒数第二行没有被选中,文中直接忽略了这一点,最后选择的还是local+global的。
Tab6是Branch的选择,仅使用A-Branch或者简单使用两个Branch效果都变差,甚至在加上Learnable Prompt后效果也不好,直到由Visual参与之后效果才好。文中没怎么分析,这里我觉得可能是因为LGT对特征有破坏,再直接用CLIP Text Encoder的结果去计算相似度效果不会太好。
Tab7是prompt的类别,使用Learnable的肯定是比手工的更好的,然后在visual prompt模块中,使用异常分数加权的方法比直接平均的好,都比较符合直觉。
文中额外放了一些定性的实验结果,没什么特别不一样的。
文中说的补充材料没找到。
总结
论文的总结说未来要继续探索视觉-语言预训练模型的知识,并且致力于做open-set的VAD。(确实是一个好方向)
总的来看,这篇文章与其它利用CLIP的文章来说,额外也利用了CLIP的文本编码器,虽然文中说是一种新范式,但是感觉并没有眼前一亮的感觉。不过mark一下这里用Swin+GCN进行Global+Local的编码的方式。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!