论文笔记 BatchNorm-based Weakly Supervised Video Anomaly Detection
本文最后更新于:2024年1月30日 下午
论文笔记 BatchNorm-based Weakly Supervised Video Anomaly Detection
论文链接:BatchNorm-based Weakly Supervised Video Anomaly Detection (arxiv.org)
中国电子科技大学的一篇23年12月的Arxiv,介绍了一种弱监督视频异常检测(WSVAD)的方法,利用了通过BatchNorm统计的均值与方差,最终在UCF-Crime和XD-Violence上取得了先进的效果。
方法
研究故事
首先,目前的WSVAD只通过二元分类器或者特征幅度来得到异常分数,这种方式文章认为不好。其次,目前方法选择top-k的片段作为异常视频进行MIL学习,而每个视频中的异常比例是不一样的。最后,假如选择错误,对模型的性能影响较大。
最后一点没有给文献,没有依据
这篇文章利用了BatchNorm,通过统计的视角,将远离BN均值的看作异常,靠近的看作正常,这种指标命名为Divergence of Feature from Mean(DFM),利用DFM,这篇文章还提出了一个Mean-based Pull-Push(MPP)损失函数来拉近正常距离,拉远异常距离。
同时,为了克服之前的第二点的问题,这篇文章提出了一种Batch-level Selection(BLS)的异常选择策略,同时结合传统方法的Sample-level Sellection(SLS),最后使用BLS+SLS的Sample-Batch Selection(SBS)。
为了克服第三点的问题,这篇文章仅使用正常视频中的正常片段来训练分类器,避免模型受到错误选择异常点的误导。
整体框架
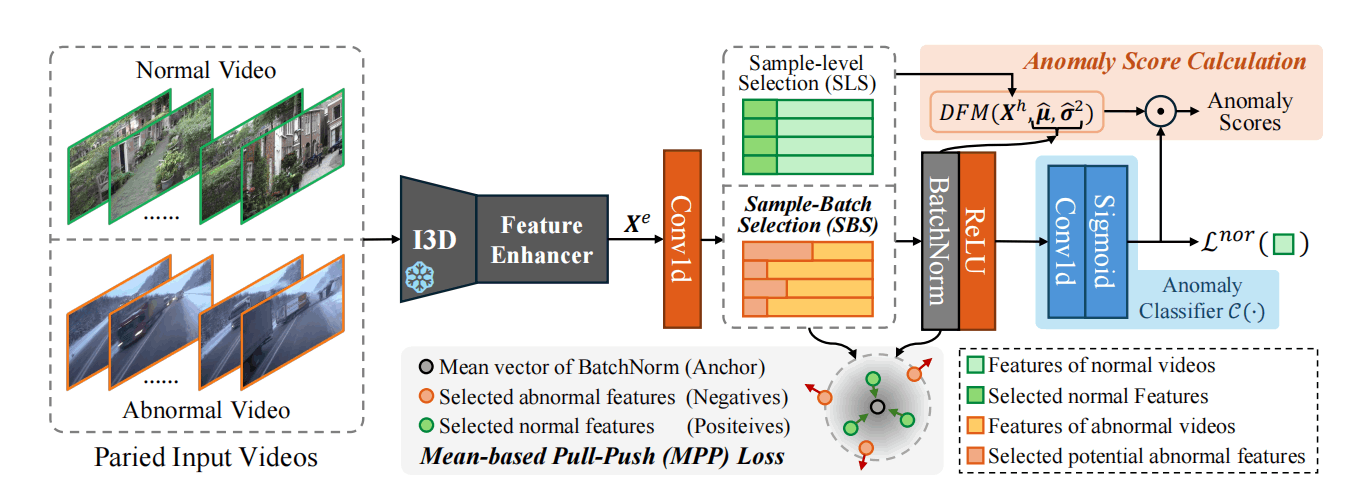
如图,左边是视频输入,通过大家都用的预训练I3D网络得到特征,然后跟一个 Dual memory units with uncertainty regulation中出现的特征加强层进一步编码。之后使用不同的采样方式得到正常片段和异常片段,送入MPP loss。需要用到的均值与方差在接下来的BatchNorm中得到。最后是一个只有正常片段会送入的分类器。最终的异常分数由DFM和正常分类器分数综合得到。
DFM
这个是BatchNorm的均值计算公式,就是对于每个特征,在Batch和片段范围内求均值。
DFM定义如下,是根据特征距离均值的Mahalanobis distance(马氏距离)
其中协方差矩阵的实现是对角线是BatchNorm统计出的方差。特别地,这里BatchNorm的权重通过EMA来更新。
MPP
根据DFM,从异常视频中选出K个异常特征作为,从正常视频中选出K个正常特征,然后对其以均值为anchor,使用三元组损失:
三元组损失选择的positive和negative应当是配对的,这里没有显示出这种配对,看上去比较奇怪。而且这个loss是不是少了个“取正”?现在是会出现负数的。
SBS
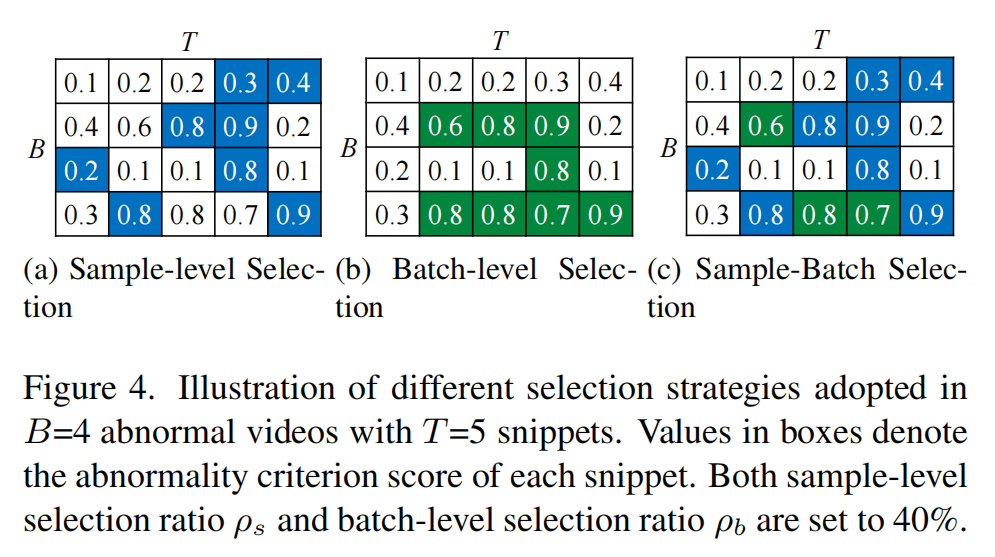
(a)是原来的方法,在每个样本中选择top-2个作为异常;(b)是这篇文章的方法,在batch级别选择top-K个;©是两者的并集。在选择异常视频使用SBS,在选择正常视频时使用SLS。
损失函数
仅选择batch内正常的的视频,由于采样时一个batch一半正常一半一异常,所以这里是总共只有个。对正常视频的特征经过一部分网络之后,最后最小化其值。
总共的损失函数为和两项,后者采用了类似多头的机制,通过两个不同的Conv1D层来获得两个,然后分别计算mpp。
异常分数计算
异常分数根据DFM和normal分类分数相乘得到
实验
在UCF-Crime和XD上进行实验,主要Follow一篇AAAI23 Oral的UR-DMU,使用I3D提特征,额外在XD上提取VGGish的音频特征。
音频?????哪来的?
整体来看,实验比较扎实,下面对部分结果进行介绍:
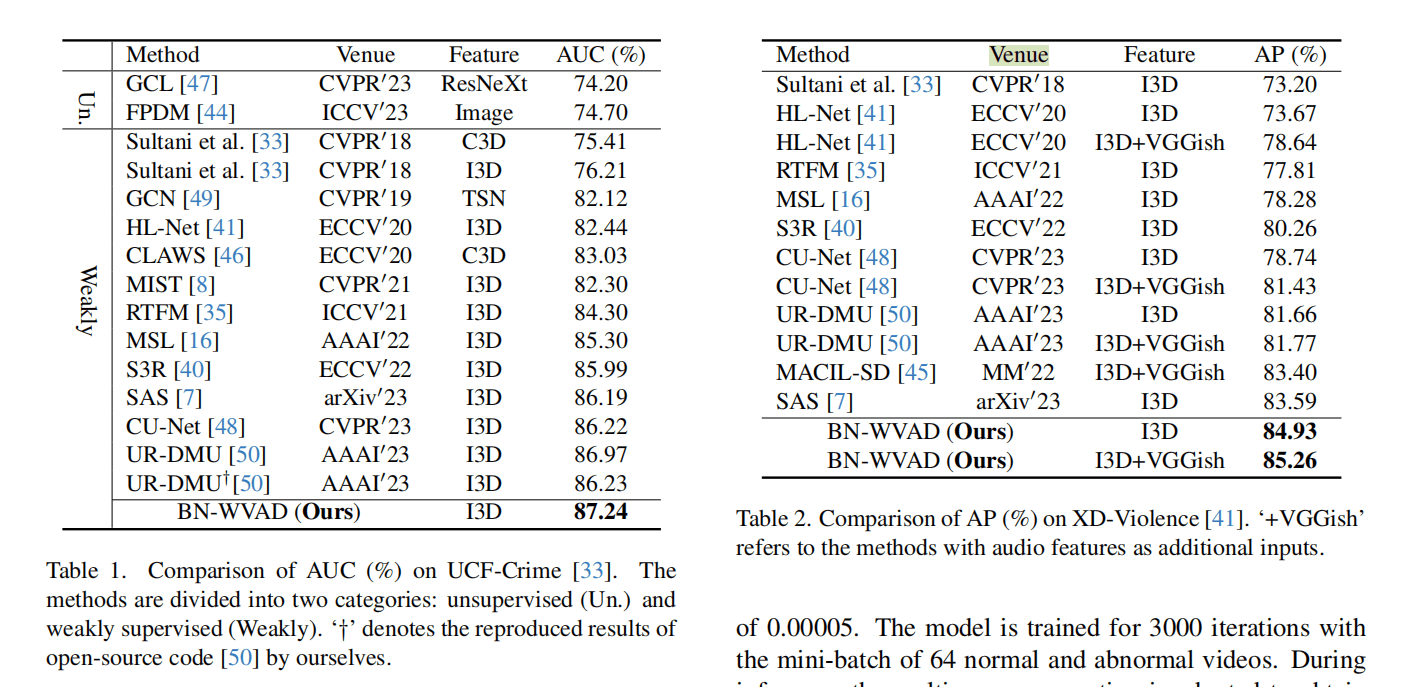
两个数据集上的SOTA结果。

几种策略的可视化,第1行是得到的异常分数,第2-4行是不同策略的选择。这里两个视频构成一个batch,绿色的是ground truth的正常,红色是ground truth的异常。SLS策略在每个视频中选取top-k,结果包含异常较短的左边视频就选择过多了,异常较长右边视频就选择过少了。BLS策略在batch中选择top-k,结果左边视频一个都没有。SBS结合两个,结果覆盖了所有异常片段(但是也有错误的情况,文章说是不可避免的)。

特征的t-SNE可视化,左边是没有利用MPP,只做正常分类器的结果(这个baseline感觉过于低了,应该用基于MIL的损失?),右边是使用了MPP损失的结果。
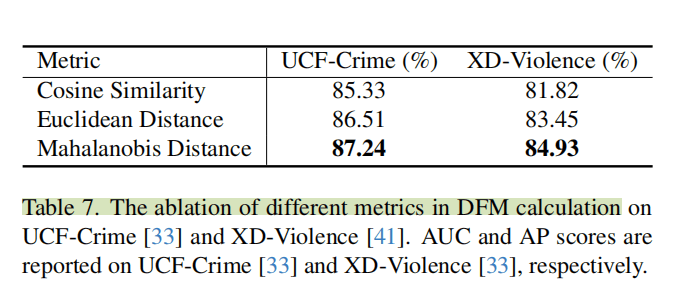
感觉这篇文章使用马氏距离比较不一样,对比发现是能够提高好几个点的,这在baseline较高的情况下实属不易(马克一下)。
总结
这篇应该是投期刊的文章,实验做得很多,内容很充实,超参调节、可视化等都有,整体写作也没什么大问题,但是方法有点过于简单了。
文中对于的动机感觉不充分,训练一个单个类别的分类器是要大量数据才能比较好的,而且这个loss只用正常的训练,难道不会把所有特征坍塌到一个点上吗?
可以借鉴的可能是样本选择的思想,要根据某些策略而不是简单的top-k来选择比较好。
马氏距离原理有待进一步研究。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!