论文笔记 FLIP Scaling Language-Image Pre-training via Masking论文笔记
本文最后更新于:2023年6月25日 下午
论文笔记 FLIP Scaling Language-Image Pre-training via Masking论文笔记
论文链接:CVPR 2023 Open Access Repository (thecvf.com)
Meta AI的CVPR2023论文,Kaiming He是通讯。论文受到MAE的启发,把图像的部分区域Mask掉之后送入视觉编码器,和MAE一样,被Mask的Patch直接丢弃而不是替换为[MASK]的Token,所以能够提升训练效率。而这篇论文还发现,只做Mask,不做Reconstruct的效果也很好。
方法介绍
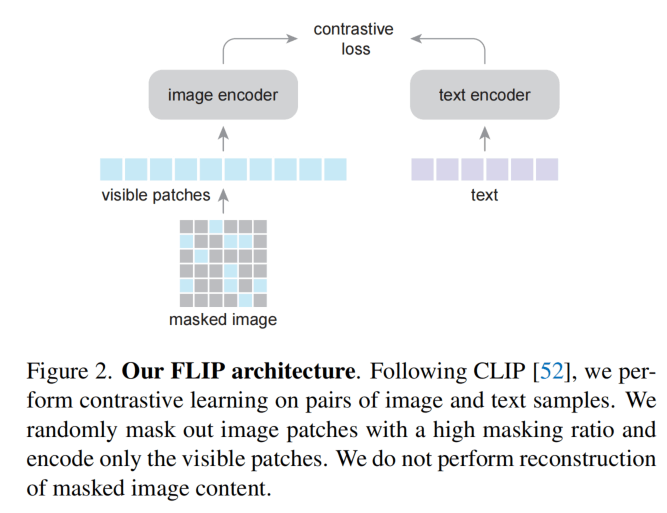
实际上这个方法也没什么好介绍的,图像划分Patch之后加上空间编码,然后去掉50%~70%的Patch,从而得到2倍到4倍的效率提升。
FLIP主要研究这种mask对于scalability的提升。
既然对视觉从侧做了mask,文本侧也尝试了做mask的效果,后续有消融实验。
由于预训练和推理有一定的差距(训练有mask,推理无mask),所以考虑了训练后期不mask。
实验

Table1概括大部分关心的消融实验。
(a b):mask可以容纳更大的batch size,带来更好的效果
(c):Text masking没什么用,因为文本信息更密集,mask率要更小,但是小了又带来不了什么效率的提升,所以就算了。
(d)预测的时候就不用mask了,带mask虽然和训练统一了,但是会降低性能。
(e)训练后期不用mask可以带来提升
(f)MAE重构损失没用
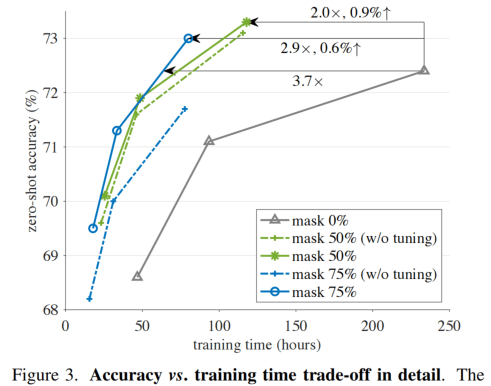
Fig3对比来看,mask50%比较好,收敛很快,最终性能也更好。
Table4~7与CLIP进行了超级多个数据集的全面对比,这里不放图了,总之就是更好。
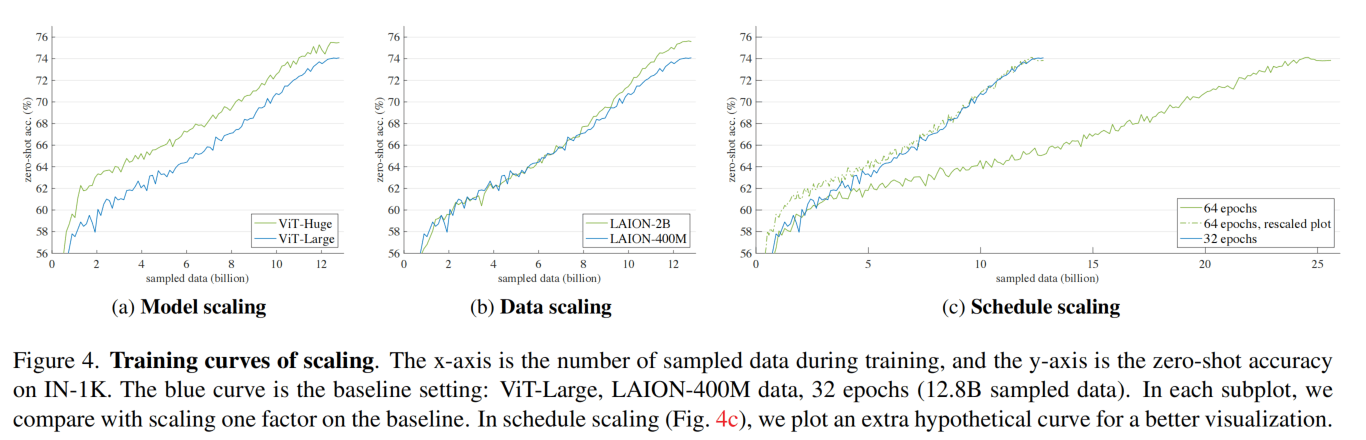
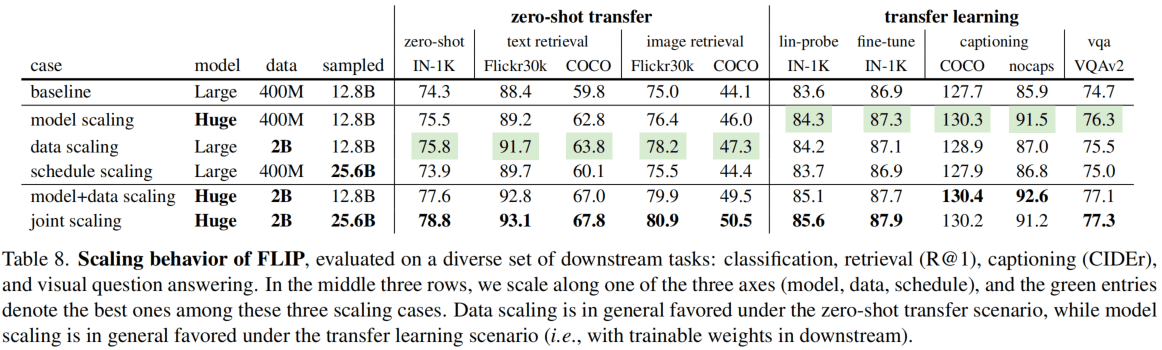
Fig4和Table8验证了这种方法的scalability。
总结
文章给出了一个信号:Mask也可以不重构,像BERT就是重构[MASK],MAE、BEiT、MaskFeat、EVA-CLIP也是重构[MASK]的图像patch,而不重构性能也很高,还不麻烦。(感觉有点类似Dropout的感觉)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!