论文笔记 LiT Zero-Shot Transfer with Locked-image text Tuning
本文最后更新于:2023年6月24日 晚上
论文笔记 LiT🔥 Zero-Shot Transfer with Locked-image text Tuning
论文链接:CVPR 2022 Open Access Repository (thecvf.com)
代码链接:无
Google Brain的CVPR2022论文,探索一种将视觉模型通过对比调优迁移至图像-文本领域,从而展现跨模态能力的方法。方法名称叫做Locked-image Tuning(LiT),非常直白,就是将一个预训练的图像编码器冻结,再令一个文本编码器从零开始学习与图像表征对齐。
LiT可以将数据解耦,从ImageNet这种优质数据源学习到图像表征能力强的图像编码器,然后再通过对比调优使其获得跨模态能力。实验证明这种方法在多种backbone上都有效。
方法介绍
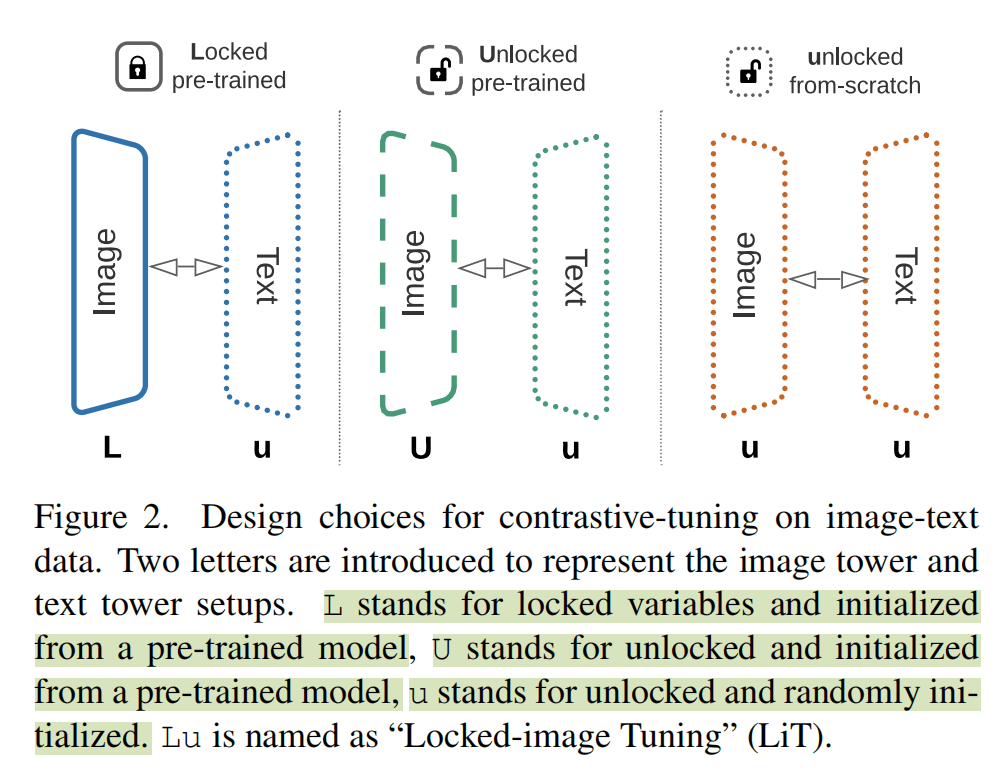
作者用了一种符号表示不同的模型,大写表示加载预训练,L表示冻结,U表示不冻结。所以Uu表示图像编码器加载预训练参数不冻结,文本编码器从零训练不冻结;Lu就是LiT的方法,图像加载预训练冻结,文本从零不冻结。
实验
作者用了两个set数据集,公开数据集是CC12M+YFCC100m,私有数据集是4B使用ALIGN方式收集的数据集。作者训练LiT使用在IN-21K预训练的ViT-L/16。
下图展示对比,私有数据集效果还挺不错,都比公开数据集好,而LiT则每个方面都更好,展现了很强的zero-shot能力。同时这种微调的方法能利用已有数据集。
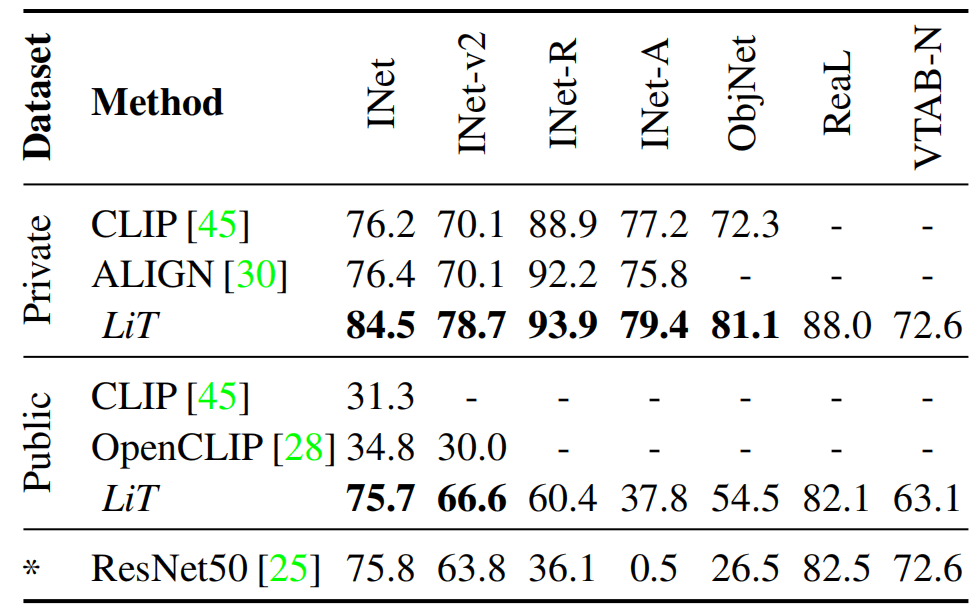
下图Table 2显示图像编码器冻结参数居然比解冻参数好。

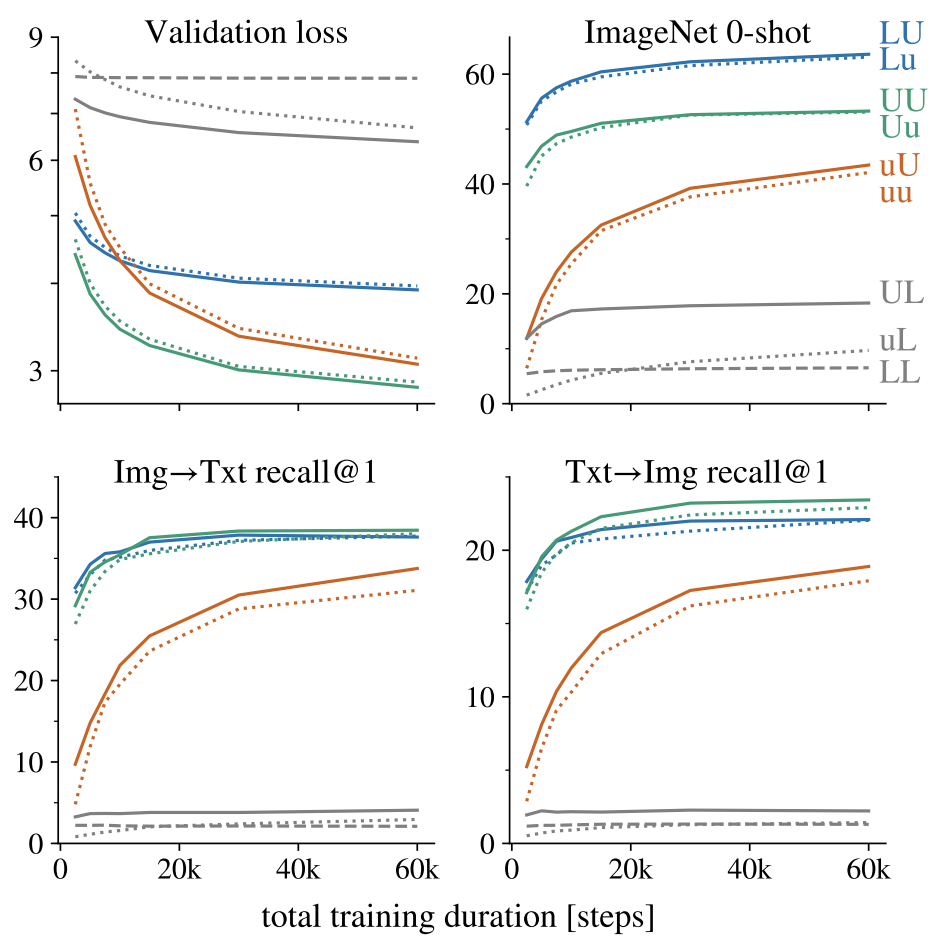
下图发现训练的时候,解冻参数的黄色和绿色能得到更低的loss,其中加载了预训练参数的绿色在检索任务十分强悍,但是这两种却损失了zero-shot分类的能力,没有蓝色的冻结图像模型的强。
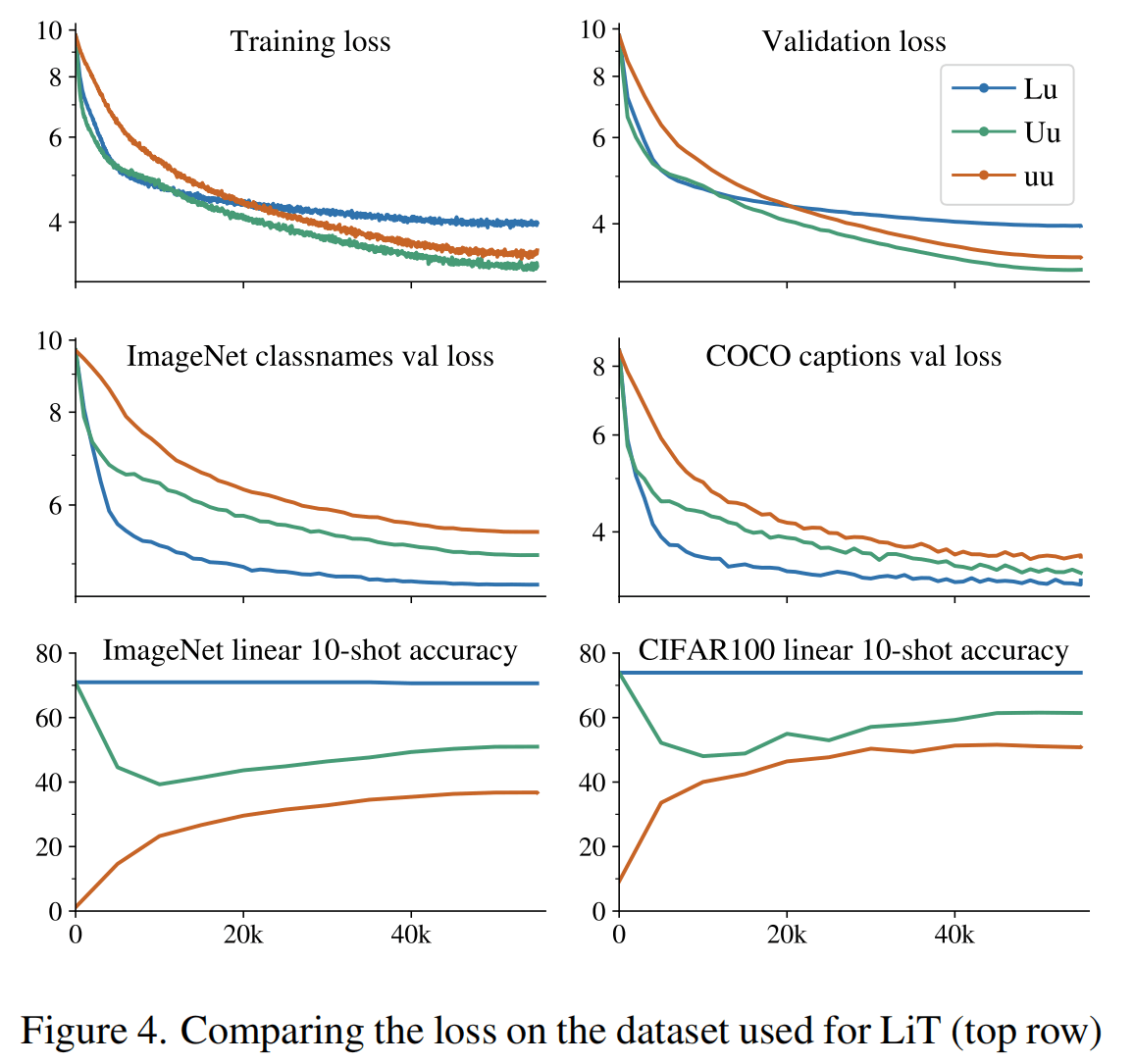
这张图可以把解冻参数带来的灾难性遗忘显示地更清楚,Lu虽然预训练loss更高,但是在其他数据集分类和生成的能力更强,并且10-shot的能力完全没有下降。
作者发现一些在IN上训练的模型有相同的表征能力,通过LiT调优能得到相当的zero-shot能力,但更差的比如在Places数据集上预训练的模型就没有那么强的表征能力了。
虽然作者主要使用的是ViT,但是在附录A用了别的架构。
对于重新初始化的文本模型,作者尝试了CLIP、T5、mT5、BERT几种架构,以及使用SentencePiece和WordPiece的Tokenizer。结果说BERT效果最好,但是训练不稳定,并且架构和CLIP的也差不多,所以归因于初始化和LN的位置,最终还是选择了ViT+SP。
总结
本文说明IN预训练模型获得强大zero-shot可以更简单,重点在于令文本得到适配于图像的高级语义。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!