论文笔记 Image Captioners Are Scalable Vision Learners Too
本文最后更新于:2023年6月24日 晚上
Image Captioners Are Scalable Vision Learners Too
论文链接:Image Captioners Are Scalable Vision Learners Too (arxiv.org)
代码链接:无
Google DeepMind 6/13在Arxiv挂上的一篇revisit类的论文,实验非常扎实,结论是说在做图像-文本预训练的时候,仅使用Caption任务也可以像CLIP那样获得不错的效果(“不错”指Scalable和zero-shot Effective)。
研究介绍
在CLIP之后,使用从web爬下来的大量image-alt-text对进行对比学习预训练非常火热,而文本生成任务也被一些文献(ALBEF、BLIP、CoCa、GIT)证明是不错的监督来源,但是这些工作都是使用了Encoder-Decoder的架构,并进行早期的模态融合,从而进行VQA或者Captioning的任务,并没有单独研究视觉backbone。
这篇文章将captioning看作一个预训练任务,使用和CLIP类似的数据训练,发现这样出来的模型(Cap)在zero-shot分类和few-shot分类上接近甚至超过CLIP。而当把Cap接上一个(新的或预训练的)语言解码器进行下游任务时,在captioning、OCR、VQA任务上效果比CLIP更好。
基于此,作者也提出了一种CapPa的预训练流程:
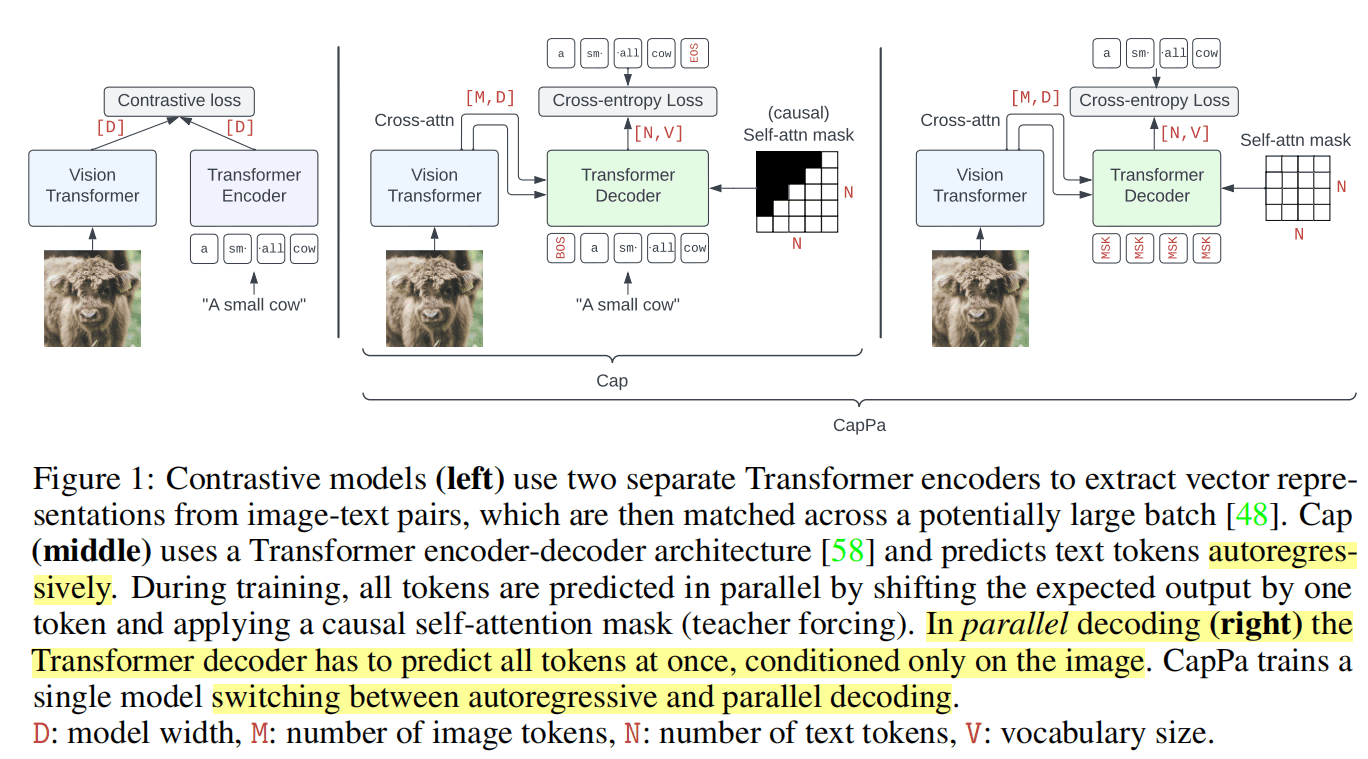
CapPa是Captioning和Parallel prediction的合体,前者就是普通自回归式生成的任务,后者如上图最右边,是非自回归式、一次性生成所有文本的任务。Pa相对于Cap的改变,就是把输入都换成了[Mask]、把attention mask换成了非因果的。
Pa这样的训练难度应该会更高、收敛慢,模型只能根据图像信息和当前位置来生成文本,不能像自回归式那样依靠之前生成的文本。但是这只是针对与进行生成的下游任务而言,使用这么一个难度更高的任务作为预训练任务效果不一定。
作者的CapPa方法在训练时75%概率进行Pa,25%概率普通Cap。
放一段Pa作用的原文,大致说的是Pa可以令Decoder更依赖视觉模型。
Intuitively, captioning via next token prediction induces an implicit weighting on the supervisory signal of the caption tokens: To predict the first few tokens of a caption, the decoder can benefit a lot from using the image information, while to predict later tokens it can rely more and more on already predicted tokens. Consequently, early tokens might provide a stronger supervisory signal to the encoder than later tokens. By contrast, when predicting all the caption tokens independently in parallel, the decoder can only rely on the image information to predict each token.
实验
作者模型使用8K的batch size,Table3说明和CLIP(带星号表示自己训练)的差距不大。这里10-shot linear evaluation是每个类别抽取10个作为训练集,抽取1个作为测试集的评估方法。
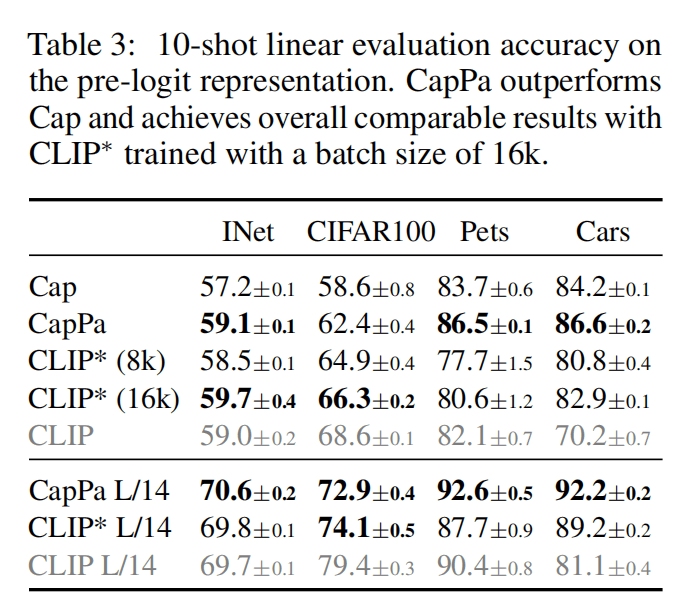
Figure3说明在使用Multihead-Attention-Pooling(MAP)的时候,Cap类的模型差距更小,因为CLIP是通过Linear probe预训练的,但是Cap类没有这个东西,所以CLIP的特征可能更能线性可分。
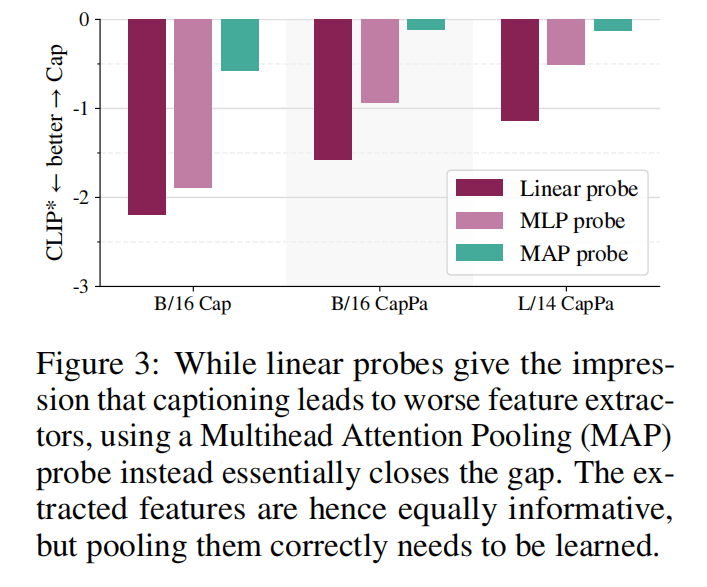
Figure2就是全面超过使用对比学习训练CLIP的图了,左边两列是ImageNet和Stanford Pets(少样本分类任务),右边两列是COCO Caption和VQAv2(生成任务)。
可以发现在少样本分类任务和生成任务上,CapPa的scalablility很强,在相同数据下比CLIP强,在相同大小下也比CLIP强。

Table 6是在ARO benchmark上的结果,发现CLIP这种用对比学习学出来的模型,对于自然语言的顺序不敏感(Order分数低),而Cap和CapPa能接近满分,甚至超过了专业的单模态语言模型(Blind dec)。
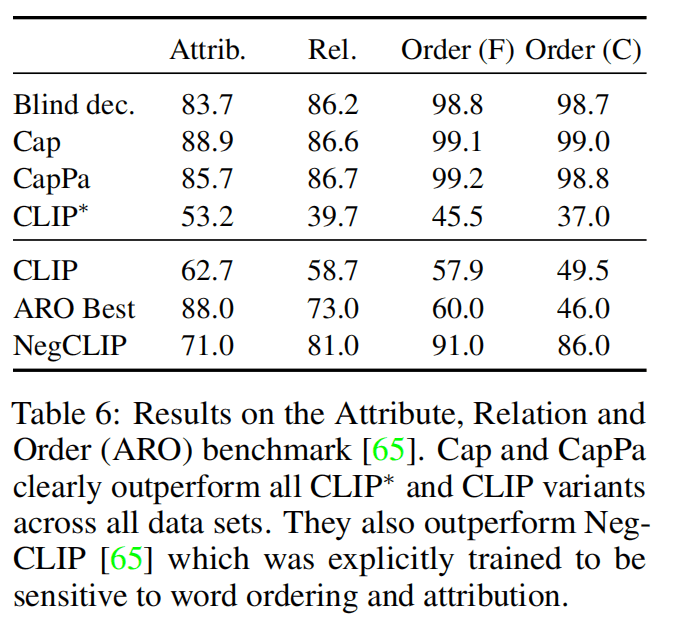
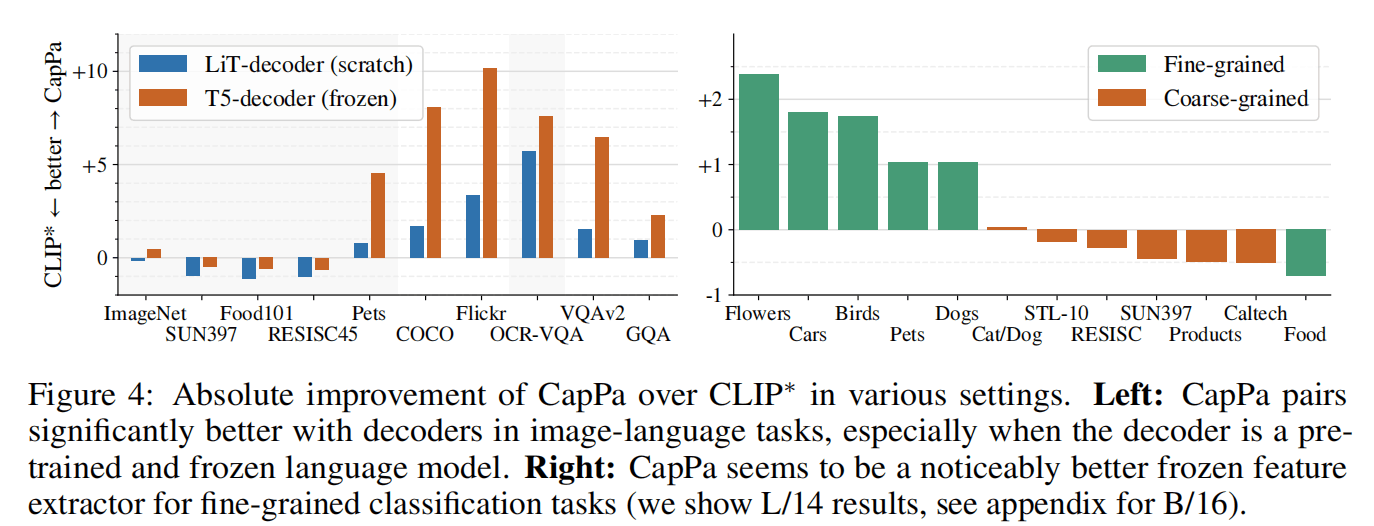
Figure 4展示了不同任务在CapPa的性能,左图证明CapPa在图像-语言任务上效果好,和Fig 2结论相同。右图证明CapPa在大部分的细粒度任务上比CLIP更好。
总结
之前有的文章说预训练以准确生成那些alt-text为目标可能导致性能下降,但是这篇文章提出了质疑。
使用CapPa训练出的视觉模型可能在单词顺序和目标关系很重要的人物中表现更好。
而使用CapPa训练出一个好的视觉模型之后,虽然在检索和zero-shot分类任务上变弱了,但可以再使用LiT的方式更便宜地训练一个在这两类任务上更好的模型。这样训练的效率文中说比CoCa这种使用两类loss预训练的方式更便宜。
我的总结就是说这个Pa的方式比较有趣,并且CapPa训练出的更适合生成任务的backbone也可以一用。总之是等后续发展。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!