论文笔记 XCLIP Expanding Language-Image Pretrained Models for General Video Recognition
本文最后更新于:2023年3月16日 下午
论文笔记 XCLIP Expanding Language-Image Pretrained Models for General Video Recognition
论文链接:Expanding Language-Image Pretrained Models for General Video Recognition (arxiv.org)
代码地址:X-CLIP (huggingface.co)、VideoX/X-CLIP (github.com)
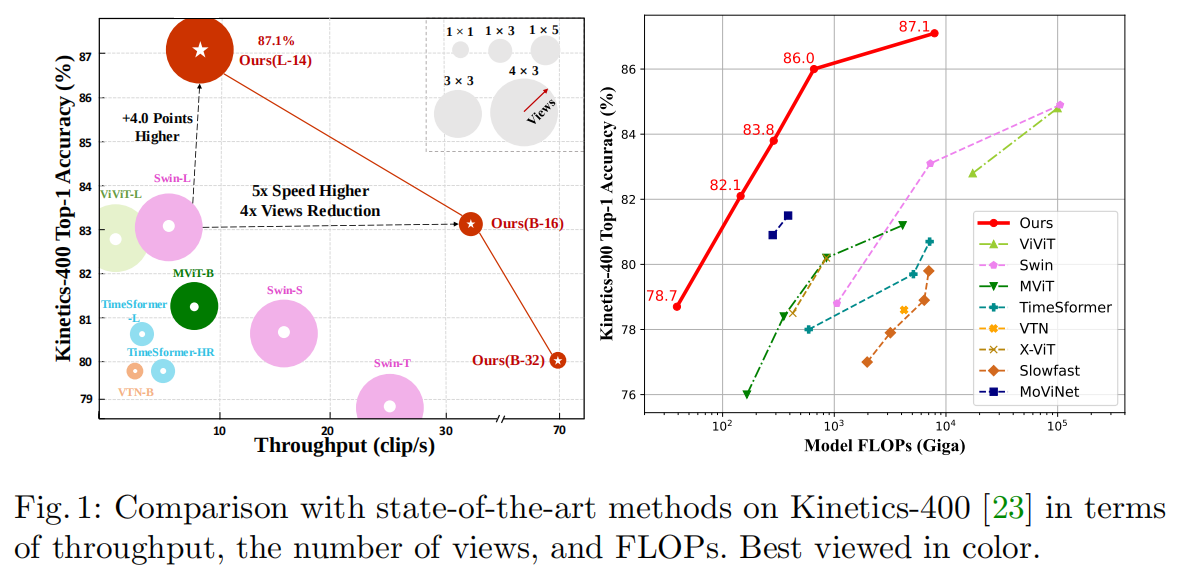
微软和中国科学院发表于ECCV2022的一篇文章,提出了XCLIP模型,其利用了现有的大规模图像-文本预训练模型,设计了一种简单并有效的方法将其扩展至视频识别领域,在K400数据集上以1/12的FLOPs超过Swin和ViViT成为SOTA。
XCLIP的核心包括一个Cross-frame attention mechanism(跨帧注意力),其能够在帧之间交换信息,并具有轻量和模块化的特点,可以容易地插入进大部分预训练图像-文本模型。
模型架构
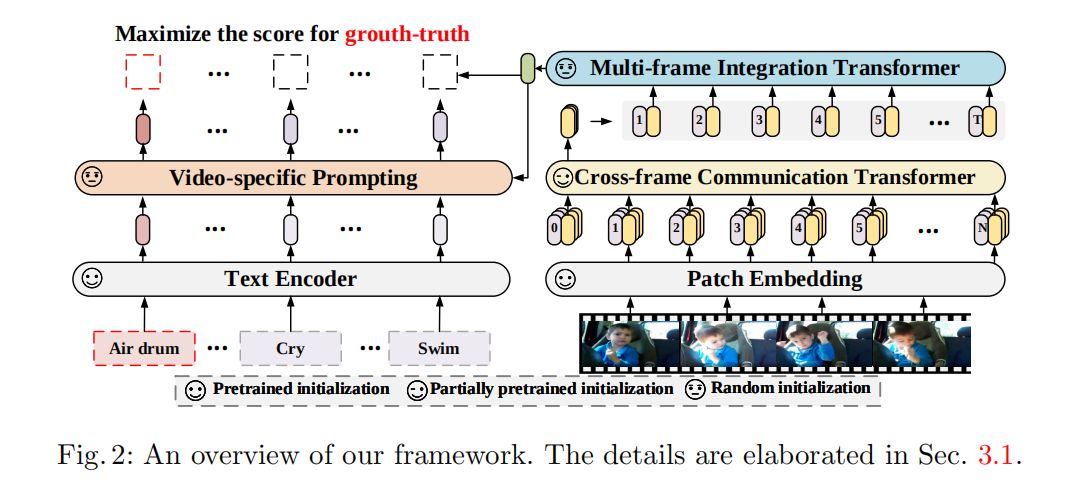
模型架构图如上,视频和文本分别经过视频编码器和文本得到对应的特征,然后文本侧经过一个Video-specific Prompting模块增强文本侧特征得到,最后对应的计算相似度。(这个图上笑脸的标注真的抽象😓)
视觉侧
视频编码器包括Patch Embedding(PE)、Cross-frame Communication Transformer(CCT)和Multi-frame Integration Transformer(MIT)。
PE由预训练模型初始化,视频经过PE之后,每一帧都有一个N+1长度的嵌入(添加了一个[class]token),之后经过层的CCT来获得帧级别的特征。
CCT如下图所示,包含了Cross-frame Fusion Attention(CFA)、Intra-Frame Diffusion Attention(IFA)和FFN三部分。其利用了message token机制,即利用额外的信息token来交流传递信息。每一帧的message token由[class]token经过线性变化得到,CFA是一个带LN和残差链接的普通自注意力层(SA),并且是随机初始化的。
CFA得到message后,和原来每帧的视频token拼接在一起,进入IFA(和CFA结构一样),然后最后再经过FFN(带残差)。
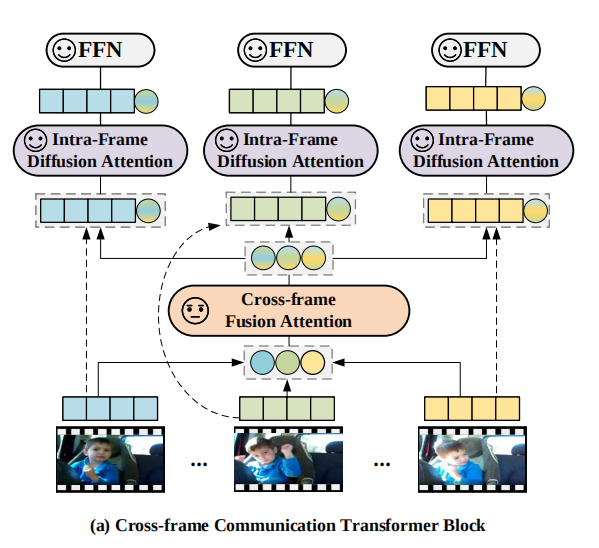
经过CCT,我们得到了帧级别的特征,之后加上temporal encodeing送入MIT进行编码,MIT也是一个普通的自注意力,输出经过平均池化后就是视频的总特征了。需要注意的是,MIT在文章中是一个非常轻量的1层Transformer。
文本侧
文本侧XCLIP使用了Video-specific prompting,这也是本文贡献之一。文章认为像CLIP那样的a photo of a {label}的效果不够好,假如要区分swim和run,从视频语义中额外提取的in the water将有助于分辨。
然而,这篇文章的Video-specific prompting也就是通过多头自注意力+FFN增强了一下文本侧标签的特征,然后再加权加回去。
实验结果
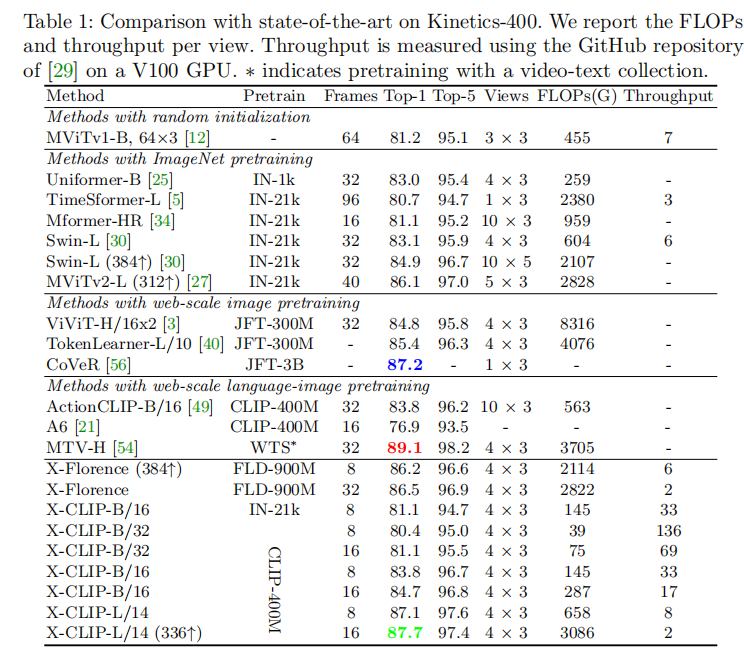
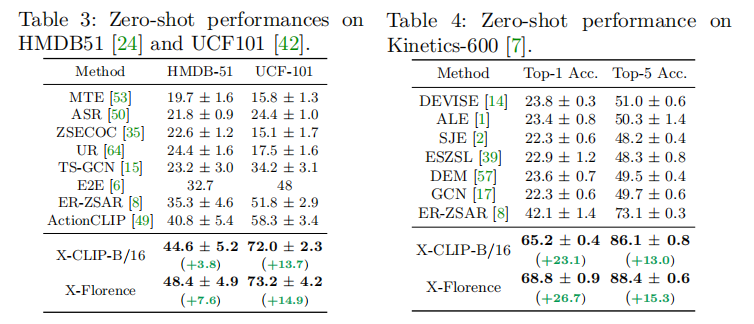
结果上,X-CLIP的效果是非常不错的,并且由于这种设计,还可以进行zero-shot的任务:
观察消融实验结果,可以发现视觉侧的改进增加了1.7%,文本侧则是在这基础上的0.6%,额外的multi-view也是涨点大法。

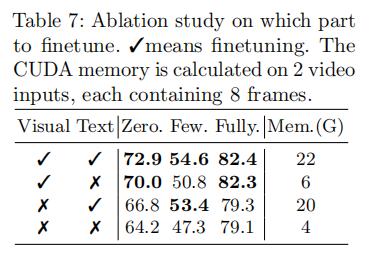
作者还讨论了将现有模型加入本文的方法后,可以只微调Visual部分来实现较好的效果。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!