论文笔记 Zero-Shot Scene Graph Relation Prediction through Commonsense Knowledge Integration
本文最后更新于:2023年2月9日 下午
论文笔记 Zero-Shot Scene Graph Relation Prediction through Commonsense Knowledge Integration
论文链接:Zero-Shot Scene Graph Relation Prediction through Commonsense Knowledge Integration (arxiv.org)
代码链接:Wayfear/Coacher (github.com)
ECML PKDD 2021会议论文,文章通过常识融合提升了场景图(Scene Graph)关系生成的Zero-shot性能。其提出了Coacher架构,针对知识图谱中节点的邻居和路径进行建模,本文主要关注其对常识的利用。
一作二作都是国人,一作是个原p。
主要方法
作者先确定了两个前提:
- 前提1:两个节点拥有更多相同邻居表示其语义更接近
- 前提2:两个节点到另一个节点拥有相同路径表示其语义更接近
上面这两个节点比较直观,比如man的行为和human的行为有很多重复,所以这两个节点会有更多相同的邻居,又比如child和man类似,其与pizza节点的路径也会相似(都与human有关,human又desire食物,食物又包括了pizza)。
根据前提1,可以定义一个基于邻居节点的相似度:
分子是A节点的邻居与B节点的邻居交集,分母是并集。
COACHER整体框架
本文采取了Neural Motif的流程作为baseline,如图包括目标检测(Object Detection)、标签改良(Label Refinement)、关系预测(Relation Prediction)这三部,中间上方的常识结合器(Commonsense Integrator)是本文的新增模块。
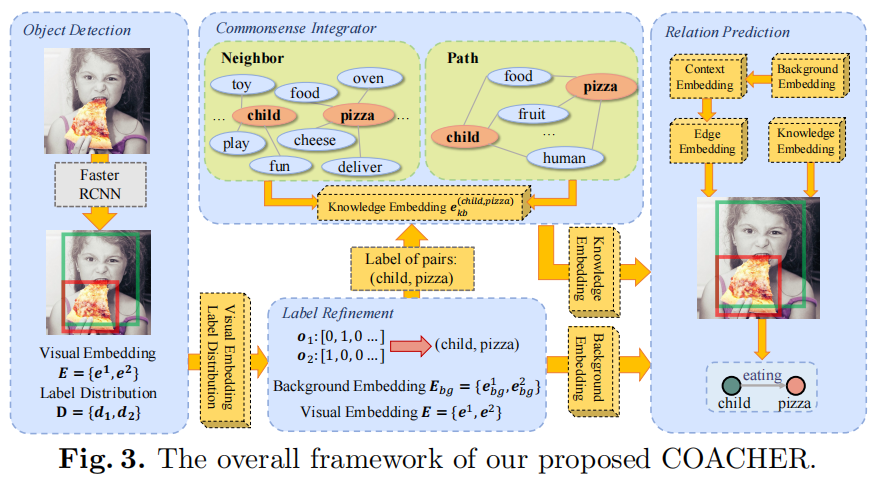
目标检测
目标检测可以采用各种模型,本文采用了预训练的Faster RCNN,对于图像,能检测出Proposal 、其概率分布向量和视觉嵌入向量。
标签改良
对于每个proposal,本模块生成其标签。
本模块先得到整体的特征,这里叫做背景嵌入,其为一个双向LSTM的输出,而每一个时间步的输入是一个目标概率分布经过MLP的向量和目标的视觉嵌入向量的拼接。
之后再用一个LSTM进行解码得到分类的标签。
关系预测
首先得到包含目标关系的上下文嵌入向量,其为一个双向LSTM的输出,而每一个时间步的输入是一个目标背景嵌入向量和经过MLP的目标类别的拼接。
该上下文嵌入向量随后用来提取边嵌入向量,该向量是两个目标经过MLP变化后的点乘。
Baseline中,利用这个边向量经过MLP就能进行边分类。而接下来介绍本文引入的常识向量会和边向量拼接。
常识结合器
本文使用的是ConceptNet来提取常识,ConceptNet本身是一个图,与目标检测模型检测到的相对应的节点为,其邻居节点为.
再令为ConceptNet提供的节点特征,某个节点的邻居嵌入为其邻居节点特征的平均。
本文由此计算出基于邻居的常识嵌入,其为两个节点的邻居嵌入拼接后过MLP。
本文还提取两个节点间的 跳路径,一般最高是3跳,两个节点间路径会构成一个子图,本文使用了类似图神经网络的消息传递网络:某个节点的特征为上一层其特征加上邻居节点的特征(大概是这样),这样传递层就能获取到特征。得到特征之后使用GlobalSortPool运算得到最显著的一些路径特征。
每个节点的特征可以用节点在知识图谱的特征初始化,也可以使用初始化。
结论
实验和结论省略
总结来说这个方法并不算新颖,也没有给出一些检索出来的常识的可视化。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!