Detecting Twenty-thousand Classes using Image-level Supervision论文笔记(以及目标检测基础知识)
本文最后更新于:2022年11月17日 中午
Detecting Twenty-thousand Classes using Image-level Supervision论文笔记(以及目标检测基础知识)
ECCV 2022(Facebook):Detecting Twenty-thousand Classes using Image-level Supervision
- 论文链接:Detecting Twenty-thousand Classes using Image-level Supervision (arxiv.org)
- 开源代码:facebookresearch/Detic: Code release for “Detecting Twenty-thousand Classes using Image-level Supervision”. (github.com)
- Demo:Google Colab(有用)、Hugging Face Space(貌似出问题了)、facebookresearch/detic – Run with an API on Replicate(可用,最方便)
本文提出了一个Detic的目标检测模型,它能通过利用Image-level的监督标签学习(可以算是弱监督),从而实现20000多类(甚至更多)的检测,并且这种模式能够简单应用于其他检测架构或套用其他backbone。同时,Detic实现的还是open-vocabulary的检测,可以不局限于数据集的标注,不finetune的情况下检测出新的目标。
其真实检测效果如下(我随手在宿舍拍的),其检测到了宿舍里的书、台灯、电脑、人等常见物体,还检测到了柜子、抽屉、锁头(knob)等,甚至还检测到了左上角露出一个脚的玩具熊,左边露出一点点的床帘、右下角的行李箱和桌上的高达(figurine)。

前置知识
由于我不是做Detection的,这里列一些目标检测的基础知识,若您已掌握可跳过。
传统目标检测通常分为两个阶段——Region Proposal Network(RPN)阶段和目标分类阶段。
Stage1:RPN网络
RPN网络用来计算出图像中可能包含目标的Region,其采用anchors+分类+回归的模式。
如下图,先得到一个通过CNN提取出来的特征图(图中是800x600的图像通过ResNet提取了50x38的特征图),然后对于这个特征图的每一个点分配9个anchor,每个anchor包括三种大小和三种长宽比(图中大小是8,16,32,长宽比是1:2 1:1 2:1,结果就是3x3=9种anchor),如图右边,可能会出现一些anchor的边界超出了图像范围,之后会把超出部分clip掉,目前情况就是我们就能得到许许多多的anchors(图中为17100个)。
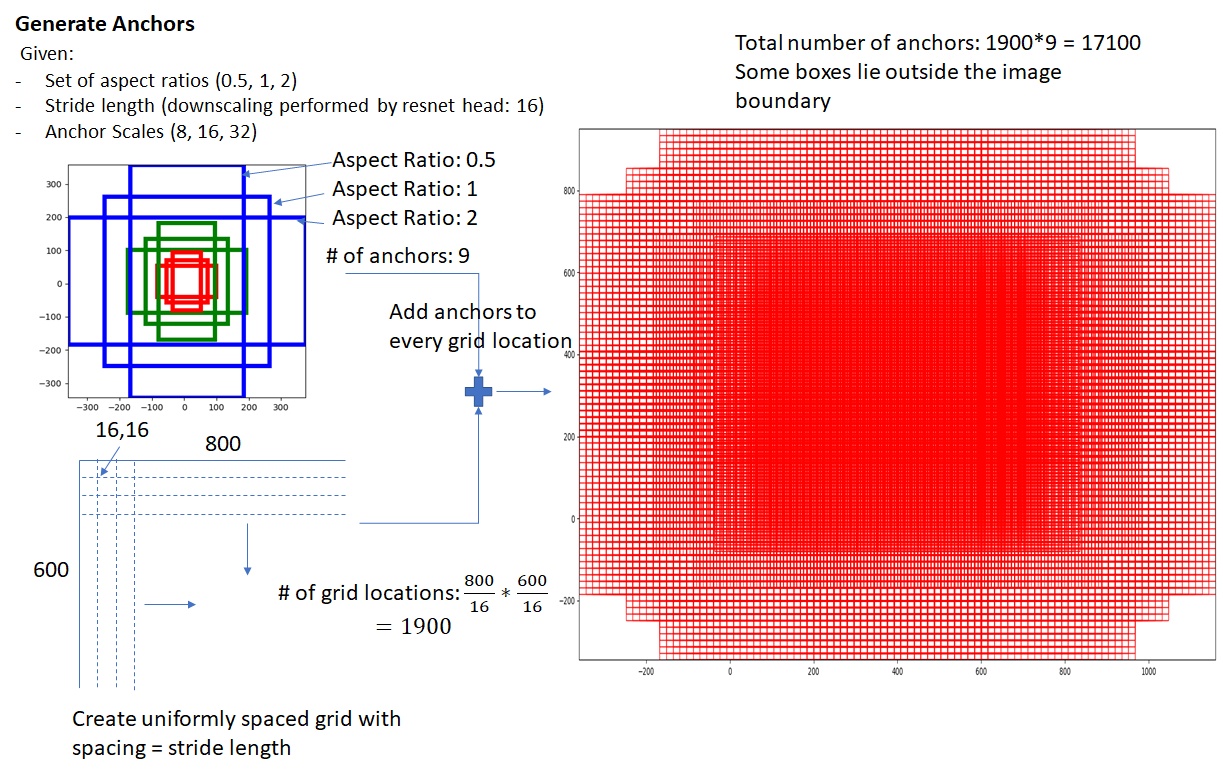
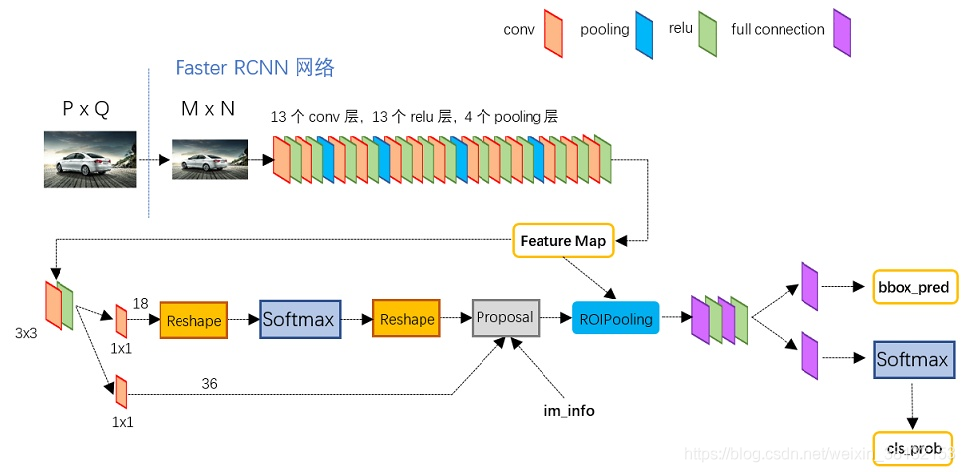
在生成好anchors后,特征图先进行一个3x3卷积(这个并不重要),然后分成两条路线,上路是区域是否包含目标的分类任务,下路是anchor相较于ground truth box(GT)的回归任务。
上路通过1x1卷积,得到深度为18的特征,18表示对于每个点有9个anchor和2种分类(positive和negative)。下路则通过1x1卷积,得到深度为36的特征,36表示9个anchor和4个偏移操作,一个box可以用中心点的xy坐标以及box的高和宽这4个数字表示,而anchor box与GT的偏移就可以用xy坐标的移动以及高宽的缩放这4个数字来表示,所以是4个偏移操作。
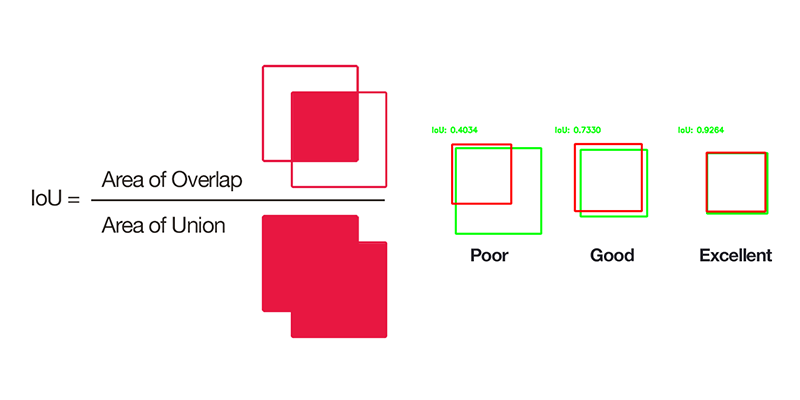
然而,实际上我们还要把anchor与GT对应起来,我们会通过IoU来区分,如下图,IoU是交集面积除以并集面积,衡量两个box重合程度。当anchor与任何GT的时标记为positive;或者anchor与某个GT满足且是这个GT的最大的,则也标记为positive;而当anchor与所有GT的时标记为negative;其他情况标记为border(边界)。
在计算loss时,,前者分类算交叉熵,后者算smooth后的L1距离。
Stage2:目标分类
在这个阶段,模型将对之前提出的proposal region进行分类和进一步的回归。
由于之前得到的region是不同长宽的,需要将其处理为固定的格式,比如Faster RCNN中的RoI Pooling,如下面这个动图,假如黑框是得到的region特征图,RoI Pooling先将这个区域取出,然后分成个小区域,图中是,这里并不需要每个区域完全相同大小,因为下一步就会对每个区域进行空间上的max pooling,最终得到的region特征向量,在Faster-RCNN中这个值是。
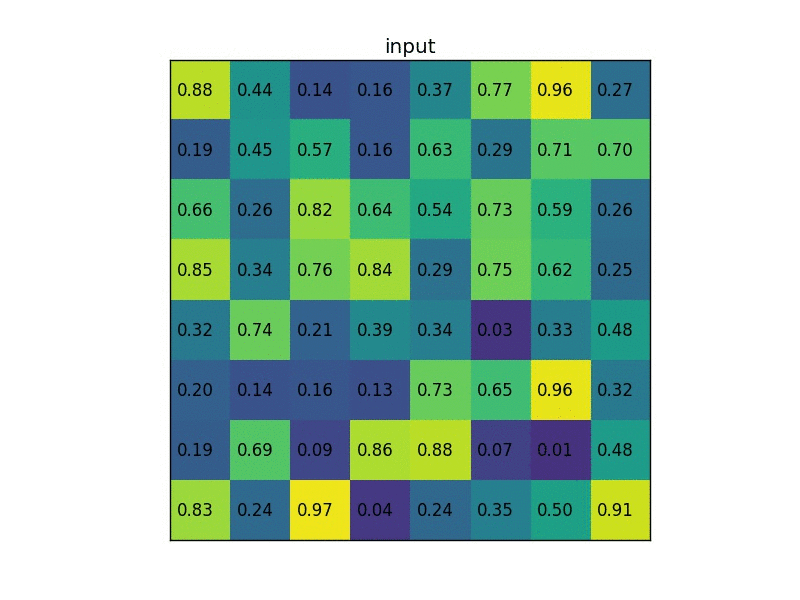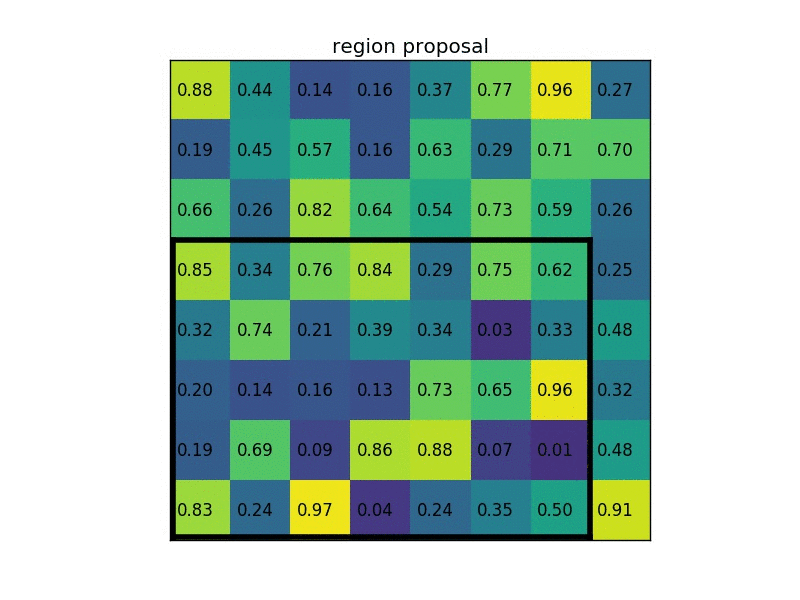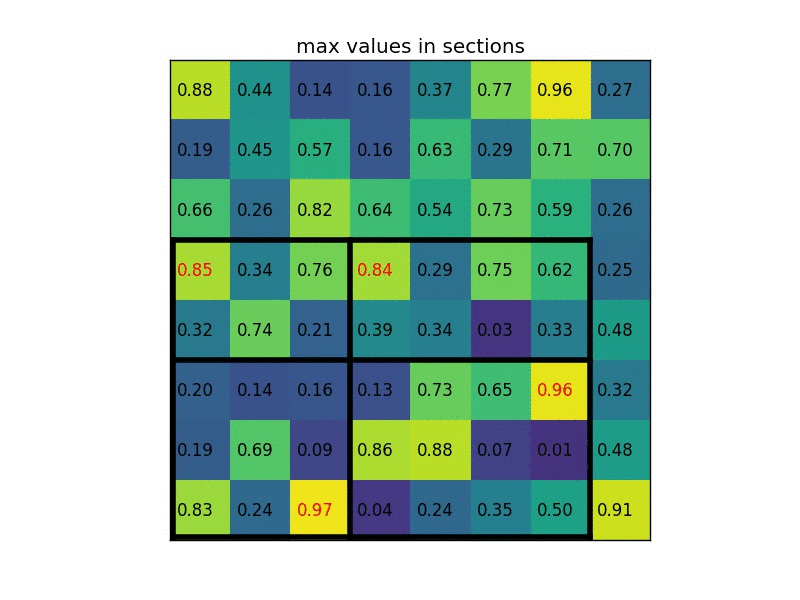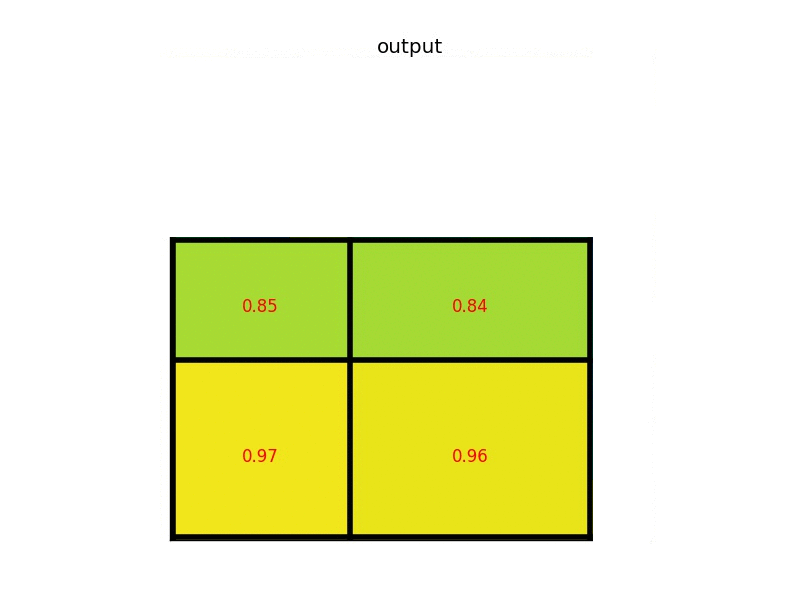
之后就经过全连接层进行降维(25088维度太高),然后通过两个不同的全连预测两个目标:①接上分类器进行分类;②接上回归网络对每一个类别预测其box的4个坐标。也就是说,一个proposal region可能生成多个预测出来的box?
Detic模型
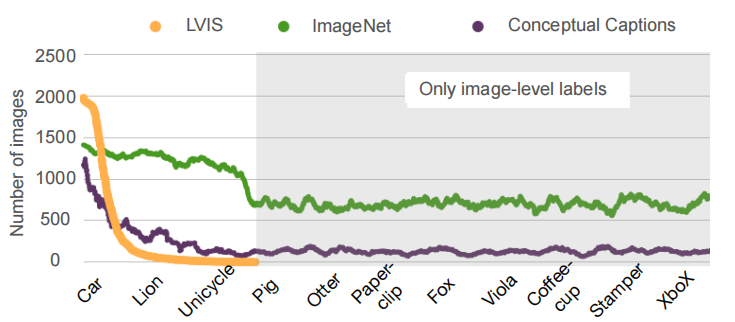
Detic模型将object-level的标注数据与image-level的标记数据一同进行训练。如下图,object-level标注的数据集(LVIS)包含的类别更少,每种类别的图片数量也更少,一些类(比如Pig、Coffee-cup)只有image-level的数据集(ImageNet、Conceptual Captions)包含。所以要检测更多的类别,需要好好利用image-level的标签。
在利用image-level的数据时,由于没有标注的box,作者想了三个方法,第一是直接使用整张图片作为box,第二是使用proposal region中object score最高的作为box,第三是用一个能包括所有proposal region的box作为box。之后结果显示第三个方法效果最好。作者分析,第一种方法相较于第三种方法会有更多的噪声,而第二种方法如下图在训练初期不能很好地包括要检测的物体,只有第三种方法在训练过程中比较稳定,且能包括目标,提供正确的监督信号(虽然也可能包括一些噪声)。

这个模型训练的最终loss如下图,当图像是有标记数据时,计算常规的loss,当是image-level的数据时,计算那个大区域的分类的loss。
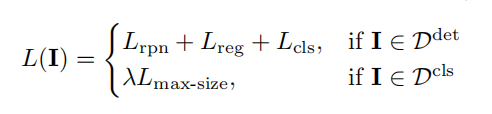
为了实现Open-vocabulary,作者将分类的目标设置为一个embedding,所有标签则通过CLIP prompt被编码成对应的embedding,要得到预测结果,即将模型得到的embedding与所有标签对应的CLIP embedding计算相似度分数,然后softmax得到每个标签的概率,再计算CE loss。
Open-vocabulary大概就是指识别对象的字典是开放的,可以随时往里面加新的目标。
这个方法并不是Detic原创,而是Open-vocabulary object detection via vision and language knowledge distillation的方法:
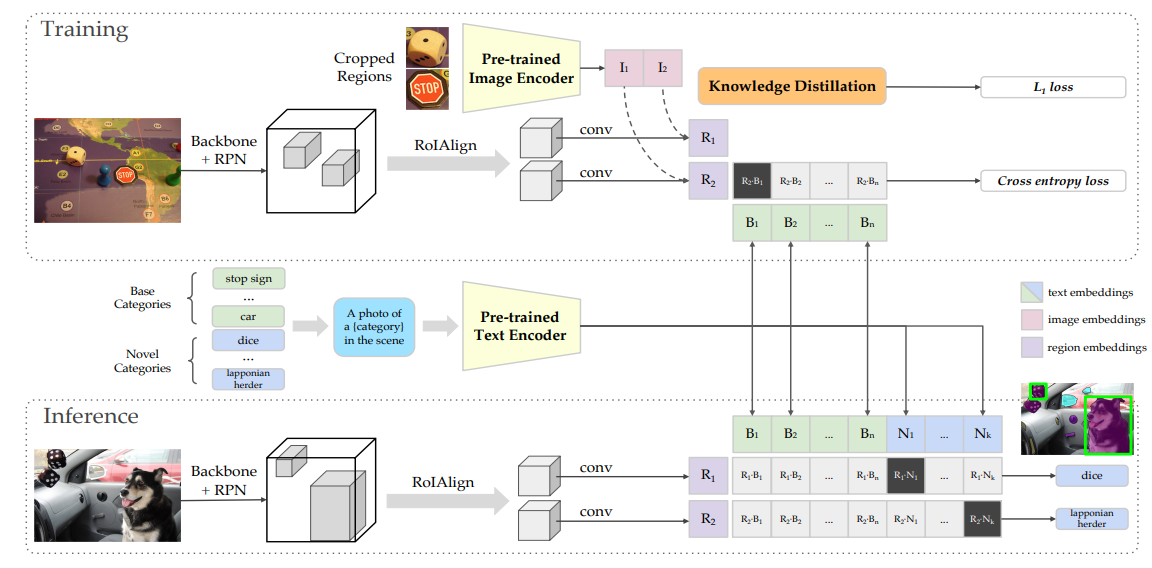
这个方法的好处就是,在预测的时候,不需要重新训练就能预测新的类别,如下图,inference的时候,novel categories也能通过CLIP Text Encoder得到对应的embedding,也可以与模型的embedding算相似度。
但Detic的作者在文章中说道,直接这么用的效果并不好,而通过他们的方法扩充了训练时的类别,效果会更好。
一些些实验结果
实验结果太多了,由于不是这个方向的就没有细看,并且文章给出了超级多的补充材料,有兴趣可以翻论文。

识别效果非常好,识别出了绿色的novel classes。
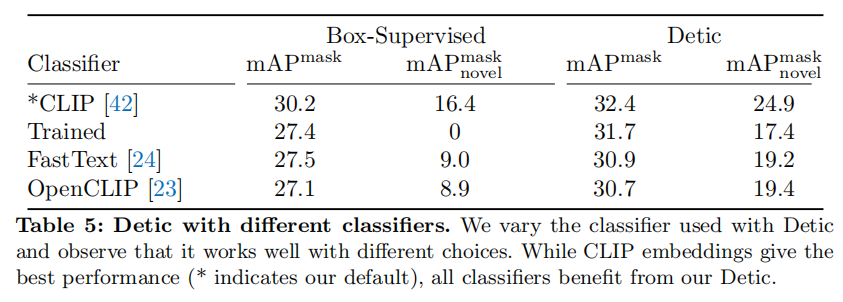
果然CLIP很强啊,用CLIP的Embedding效果最好。
总结
Facebook开发的Detic效果真的很惊艳,而且提供了很直观好用的Demo,代码上看上去很容易复现,检测出的类别也非常多,应该能很方便用在其他的领域。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!