知识图谱(Knowledge Graph)与计算机视觉(Computer Vision)结合初见笔记
本文最后更新于:2022年11月17日 中午
知识图谱(Knowledge Graph)与计算机视觉(Computer Vision)结合初见笔记
知识图谱 -> 细粒度图像分类
IJCAI2018 通过数据集的标注构建知识图谱,再使用GNN得到知识表征向量
IJCAI 2018: Knowledge-Embedded Representation Learning for Fine-Grained Image Recognition
论文链接:Knowledge-Embedded Representation Learning for Fine-Grained Image Recognition (arxiv.org)
代码链接:无
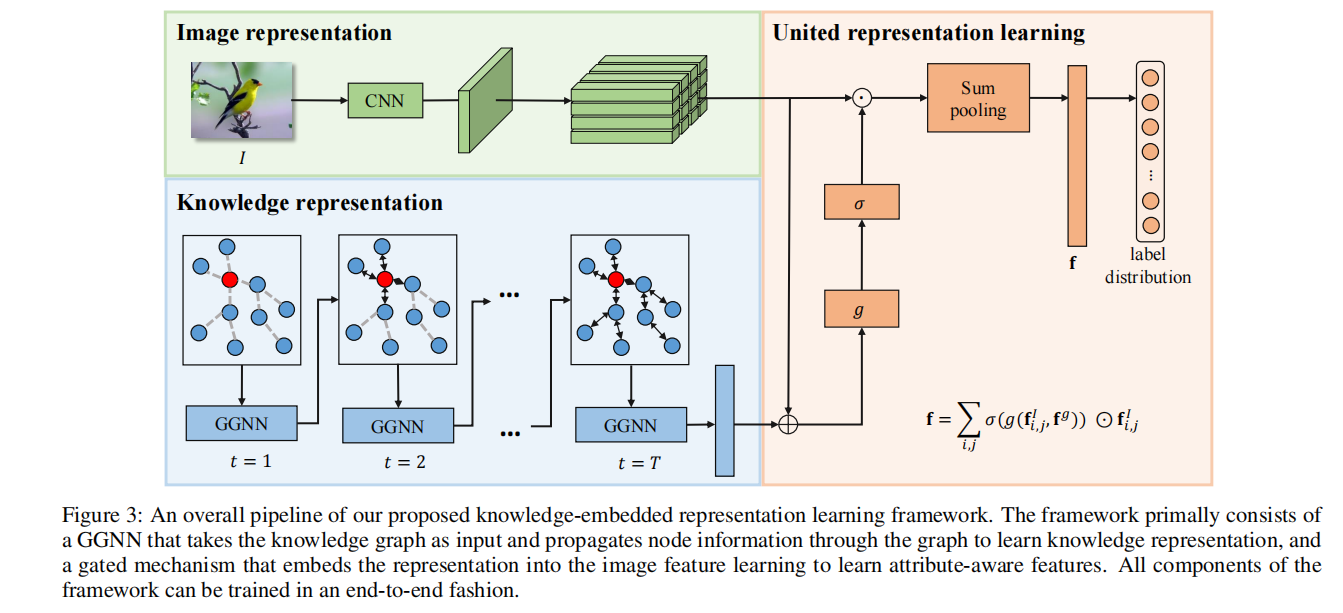
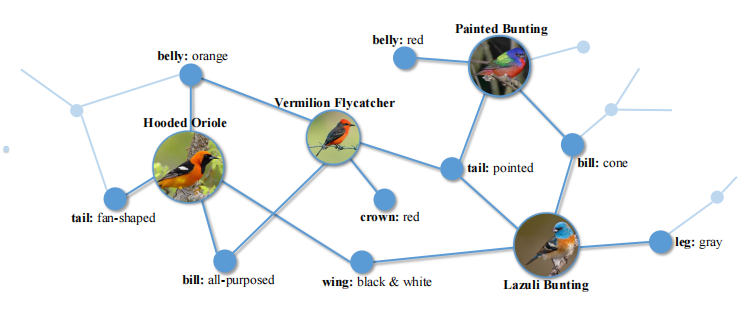
这篇论文将外部知识源进行嵌入表示的学习,然后用作细粒度的图像分类。构建的知识图谱如下图所示,点(node)表示视觉概念(visual concept),本文构建的有两种点,一种是要进行的分类类别,一种是属性;边(edge)表示关系(correlation),本文中两个类别点不会直接相连,而是类别点与属性点相连,表示某个类别具有该属性。
所以,完整的邻接矩阵是一个的矩阵,A是属性的数量,C是类别的数量。
如模型整体图所示,构建的知识图谱将送入GGNN进行学习,对于某个类别的节点,初始化为,对于某个属性的节点,初始化为。其中是通过另外一个预训练的CNN预测的图片属于这个类别的概率。
在经过GGNN学习之后,能得到所有节点的隐藏信息,之后和节点的初始值拼接之后送入一个全连,再进行拼接得到最终的知识表示向量。
如模型整体图所示,绿色部分的CNN提取最后一层的特征图,不进行global pooling,而是通过下面这个公式,在知识的引导下分配权重:
就是特征图某个位置的c维度的特征向量和知识向量拼接后全连,得到c方向上的权重,然后和特征信息相乘,再相加。要注意这里不像注意力,一个通道上的权重和不是100%,只是用了sigmoid压缩到0~1范围内。
最后通过一个全连来得到分类结果。
下面这个可视化展示了分配过权重的特征图,特征图通过直接求和来消除通道维度。
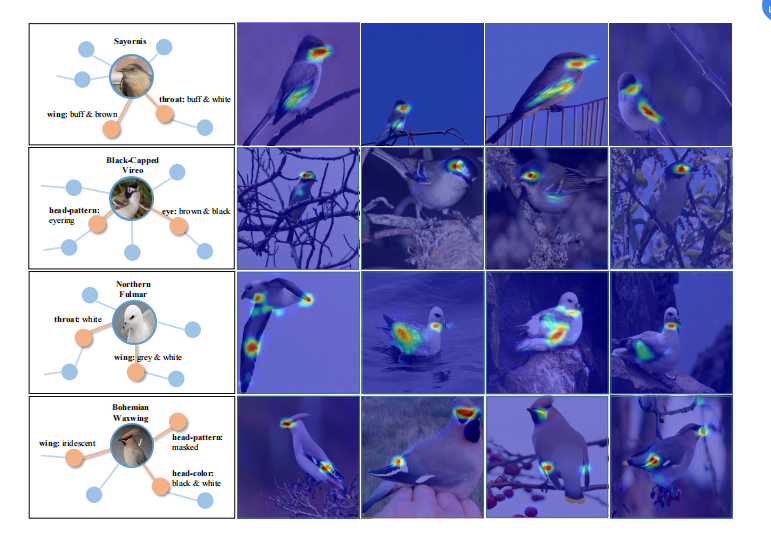
**总结:**知识图谱需要自己构建,对数据集的要求较高,文章用的数据集包含了每种类别和对应的属性标注。文章用的数据集有200种鸟和312种属性,所以图是512x512的还比较小,要是图谱大一点就很难应用了。
知识图谱 -> 图像描述生成(Image Captioning)
WACV2019 预训练目标检测出object,再从ConceptNet中找到相似的terms,用RNN提取特征使用
WACV 2019: Improving Image Captioning by Leveraging Knowledge Graphs
论文链接:1901.08942.pdf (arxiv.org)
代码链接:无
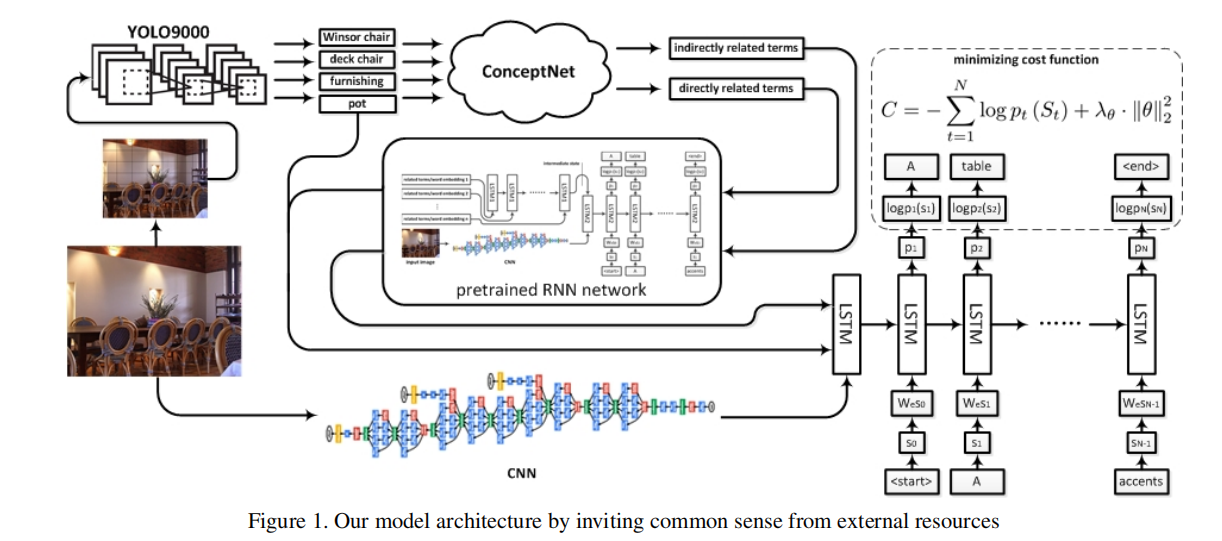
模型整体图有点丑……而且莫名低清。
论文提出了CNet-NIC(ConceptNet-Enhanced Neural Image Captioning),通过外部的大型知识源ConceptNet来辅助生成任务。
ConceptNet 常识知识库(knowledge base, KB) - TheTai - 博客园 (cnblogs.com)
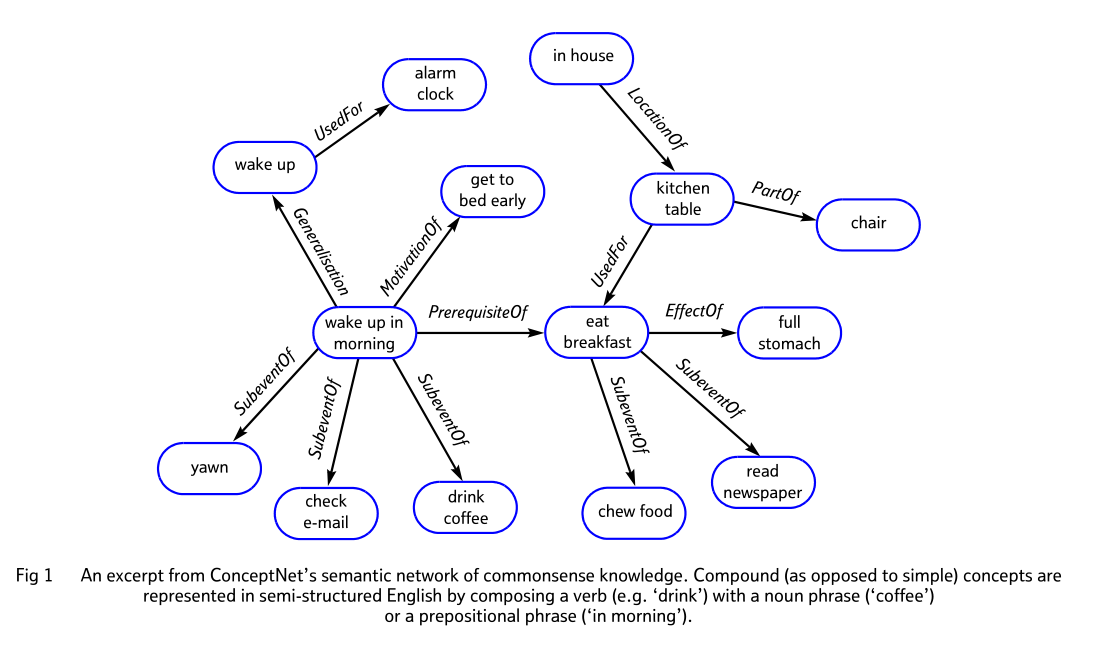
ConceptNet是一个免费提供的语义网络/知识图谱。如下图,其侧重与词与词(短语)之间的联系
首先作者用了一种叫做retro-fitting的方式来通过ConceptNet优化word embedding,这个是离线进行的,利用ConceptNet上单词之间关系来finetune。(应该吧,这论文莫名其妙摆了一段在3.3,很迷惑)
Retrofitting Word Vectors to Semantic Lexicons | by Ayush Kumar | Medium
Better Semantic Vectors - Retrofitting Word Vectors to Semantic Lexicons - Paper Overview - YouTube
mfaruqui/retrofitting: Retrofitting Word Vectors to Semantic Lexicons (github.com)
retro-fitting的思想就是优化下面这个函数,新的embedding要和原来的embedding近似,同时还要与语义图(如ConceptNet)中的相邻单词的embedding近似。
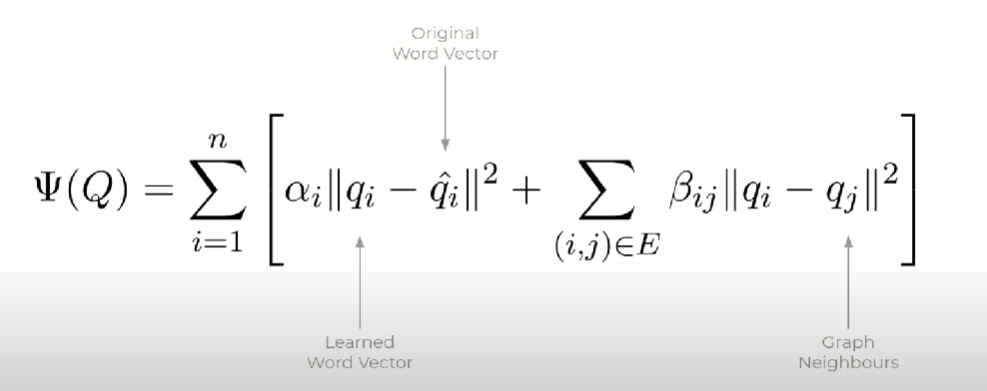
之后3.5也很迷惑,说了一种“一个目标单词w与一堆单词W间计算相似度”的方法。
3.6介绍了整体的方法,用YOLO9000检测出来的所有目标O,其中每个目标是o,通过ConceptNet可以找到与每个o相连的邻居,这些构成,和O一起组成直接与输入图像X相关的terms。(以下是一些推测,因为论文看不懂)YOLO可能检测出多个相同的目标,这会给不同的o不同的权重,对于一个ConceptNet中的单词,其能通过加权算距离得出其与整个图像之间的距离,依此,可以得到所有与ConceptNet中与图像(而不是目标)相关的terms:(具体怎么找没说啊,遍历ConceptNet吗???找几个??)
得到terms之后就很简单了,用RNN分别encode这两组terms,然后得到的输出与图像CNN的特征进行拼接,最后用一个LSTM预测输出。
JCR2区 简单明了使用ConceptNet,从中搜到临近词来调整输出概率
JCR2区被引11次:Boost image captioning with knowledge reasoning
论文链接:Boost image captioning with knowledge reasoning | SpringerLink
代码链接:无
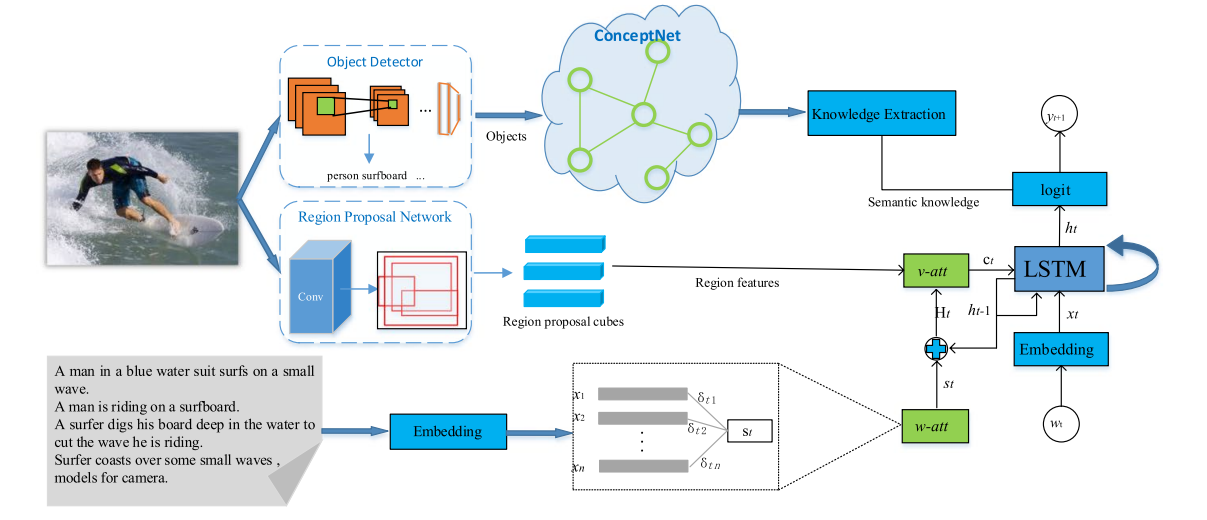
这里只关心论文如何使用ConceptNet的,而实际上也很简单:如上图,作者使用目标检测器(Faster R-CNN)检测出object的标签,然后将标签输入ConceptNet找到与之相联系的term,这些terms组中一个semantic knowledge corpus ,并且ConceptNet还带有不同term的权重。作者在预测logit阶段使用这些知识,即将ConceptNet得到的权重通过一个超参数加到logit上,调整其分布概率。
知识图谱 -> Scene Graph Generation
CVPR2019 目标检测+ConceptNet构建事实语句,再通过GRU+记忆网络获得表征向量
CVPR 2019:Scene Graph Generation with External Knowledge and Image Reconstruction
- 论文链接:CVPR 2019 Open Access Repository (thecvf.com)
- 开源代码:arxrean/SGG_Ex_RC: Code for Scene Graph Generation with External Knowledge and Image Reconstruction (github.com)(unofficial,star不多)
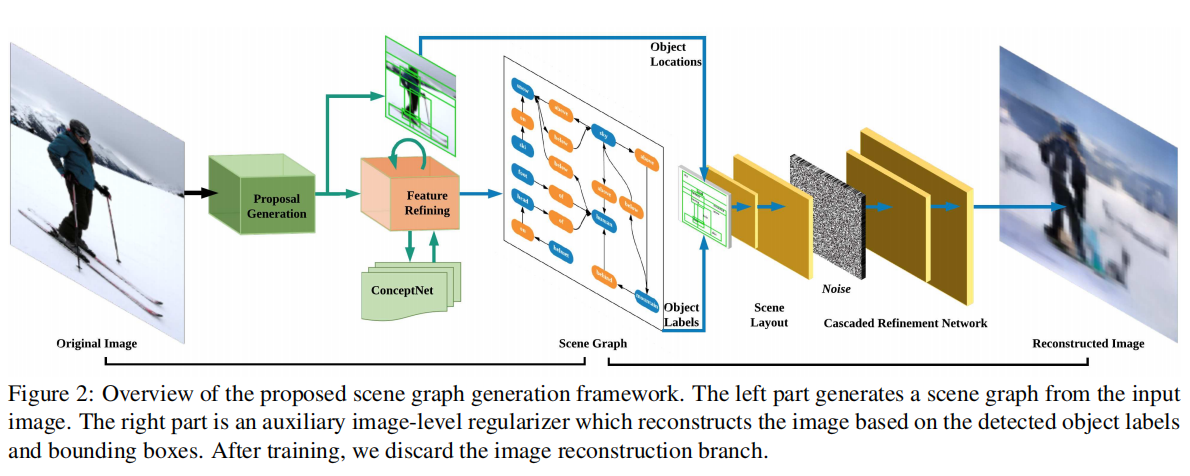
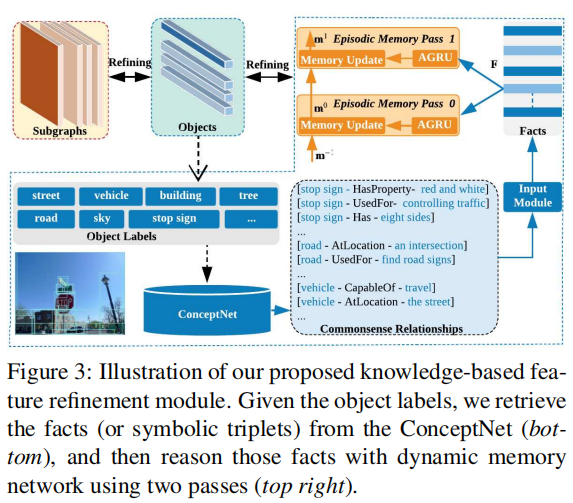
论文用RPN生成Proposal,然后Proposal之间构建Subgraph,Subgraph会包含一个score,值是其连接的Proposal的score的乘积,Subgraph之后通非最大化抑制来减少重复数量。然后论文Follow了另一篇论文得到了图的特征和目标的特征,并再根据Follow的这篇论文强化了特征得到。
之后就利用ConceptNet来继续强化特征,论文从中分类出目标检测的标签,然后根据来从ConceptNet中检索相关的Commonsense Relationships,这就是一个类似句子的东西,之后就通过word embedding可以用RNN进行处理了。作者这里又Follow了记忆网络,可以看记忆网络之Dynamic Memory Networks - 知乎 (zhihu.com),之后根据记忆网络得出来的记忆增强为。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!