SmallCap:Lightweight Image Captioning Prompted with Retrieval Augmentation 论文笔记
本文最后更新于:2022年10月28日 下午
SmallCap:Lightweight Image Captioning Prompted with Retrieval Augmentation 论文笔记
本文是22年9月底的一篇新论文,提出了一个轻量的Image Captioning模型,其包括1.8M/3.6M/7M 三个拥有不同可训练参数版本的小模型,相较于其他轻量模型,SmallCap更轻且效果和其它有可比性甚至超越。其通过Image-text检索,从数据库中检索出与图片相近的句子,然后通过Prompt的方式输入一个语言模型来得到最终的Caption。
- 论文链接:SmallCap: Lightweight Image Captioning Prompted with Retrieval Augmentation (arxiv.org)
- 开源代码:RitaRamo/smallcap
基本方法
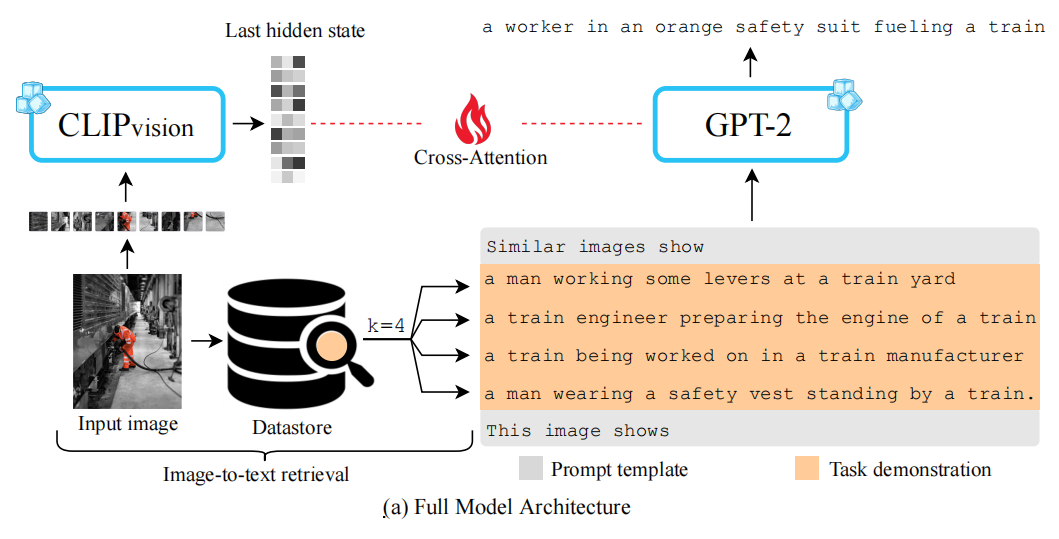
如图,模型的图像编码器使用CLIP的视觉部分,语言解码器采用GPT-2。输入的图像通过CLIP得到特征之后,通过在GPT-2上添加Cross-Attention来将图像信息参与到解码过程中,这里的参数就是模型唯一需要学习的参数,其余参数均不参与训练。Cross-Attention就是Transformer里面那个,这一部分的隐藏维度可以是与GPT-2不一样的,作者将GPT-2的768除以了4/8/16从而得到了三个不同大小的模型。
同时,图像和文本分别也通过CLIP模型提取各自的Embedding,然后针对输入的图像检索出前k个相近的文本,当做GPT-2的输入的一部分。要注意的是,这里的用来检索的CLIP模型实际上和上一段用来提取图像特征的模型使用的是不同参数的CLIP。提取图像特征使用CLIP-ViT-B/32这个更大的模型,做检索时则使用的是CLIP-ResNet50x64这个模型。
作者认为这个模型在更换Datastore之后可以不用训练就可适应新域数据:作者的基本思路是在COCO上训练好一个模型,然后要用在其他数据集上时,只需更换Datastore来检索出不同的Task demonstration,并不用进行训练或者finetune。
GPT-2输入的模版如上图,通过告诉模型Similar images的文本,来让其生成This image shows之后的结果。预测结果使用beam size为3的beam search来优化输出,image-text检索上使用FAISS进行更高效率的检索。
实验分析
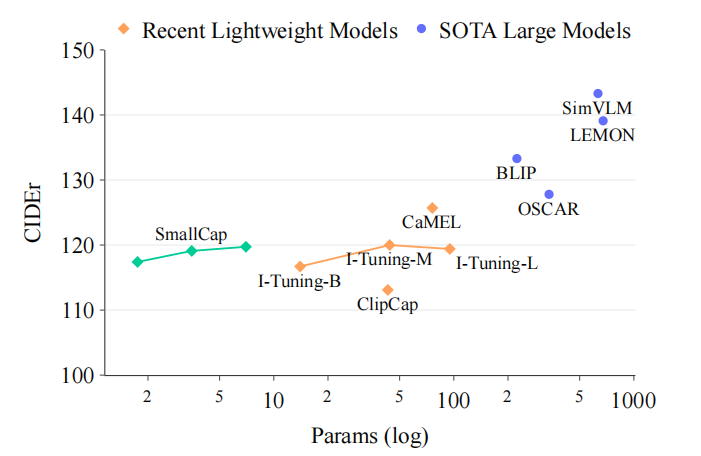
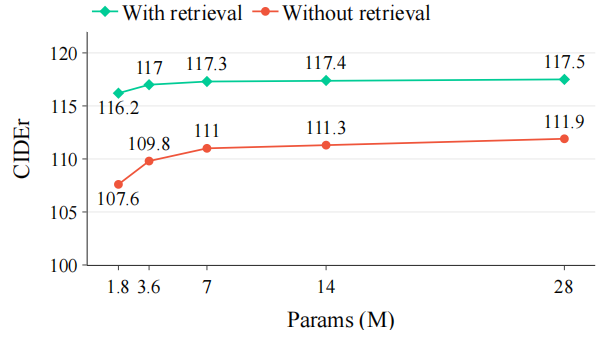
如左边的图所示,模型虽然效果不是特别出众,但是参数量上大大减少。右边的图则说明Retrieval的作用显著,增加了CIDEr上6个点左右。
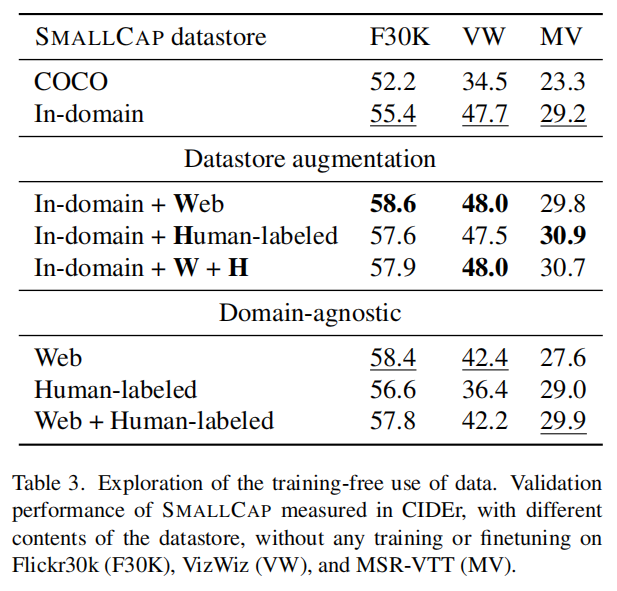
上图是先在COCO数据集上训练,然后在不同数据集下只更换datastore的效果,上面数据集使用了三种,其中MSR-VTT是Video Captioning的数据集,作者简单的平均取4帧,然后空间上拼接成一张图片进行Image Captioning。
通过第2、3行(包括表头)可以发现datastore更贴近数据集会带来更好的效果。之后则尝试加入语料库,Web指的是来自互联网的大规模的语料,但是质量更差,Human-labeled指的是小规模的高质量的语料。通过第5-7行可以发现,在In-domain的基础上增加语料库基本都提升了效果,但是VizWiz数据集上提升不多,作者分析是这个数据集的文本分布比较特殊。然而,同时使用W和H并不会带来更多的提升。
然而In-domain的标注可能不一定存在,所以作者还研究了Domain-agnostic的情况,发现图片数据集能通过更大规模更多样的Web语料上得到更多的提升,而MSR-VTT更倾向于Human-labeled的高质量。
对其他两个数据集不太了解,但是MSR-VTT上和别的比效果并不是很好
下面是一些定性的分析:

总结
这篇文章的核心贡献是使用Retrieval+GPT prompt的方法实现极少可训练参数的Image Captioning。然而,既然可训练参数已经很少了,那在新的数据集上时,finetune应该也不是什么难事,但作者却把重点放在了新数据集也不用训练这一块,我认为有些矛盾。若不是那么强调训练参数,也许可以将GPT-2一块进行训练,100多M的参数应该也还是能接受的。另外,GPT-2的效果相较于GPT-3来说并不是特别好,采用prompt的方式提升可能无法非常有效地利用检索出的文本(毕竟吹的最多是GPT-3,但是它不开源)。
Extra:通过添加Cross-attention连接Encoder和GPT-2
这个并不是这篇文章的原创,但是这个方法也比较有趣,在网上搜到了一个很好的教程,通过Hugging Face的API能轻松构建这样的模型:Generating captions with ViT and GPT2 using 🤗 Transformers | DeepSchool (sachinruk.github.io)
官方文档🤗:Encoder Decoder Models (huggingface.co)
官方示例:
1 | |
Extra:Faiss用来检索相似向量
Faiss是一个用C++开发,提供Python接口的用来进行向量检索的高性能库。它既提供完全准确的检索,也提供模糊的检索。
官方文档:Getting started · facebookresearch/faiss Wiki (github.com)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!