GIT A Generative Image-to-text Transformer for Vision and Language 论文笔记
本文最后更新于:2022年10月12日 下午
GIT A Generative Image-to-text Transformer for Vision and Language 论文笔记
Arxiv上Preprint的一篇微软的论文,结构比较简单(或者叫通俗),用Image Encoder先编码图像,然后图像和文本在一个类BERT的模型中训练,没有对视频做特别的优化,但在各个任务上都SOTA。
- 论文链接:GIT: A Generative Image-to-text Transformer for Vision and Language (arxiv.org)
- 开源代码:microsoft/GenerativeImage2Text: GIT: A Generative Image-to-text Transformer for Vision and Language (github.com)
(没啥好讲的)模型架构
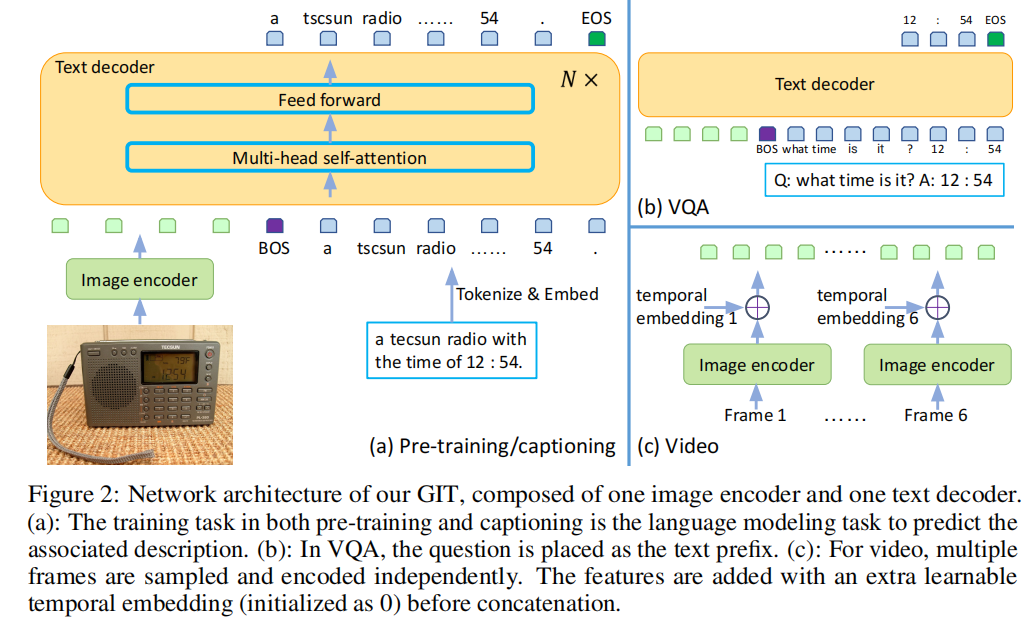
GIT进行五种任务:Image Captioning、Image QA、Video Captioning、Video QA、Text Recognition、Image Classification。
图像或者图像序列将会通过Image Encoder编码为多个token,对于序列还会增加额外的可学习的temporal embedding。同时文本每个word也tokenize&embed成word token。之后,visual token和word token在一个统一的Text Decoder中解码为文本(别的地方一般称之为Multimodal Encoder)。对于Captioning、QA和Text Recognition都比较直观,这里还会通过输出目标类别对应的文字的方式来进行Image Classification任务。
GIT的Image Encoder来源于微软之前的Florence模型(也是一个大规模统一预训练模型),是一个叫做CoSwin的模型,这是一个通过CvT论文中方法修改过的Swin Transformer(CvT和Swin也都是微软家的),其通过将Swin中的patch embedding和patch merging替换为卷积来将CNN与Transformer结合(如下图)。
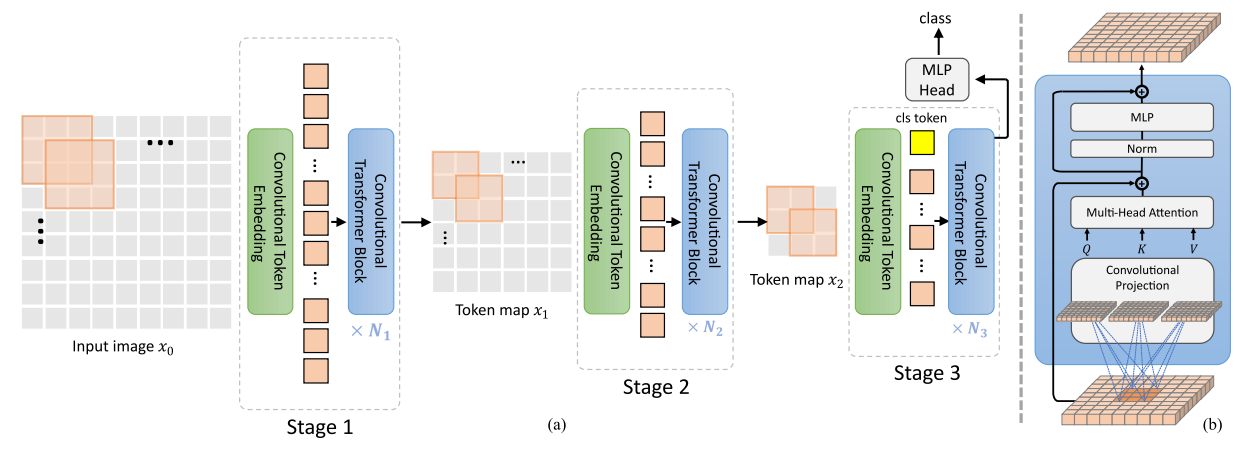
提到的论文:
这个架构与SwinBERT有些类似(可以参考我另一篇博客,同样也是微软家的),他们同样用Transformer架构的视觉编码器得到token然后送进类BERT的架构中进行文本生成任务,也同样随机初始化后面这个类BERT的架构(这个是有人做过实验说明随机初始化更好的)。如下图,在进行生成任务时,注意力mask也和SwinBERT类似,视觉的token只能对视觉token施加注意力,word token则能对visual token和之前生成的word施加注意力。
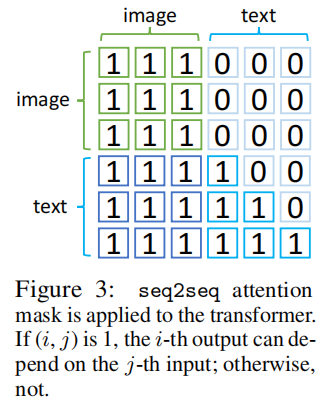
与SwinBERT不同的是,GIT使用Language modeling(LM)进行训练,而不是Masked Language modeling(MLM)。原因是因为LM训练得更快,作者分析说MLM一次只能训练一部分token的生成,而LM能训练所有token。
GIT还有一点与SwinBERT不同,就是后面接的多模态的Transformer,居然只是6层的Transformer网络,是SwinBERT的一半。
GIT标配700M参数量,还有更小的和,以及更大的GIT2。

Video Captioning实验分析
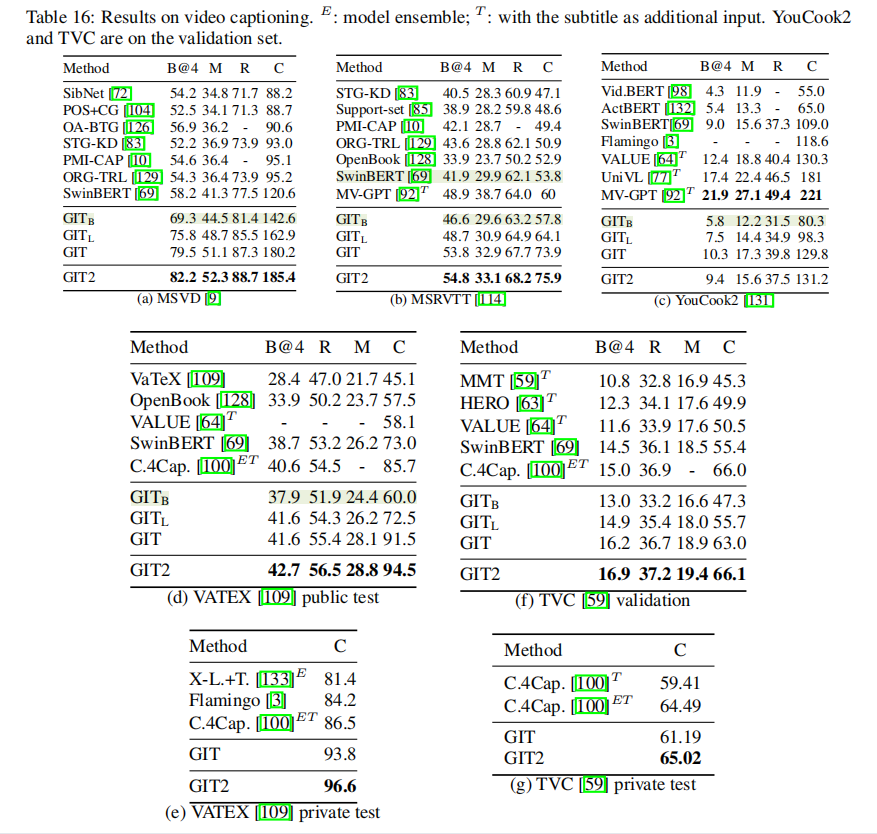
由于我对Video Captioning更感兴趣,所以就分析这方面的实验。大表如下,MSVD数据集上感觉指标已经到头了,180.2的CIDEr。而在更大的MSRVTT数据集和VATEX数据集上也获得了非常大的提升。然而,YouCook2、TVC上结果没有那么明显。
其只有129M参数量的效果也算十分不错,对于缺少卡的炼丹师来说也许能够进行更大范围的应用。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!