End-to-end Generative Pretraining for Multimodal Video Captioning 论文笔记
本文最后更新于:2022年10月12日 下午
End-to-end Generative Pretraining for Multimodal Video Captioning 论文笔记
本文是一篇来自Google的CVPR2022论文, 本文提出了一个大规模多模态预训练框架,与其他基于Masked Language Modeling (MLM)、Masked Frame Modeling (MFM)、Video-Text Matching (VTM) 和 segment ordering的方法不同,其采用生成式任务进行预训练,这样能够更好地适配Video Captioning这样的生成式任务。具体来说本文提出的训练任务是通过视频中ASR识别的上一句来预测下一句(或相反),实验表明这种方式在多个数据集上SOTA。
- 论文链接:CVPR 2022 Open Access Repository (thecvf.com)
- 代码链接:未开源
模型框架
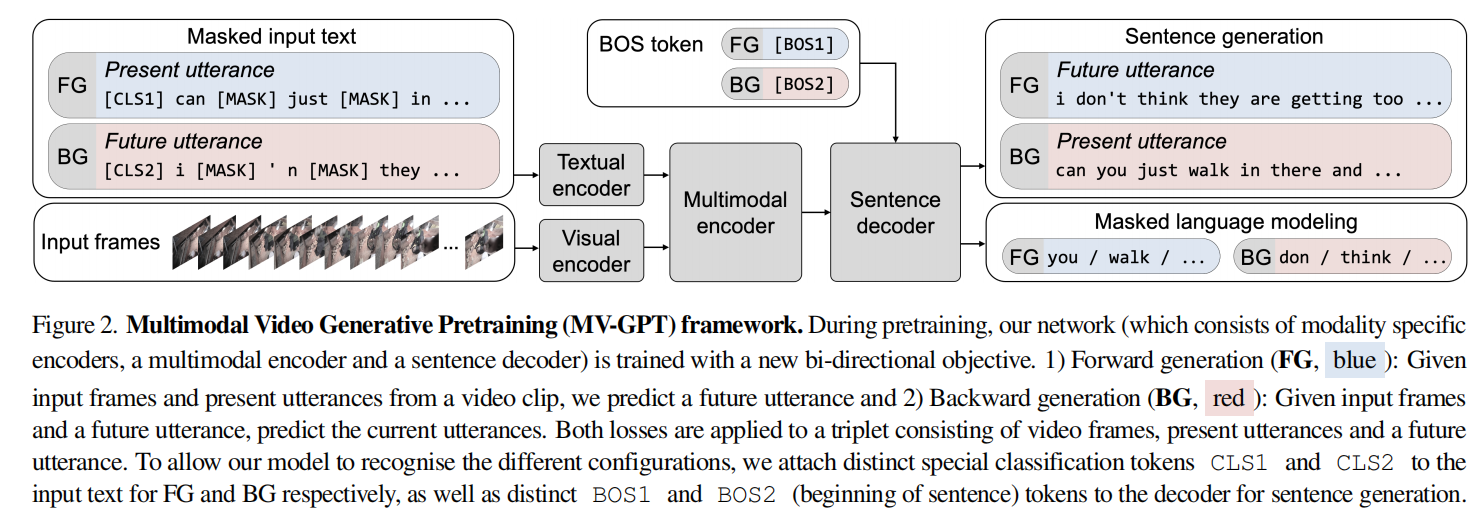
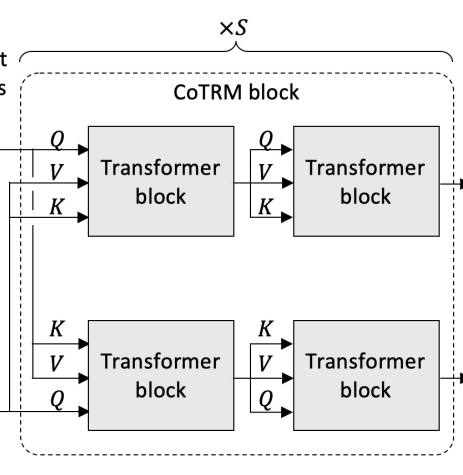
如图,模型由一个Textual Encoder、一个Visual Encoder、一个多模态Encoder和一个Sentence Decoder组成。其中TE是BERT-base、VE是ViViT-base、SD是GPT2,都加载了对应的预训练参数。而多模态编码器则是2层CoTRM(如下图,来源于论文Look Before you Speak: Visually Contextualized Utterances)。
预训练阶段执行的任务比较直观,输入对应的视频序列以及第一个句子,然后Auto-regressive地生成第二个句子,其中第一个句子部分单词还可能被Mask掉从而进行MLM。因为模型的目的不是预测未来的句子而是生成与视频相关的文本,所以作者还添加了反向的训练,即输入视频和第二个句子,反过来预测第一个句子。
细节上,第一个句子都由[CLS1]开头,要预测第二个句子时由[BOS1]开头,从第二个句子预测第一个时则相反。之前说的是Pretrain阶段,而Finetune阶段时,视频对应的ASR结果由[CLS1]开头,但预测时由[BOS2]开头。
使用这种预训练任务,模型就能够进行大规模的无监督的预训练。
训练方式与数据集
作者使用了HowTo100M作为预训练的数据集,其ASR数据来源于YouTube的API,作者总共提取到了53M项数据。之后作者在YouCook2、ViTT、MSRVTT、ActivityNet-Captions这四个数据集上进行Captioning的实验。
实验结果
下面是在4个数据集上的比较,都SOTA。看MSR-VTT的表,METEOR指标能达到38.66真的是非常高了,并且实际来说,HowTo100M都是一些流程视频,更接近YouCook这种做饭指导类数据集,而MSRVTT则是普遍的视频数据集,虽然在分布上有gap,但MV-GPT仍然SOTA了。
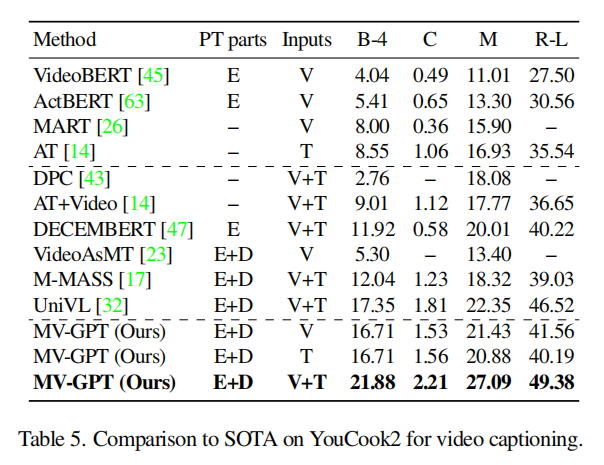
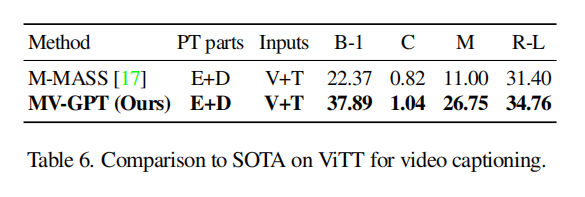
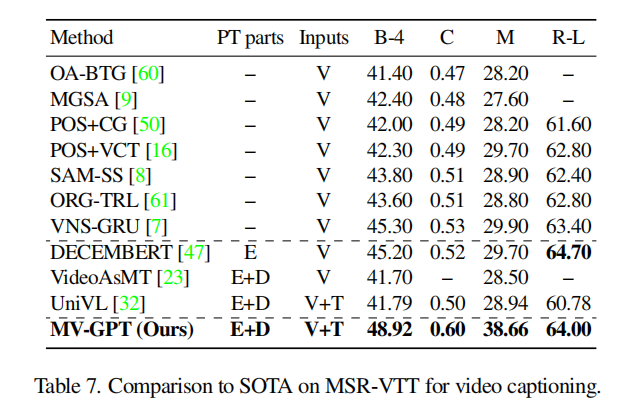
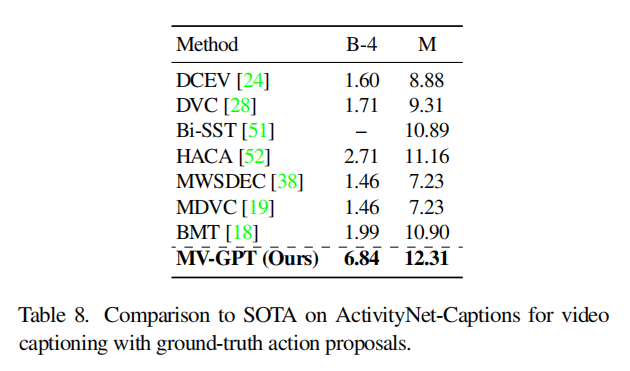
在其他任务上也都有一定的结果,我的研究重点不在那边就略过了,细节可以看原文。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!