Pointer Networks论文笔记
本文最后更新于:2022年10月27日 下午
Pointer Networks论文笔记
NIPS 2015的论文Pointer Networks (neurips.cc)
这篇论文主要提出了一个针对Seq2Seq结构改进的网络——Ptr-Net:其通过类似Seq2Seq的形式预测出一个指向之前输入的指针,并将这个位置的输入作为下一步的输入。也就是说,Ptr-Net的输出完全来源于输入,是一个copy-paste的结构。
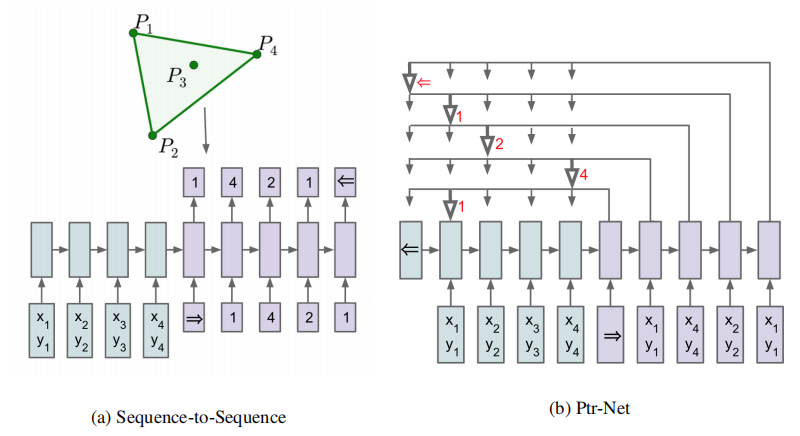
这里使用原文的模型图来解释说明,但不用原文的例子(感觉更不好理解)。如图(a),Seq2Seq模型在输入了一系列数据之后,再输入一个=>的特殊开始token,就开始进行预测。预测的结果一般是一个固定大小词汇表(比如10000)的概率分布,然后出来的向量经过softmax之后作为输出和下一步的输入。而如图(b),在输入=>之后,预测的并不是词汇表的概率分布,而是与输入的长度有关。假如如图输入长度是5(加上一个结束的token<=),那输出的结果就是这5个token的概率分布,所以说输出完全来源于输入。
这样处理的优点就是:
-
避免OOV问题
因为输出就是输入的重新组合,所以不会有OOV
-
可控
同样因为上面这个原因,不会出现乱七八糟的输出
-
对于摘要生成等任务很适应
同样还是因为上面这个原因,摘要生成就是从输入中找到概括性的词
细节
快速回顾一下LSTM网络,LSTM每一步(t)会得到hidden向量和cell向量,其中变化地更快而变化地更慢,一般都是用。
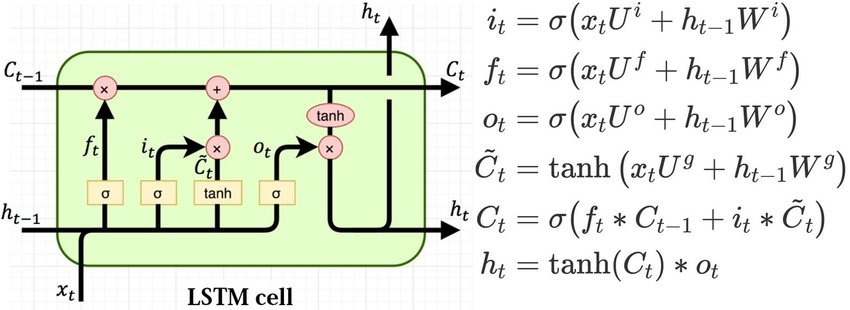
下面是计算pointer的细节:
- 令编码部分得到的隐藏向量为(长度为),令解码部分每一步的隐藏向量为;
- 计算当前步时,对n长的输入向量的,未softmax的注意力:;
- softmax后的注意力:,直接当做输出的概率分布。
应用1:结合Pointer Network来进行文本摘要任务
论文:Get To The Point: Summarization with Pointer-Generator Networks
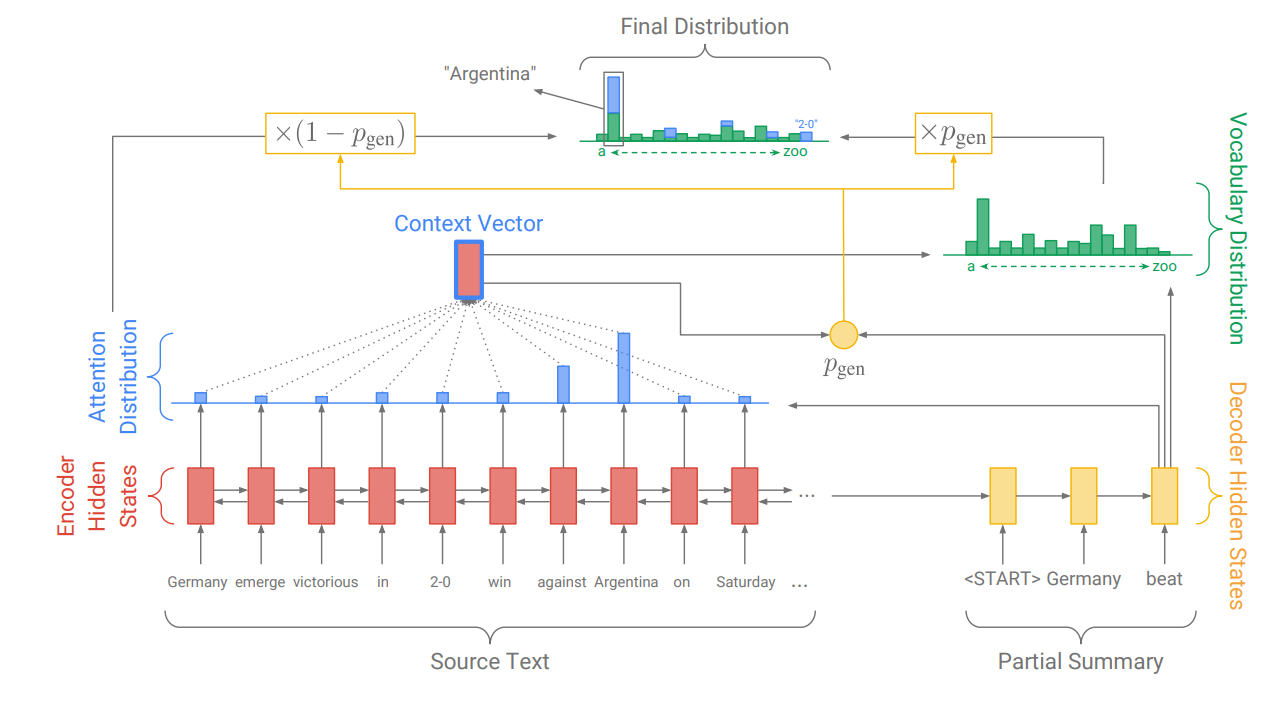
这篇文章结合了预测的概率分布和Pointer Network得出的概率分布来得到最终分布。
其中是这么生成的: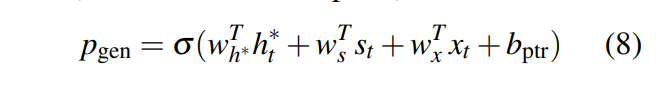
结合了context vector、decoder state和当前输入得到的概率,表示当前是要“生成”还是要“复制”。
结合代码和相关Issue Problem of the word embedding of OOV words of decoder inputs,输入文本(Source Text)中,已经在vocab中的,将会赋予对应的Embedding,不在vocab中的(即OOV词汇),将会赋予
[UNK]对应的Embedding。通过PtrNet将会得到输入文本中各个位置的概率,若这个位置对应的是在vocab中的词,那概率加权叠加在Decoder的输出概率上,若对应的是OOV词,则会将vocab拓展一个词并加上其概率。
参考文献:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!