Open-book Video Captioning with Retrieve-Copy-Generate Network论文笔记
本文最后更新于:2022年10月1日 晚上
Open-book Video Captioning with Retrieve-Copy-Generate Network论文笔记
这是一篇CVPR2021的论文,其提出了一种参考复制语料库中句子的open-book模块来进行Video Captioning任务。这种机制会先进行video-to-text的跨模态检索任务,从语料库中找到接近的top-N条文本,然后通过结合类似Point Network的复制机制来生成最终的语句(Point Network可见我另一篇博客)。

细节
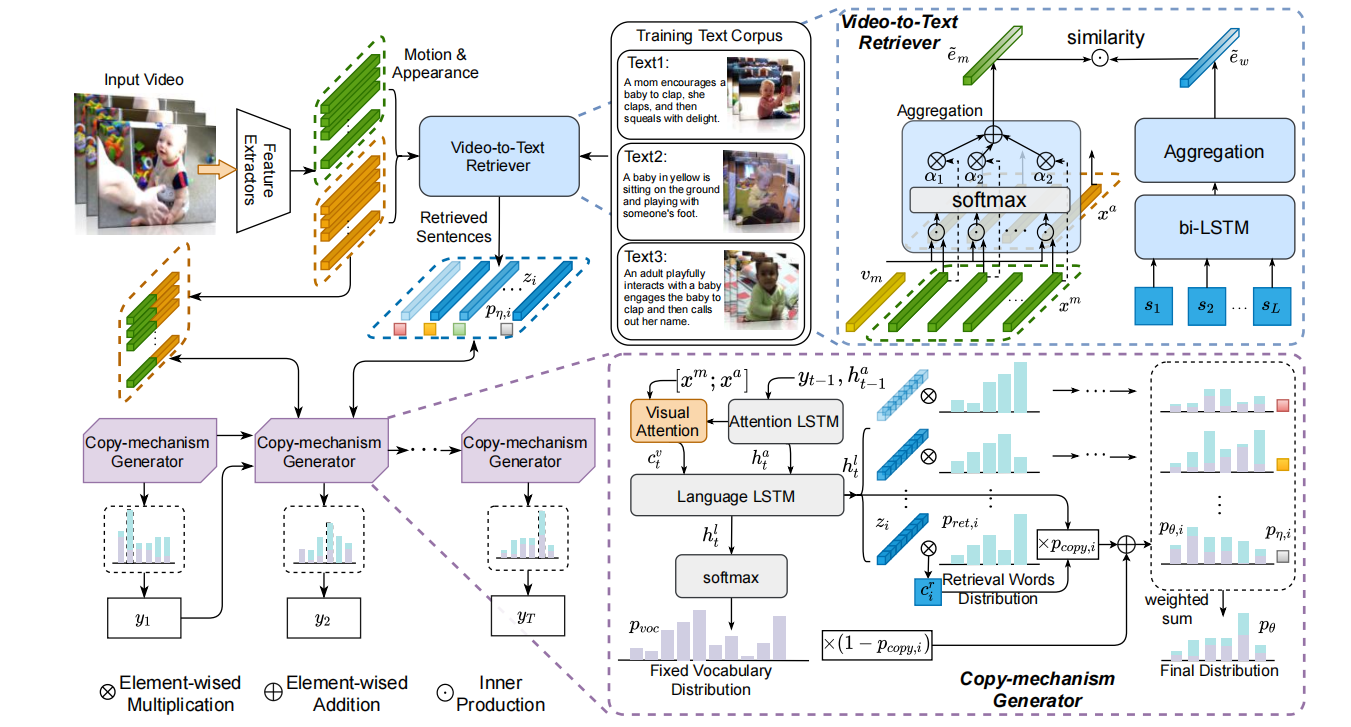
文章给出了看上去贼复杂的一张图(排版太紧凑了吧……),整体分成Video-to-Text Retriever和Copy-mechanism Generator两部分。
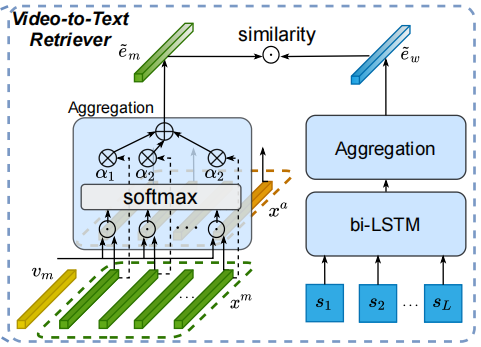
第一部分如上图所示,并没有用很复杂的机制:图左边是视觉端,右边是文本端。文本端使用双向LSTM得到包含时序信息的特征,然后通过得到每一步的注意力,然后加权求和得到不含时序信息的整体特征。视觉端先用预训练模型提取特征,然后也是用相同的手法得到整体特征,多个模态的话直接求平均。
之后两个向量求点积作为相似性分数。
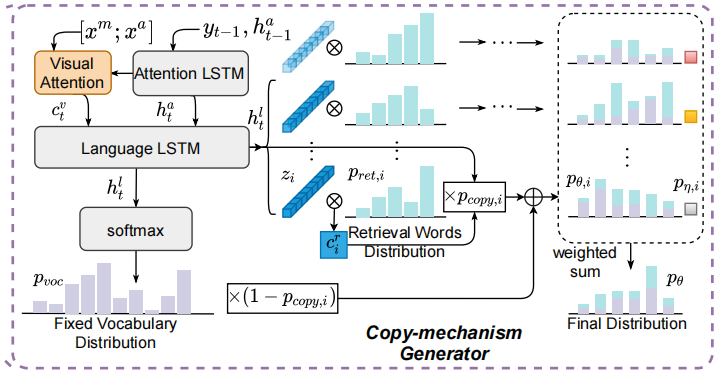
第二部分如上图,前一步输入送入Attention LSTM得到当前步的隐藏向量,然后用这个隐藏向量结合视觉特征计算visual context:。
之后,在特征的维度上把和拼接,作为Language LSTM的输入,得到当前步的输出,再过一层全连+softmax得到字典内的概率分布。
以上是比较常规的操作,接下来是对Pointer-Network的拓展:之前检索出的topk个句子经过之前的bi-LSTM会得到向量。对于每一个句子,使用Language LSTM的隐藏向量来作为query进行attention:,这里是那条句子中每一个单词的注意力概率,而是根据这个注意力概率加权求和的context向量。
然后模型需要判断当前是copy好还是generate好,所以要计算一个,是第个被检索出来的句子。针对每一个句子,计算,也就是每一个句子都算出一个copy和generate融合的概率分布。
最后,topk个句子的融合概率分布再根据来加权求和得到最终概率分布,也就是下面这个式子:
然后就计算交叉熵了。
实验结果
这篇文章用了MSR-VTT和VATEX数据集
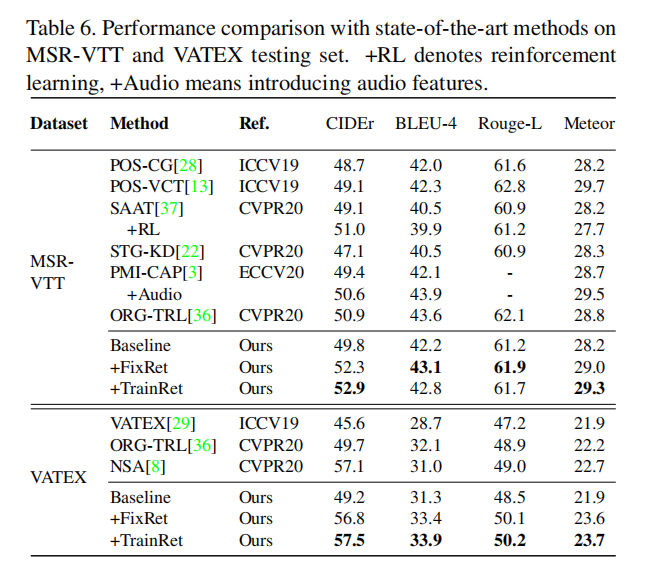
先看与其他人比较的大表,效果不错但也不算太惊艳
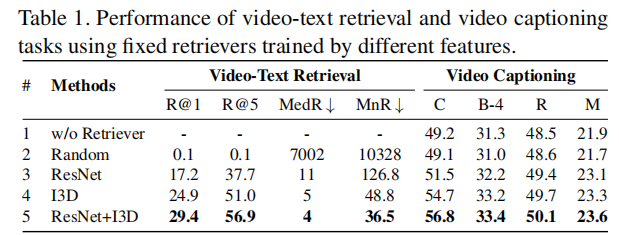
Tab1中可以看出,越好的Retriever能够更好地帮助VC任务。
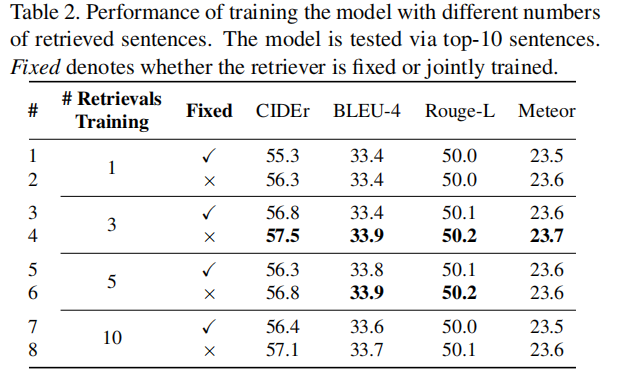
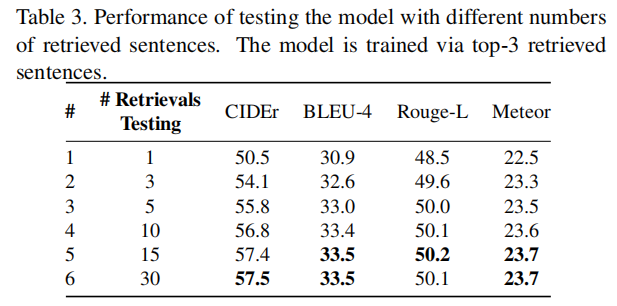
Tab2中可以看出,训练时检索出大概3到5个句子效果更好,Tab3则可以看出,测试阶段可以多检索出一些句子来直到饱和。
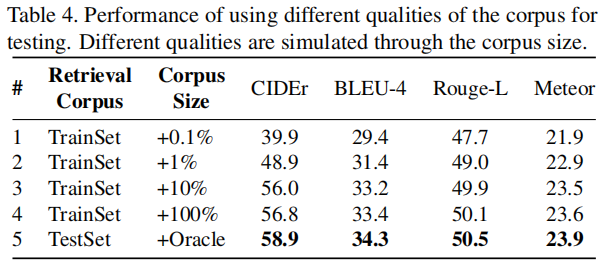
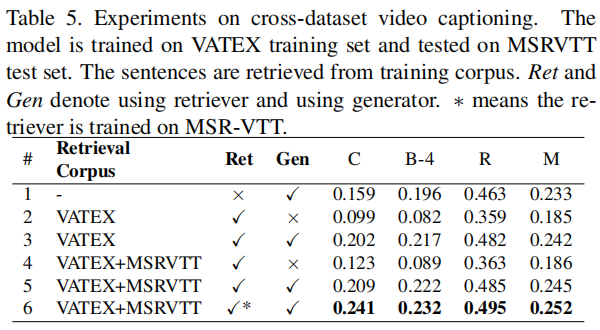
Tab4可以看出用来检索的语料库越大越好,越符合视频内容越好。(但是这里第五行的Oracle是什么东西???)Tab5也可以看出,在扩充语料库后效果会变好。(再吐槽一句这个论文怎么在这里指标就÷100了……)
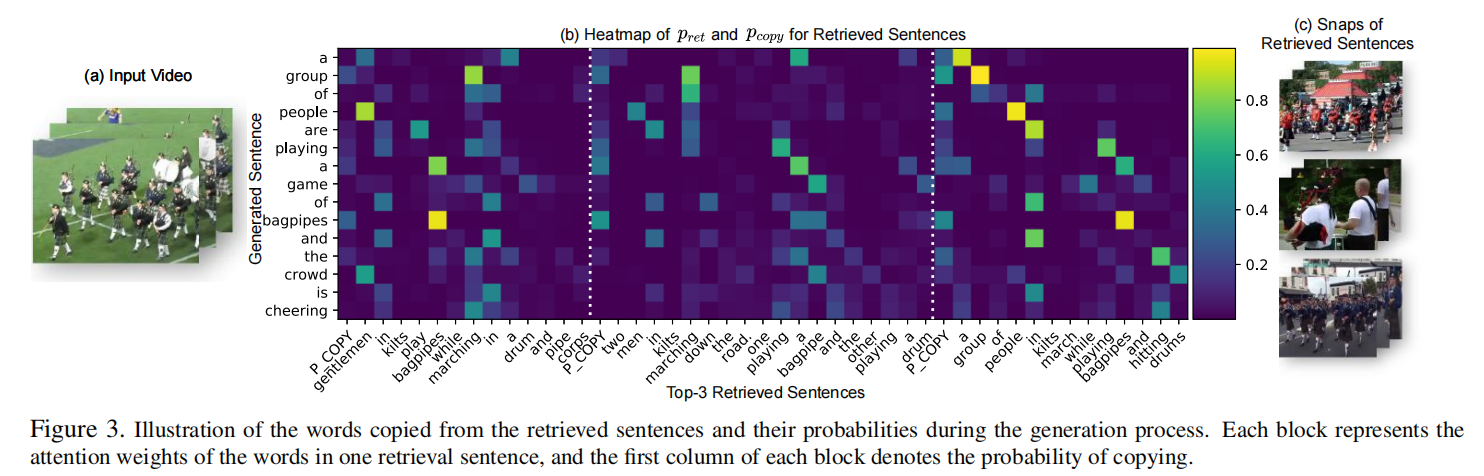
定性分析
下面都是一些可视化了,这个论文的可视化图做的是真不错!!!

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!