密码学 消息认证码(MAC)与散列函数(hash 哈希函数) 附代码
本文最后更新于:2023年1月8日 上午
密码学 消息认证码(MAC)与散列函数(hash)
**消息认证码(MAC,Message Authentication Code)**能够使用一个密钥K来浓缩一个任意长的消息M,数学表示为。易知MAC是一种多对一的函数,主要用来使通信双方确信消息内容未被更改。MAC需要保证:
- 假如某人已知消息和,也无法构造使。
- 假如改变的一个或多个bit,消息认证码相同概率极低
- 任意两个消息的消息认证码相同概率极低
消息认证码的实现算法中,通常使用散列函数(hash function)实现,这种实现方法统称散列消息认证码(HMAC)。常用的散列函数包括:SHA-1、SHA-256、MD5。
HMAC
HMAC在RFC2104中定义如下,其中是异或XOR,是拼接。
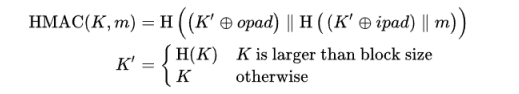
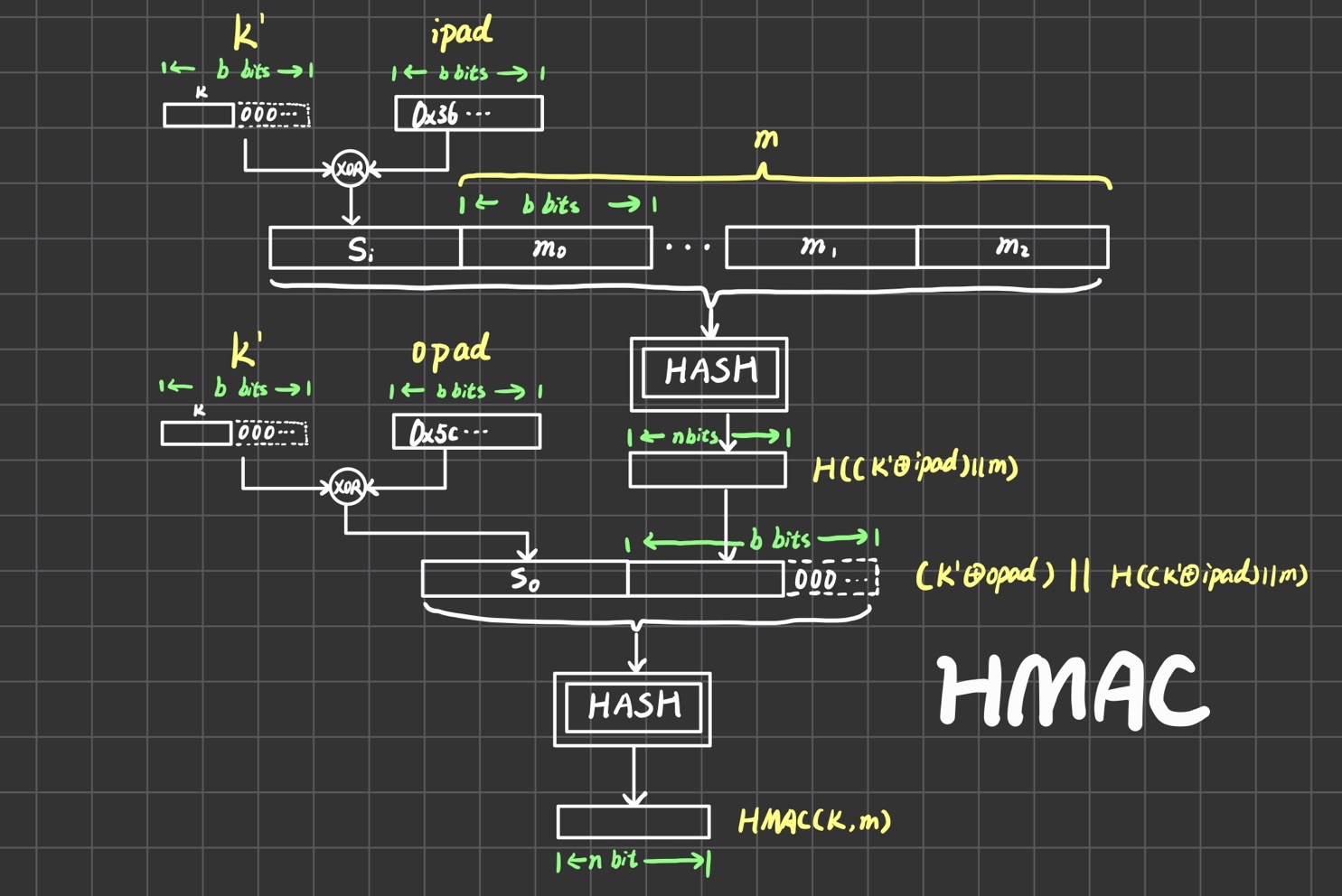
公式有点抽象,我画了个图。一开始要将密钥得到,即把不定长的密钥通过补0或者hash得到定长的b bit密钥,这里的是hash函数的分块大小。得到之后,需要和一个常数ipad进行异或,ipad是0x36的二进制循环重复。异或之后得到,和消息进行拼接后送入Hash处理得到n bit,这里的是hash函数的输出长度。之后和前面再进行一次类似的操作,就能得到最终结果。
散列函数 HASH
所有散列函数都有如下一个基本特性:如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。但是假如不同的输入得到了相同的输出,就发生了**“散列碰撞”**。
散列函数的输入一般是非常非常大的,可以将消息分块hash,输出值域是固定的。
| 算法名称 | block大小 | 输出大小 |
|---|---|---|
| MD5 | 512 | 128 |
| SHA-0 | 512 | 160 |
| SHA-1 | 512 | 160 |
| SHA-256 | 512 | 256 |
| SHA-512 | 1024 | 512 |
MD5原理
-
对消息进行填充
满足填充后长度mod 512 = 448,留出64bit表示原始信息长度。
填充方法是先填充一个
1,然后全填充0。填充是必须存在的,假如长度是是960mod512=448,那也需要填充512bit。
由于理论上信息无限长,所以表示信息长度的64bit进行取模循环使用。
-
分组
将上面的数据分成
512bit的block,然后每个block细分成16个32bitword,第个word用表示。 -
获取常数表
中一共有64个元素,每个元素是32bit的数字,由下面公式算出:
-
规定辅助函数F G H I
定义4个辅助函数如下:
-
初始化寄存器A B C D
初始化A、B、C、D四个
32bit的寄存器,初始值如下:1
2
3
4A: 01 23 45 67
B: 89 ab cd ef
C: fe dc ba 98
D: 76 54 32 10 -
进行运算
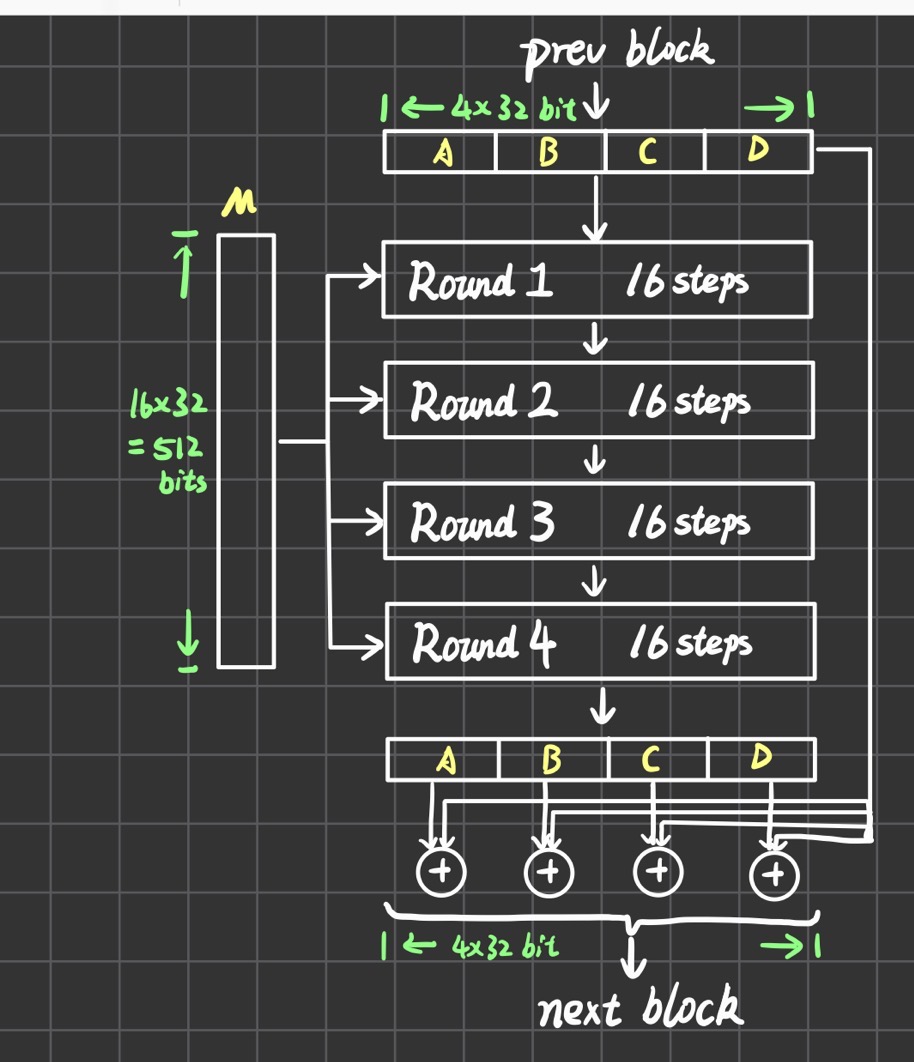
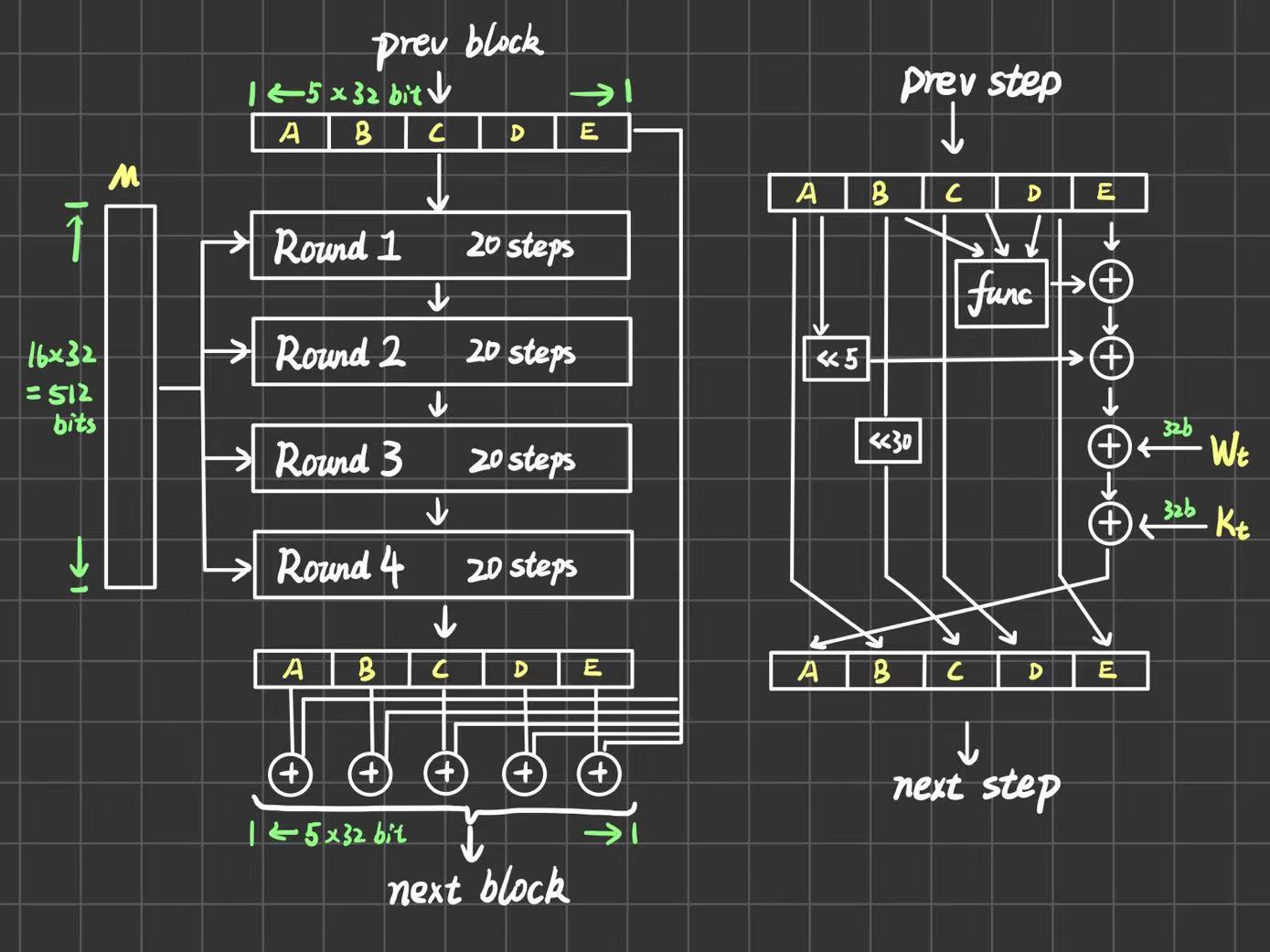
整体结构如下图,上一个block的输出作为当前block的输入(首个输入就用第5步的初始化),每一个block进行4轮运算,每轮运算又分成16步。在4轮结束之后,ABCD寄存器的值要和输入的ABCD寄存器值分别进行一个模32bit求和。
每一步的具体情况如下图,图中
func表示每一轮用到的辅助函数,就是第4点的FGHI,四个辅助函数分别对应4轮。图中所有的加法都是模32bit,<<表示循环左移s位。每一步需要三个参数i,j,s。这三个参数的确定如下: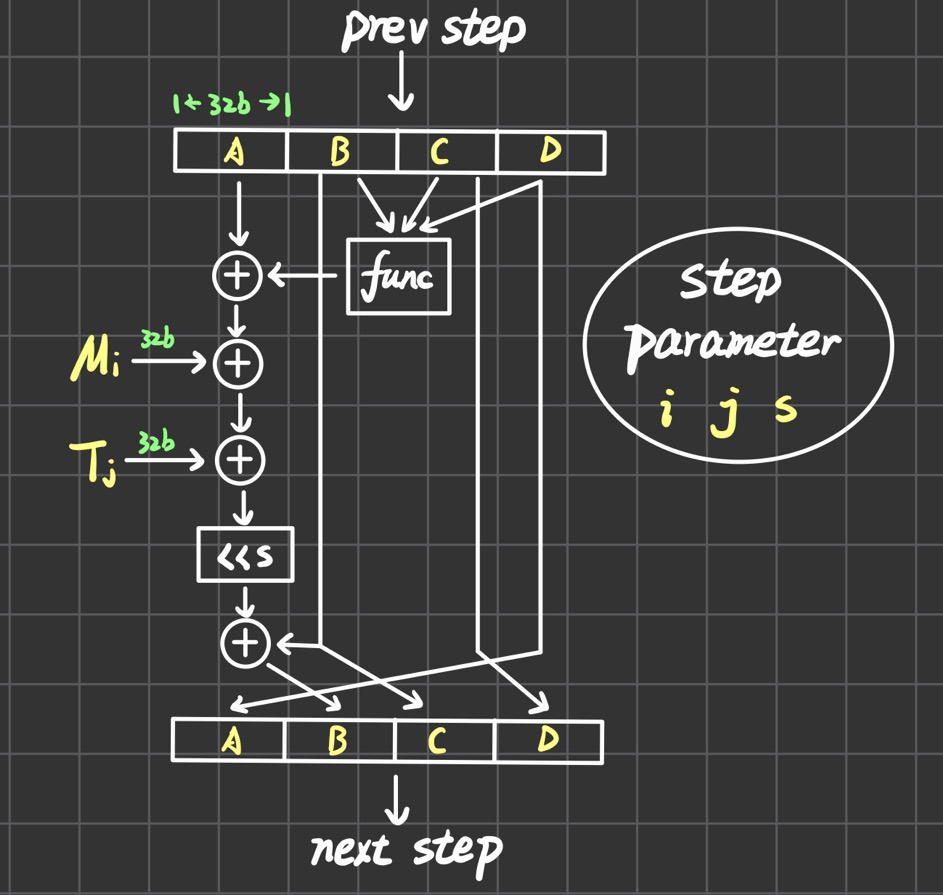
-
i设某一轮中第步
第一轮:;
第二轮:;
第三轮:;
第四轮:;
-
j四轮总共有64步,从这个角度的第步。
-
s第一轮:
7 12 17 22循环使用第二轮:
5 9 14 20循环使用第三轮:
4 11 16 23循环使用第四轮:
6 10 15 21循环使用
-
MD5实现
使用Python根据RFC1321.txt实现的MD5算法,转载请保留署名。
需要注意的是字节序!对应
reverse_endianness这个函数。比如用4Byte保存的数字8本来是
00 00 00 08,但是翻转字节序之后就是08 00 00 00了。算法中的寄存器初始值、信息长度、block信息和最后寄存器输出都要改变一下字节序。
1 | |
SHA1原理
SHA1和MD5整体流程极为相似,输出不同长度的原因是MD5是有ABCD四个32bit的寄存器,而SHA1有ABCDE五个32bit的寄存器,所以输出是160bit。
-
填充
和MD5一模一样,填充到448bit,然后附加64bit的表示长度的整数
-
分组
也和MD5一模一样,将上面的数据分成
512bit的block,然后每个block细分成16个32bitword,第个word用表示。 -
获取常数
只有4个数,但是整个数组有80个位置,对应80step。
\displaylines{K_{0-19}=5A827999\\\\ K_{20-39}=6ED9EBA1\\\\ K_{40-59}=8F1BBCDC\\\\ K_{60-79}=CA62C1D6 }
-
规定辅助函数
和MD5很像也有4个辅助函数,每个函数负责一个Round。其实可以发现第二和第四是一样的。
\displaylines{F_1(X,Y,Z)=(XY)\lor ((\neg X)Z)\\\\ F_2(X,Y,Z)=X\oplus Y\oplus Z\\\\ F_3(X,Y,Z)=(XY)\lor(XZ)\lor(YZ)\\\\ F_4(X,Y,Z)=X\oplus Y\oplus Z }
-
初始化寄存器ABCDE
5个32bit的寄存器,注意下面写的字节序是倒着的,直接赋值应该是
A=0x674523011
2
3
4
5A: 01 23 45 67
B: 89 ab cd ef
C: fe dc ba 98
D: 76 54 32 10
E: f0 e1 d2 c3 -
进行运算
总共有4Round,每个Round有20step,用表示总步数。和MD5一样,下面的都是的加法,都是循环左移,func是之前提到的辅助函数。和MD5不一样的是,每一步只有一个参数,在时,不变,当时,。
SHA1实现
和MD5实现差不多,但是完全不需要考虑字节序。转载请署名。
1 | |
参考文献:
Hash Based Message Authentication - YouTube
散列函数 - 维基百科,自由的百科全书 (wikipedia.org)
RFC1321.txt
FIPS PUB 180-1 SECURE HASH STANDARD
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!