网络爬虫进化史,原来你是这样的爬虫:第2期
本文最后更新于:2022年7月21日 下午
网络爬虫进化史,原来你是这样的爬虫:第2期
前言
上一期我们说到万维网被发明之后,马修·格雷(Matthew Gray)找到了从万维网上获取数据的好方法,并写出了历史上第一个爬虫——World Wide Web Wanderer,接下来我们将会进入到万维网的黄金发展时期——1993-1994年,同时也是搜索引擎和爬虫发展最迅速的时期~
What’s New?
假如让你上网,你最先想到的是什么?恐怕大多数人都会打开桌面上的Chrome浏览器。
然而在万维网刚开始的时候,人们使用的是蒂姆发明万维网时同时发明的万维网浏览器,名字也就叫做WorldWideWeb(后改名Nexus以防止混淆),这个简陋的浏览器的用户体验不是很好,既没有丰富的颜色,也不能显示图片。当时这个浏览器运行在NeXTSTEP操作系统上,而这个操作系统早已支持彩色图形化的操作界面,WorldWideWeb的界面是在引不起用户的兴趣。
你可以在CERN的这个网站重温当年的浏览器https://worldwideweb.cern.ch/browser/
于是,Mosaic浏览器横空出世,这是第一个早期普及的网页浏览器,它不仅具有更好看的界面,而且它还可以在文字中嵌入图片。并且在1993年,Mosaic推出了一个叫做What’s New的页面,这个页面几乎每天都会给公众提供一个全新网站的链接。在当时,这个页面吸引了很多人的眼球,要知道,1992年11月的时候世界上才只有26个网站,所以每一个新网站的出现都是引人注目的。
在What’s New功能出现初期,这个页面是无法自动更新的,需要靠开发者手动添加页面,来自斯特灵大学计算机系的一名毕业生乔纳森·弗莱彻( Jonathon Fletcher)发现了这个问题,所以他发明了JumpStation爬虫,在1993年底,JumpStation爬遍了全世界,记录了2万5千个网页,在乔纳森为其加上搜索工具后,Mosaic的What‘s New就形成了世界上第一个网页搜索引擎。Mosaic和它的What‘s New非常辉煌,据说在当时What’s New可能是万维网上访问量最高的单个页面,在1994年,获得了最重要服务概念奖(Most Important Service Concept)。
更多爬虫的出现
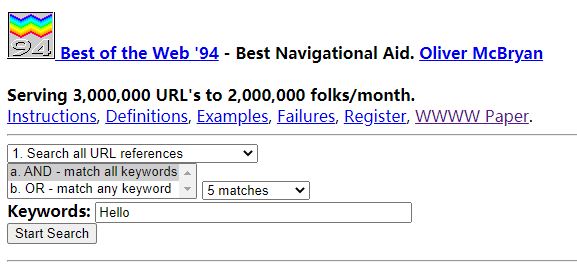
**93年在学术界也有崭新的爬虫出现,那就是World Wide Web Worm,简称WWWW。**与之前的爬虫不一样,这个爬虫还支持正则表达式搜索。正则表达式是一种“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
比如[1-9]\d{5}(?!\d)这一句正则表达式表示中国的邮政编码格式,能匹配100001这样的字符串
再比如((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}这样的字符串,能匹配192.168.0.1这样的IP地址。
看到这你是不是已经头大了?虽然正则表达式很难被计算机小白们理解,但是在没有google之前,搜索引擎能准确的找到东西都是一个问题,虽然使用正则表达式稍微麻烦一点,但是他还是得到了很多人的喜爱。WWWW在1994年爬取到了11万个网页,并它获得了年度最佳导航网站的奖项。
**然而WWWW和JumpStation,都遇到了一个问题,那就是数据的储存。**WWWW的作者并没有能力保存下爬取到的所有数据,于是只保存了爬取到的网页的前几级标题,而JumpStation的开发者没有得到斯特灵大学的投资,即使是只保存标题,也在1994年由于缺乏资金来购买存储介质而停止了开发。(当初数据的存储器是非常非常贵的)
而*休斯顿大学财大气粗,启动了*RBSE(Repository Based Software Engineering Program)项目,这个项目也开发了一个爬虫,与WWWW和JumpStation不一样,RBSE的爬虫会存储并索引HTML页面的全文,这与当下的搜索引擎更为接近。我们在搜索引擎中输入的关键词搜索到的网页更可能是与正文内容匹配,而不仅是标题,这大大提高了搜索引擎的准确率。RBSE总共获取到了100MB的数据,他们的搜索功能获得了平均每天300个访问,最高900次请求的成绩,作为一个研究项目,RSBE的成果可以是非常成功的。
RBSE spider还是第一个提出注重爬虫礼仪的爬虫,上一期提到,马修写的爬虫出了问题,导致互联网出现了大拥堵,于是开发者约定了robots.txt,而RBSE提出,在访问网站的时候会在User-Agent中添加RBSE-Spider/0.1的字样,并且通过优化代码降低对互联网的影响。

接下来要介绍的爬虫成功存活到了现在,那就是WebCrawler。
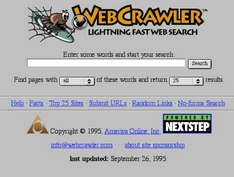

这个与爬虫的英文同名的爬虫在1994年爬取到了总共4000个网站,在年底,用这个爬虫构建的搜索引擎就迎来了它的第一百万次搜索。(据说第一百万次的搜索内容是“核武器的设计和研究”)比起RBSE,WebCrawler同样也能进行全文搜索,不同的是,WebCrawler比RBSE爬取的范围更大更广,而且WebCrawler能够同时下载15个网页,这意味着搜索引擎数据库更新的速度也更快。
互联网泡沫
这个优秀的产品迅速吸引了资本的注入,在1995年,美国在线(AOL)收购了WebCrawler,然后对WebCrawler进行了商业化,即在搜索结果的边上放置广告位,通过广告位收费来盈利。在1996年,WebCrawler达到了它的顶峰,当时这个网站是是互联网上访问量第二高的网站,它的服务器甚至经常因为访问量太高而崩溃。
然而,好景不长,Inktomi开发了一个叫做Slurp的爬虫,并研发了Inktomi搜索引擎,关于这个爬虫的资料比较少,所以我也无法详细介绍,但是Inktomi与其他搜索引擎不同,他不直接提供搜索功能,而是向合作伙伴卖技术来盈利,雅虎、Infoseek、Lycos、Excite甚至微软MSN都在使用它的技术。于是,WebCrawler在竞争中处于劣势,然后几经转手,虽然现在还苟活着,但是它已经没有独立的数据库来支持搜索功能了,它成为了一个元搜索引擎。元搜索引擎和百度、Google这样的独立搜索引擎区别很大,前者的数据来源是多个独立搜索引擎甚至是其他元搜索引擎,拿到手的数据再经过自己的整理、优化然后再呈现给用户。
之后,互联网泡沫逐渐形成了,我对经济学不是很了解,但是对于上世纪九十年代美国的互联网泡沫的形成原因,大概就是那些投资人把太多的钱给了没有前景没有技术只会讲故事的互联网公司。其中Yahoo就是受到打击很严重的企业之一,Yahoo没有自己的搜索引擎技术,甚至在很长的一段时间内,它是手工对网站进行分类的,这样不牢固的基础,使得它在泡沫破裂的时候市值蒸发了90%。

总结一下这场泡沫,那就是对于搜索引擎和爬虫领域,没有足够强技术的WebCrawler没落了,没有自己技术的Yahoo失败了,反倒是有技术但是不直接和消费者打交道的Inktomi生存下来了,由此可见,科学技术还是非常非常重要的,咱们只有掌握了核心的技术才能在大风大浪来临时稳操胜券。
虽然20世纪末的互联网泡沫破裂导致了一大堆.com公司倒闭,但是存活下来的公司大多到如今都成为了互联网界闪耀的明星,比如Amazon、eBay、PayPal、Netflix,最具代表性的当然还有我们接下来要介绍的Google,在这些公司当中,Google的日子算是过的最好的,它在泡沫期间不仅几乎没有受到负面影响,甚至在泡沫爆破后还能进行公开招股。这和他们的经营方法有关系,也和Google爬虫的强大技术有关系。
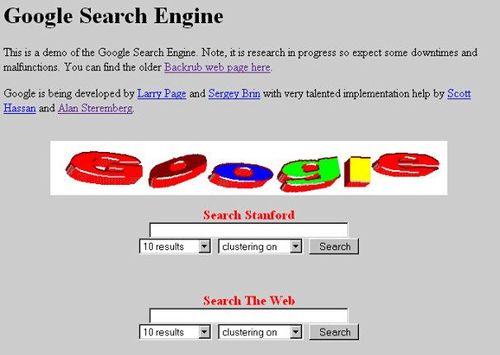
Google的最初版本是由斯坦福大学的拉里·佩奇和谢尔盖·布林开发的,Google这个词起源于Googol,也就是这个数字,他们想让自己的搜索引擎能够大到Googol这么大,于是,他们又带了一位斯坦福的博士同学克雷格·希尔福斯坦出去创业。
Google搜索的爬虫从开始就被设计成为一个大范围的、通用的网络爬虫。当时的技术对于查找到万维网上的资源已经不是个很大的问题,但是可能出现搜索某个关键词,出来的结果十条只有两三条是相关的情况。甚至当时冒出的很多搜索引擎为了节约存储资源,不仅不爬取网页全文,连标题也不爬全,对于虚词(to not be)不做索引,结果这些搜索引擎对于莎士比亚的那句话“To be or not to be”的搜索结果就是空。而Google可以做到十条结果能有七八条是相关的,而且能够搜索到“To be or not to be”。
Google的爬虫在存储、搜索、爬取三方面做出了创新:
-
之前其他爬虫遇到的问题,Google爬虫也遇见了,那就是数据的存储问题,Google为了保证搜索的准确性,肯定也是进行网页全文爬取的,它对存储过程进行了大量的底层优化,包括将爬取到的网页进行压缩后存储、并创建索引来减少磁盘访问时间。
-
Google爬虫在搜索算法方面发明了一个存活至今的叫做PageRank的算法,其基本假设是:**更重要的页面往往更多地被其他页面引用。**这个算法将互联网的网页看做节点,将超链接看做边,形成一张非常大的有向图,指向某个网页的超链接被看做对这个网页的“投票”,而这种“投票”的权重由超链接所存在的网页权重有关。假如一个非常热门和权威的网页上出现了你的网站的链接,那么你的网页权重就会升高,假如有非常多的网站都出现了你网站的链接,那么你的网页权重也会升高。虽然目前该算法早已不再是Google用来给网页排名的唯一算法,但它是最早的,也是最著名的算法。

我们有的时候能在一些网站底部看见一些超链接,这些被称作友情链接,网站的站长们为了让自己的网站在搜索引擎中能排的更前,会与其他网站的站长商量,在网页不起眼的地方互相加上网站的链接,这就是根据PageRank算法所耍的小聪明。

-
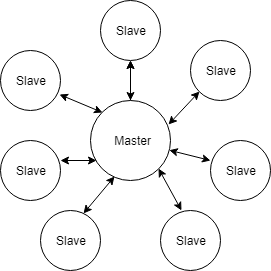
在爬取速度方面,Google使用了主从式爬虫架构(Master-Slave),这种架构的核心思想就是“分而治之”,自此,爬虫从单一作战成功进化成群体进攻。主从式架构的主服务器(master)将一个原始的大任务分解成一系列小任务,然后分配给子服务器(Slave)执行,然后再主服务器收集产生的结果。这种架构虽然不是最佳的解决方案,但是在当时Google做到了每秒100个页面的下载速度。
接下来?
爬虫已经完成了第一阶段的进化,它们在搜索引擎中发挥巨大作用,它们帮助Google度过互联网泡沫,它们开始成群结队有纪律地向万维网发起进攻,然而,随着爬虫的威力越来越强,万维网的规模也在逐渐加大,那座传说中的互联网冰山正在形成,爬虫能将他的魔掌伸向冰川之下吗……
这篇文章也发布在下面这个公众号数媒极客,公众号里面有其他很有趣的文章,可以扫码看一看~

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!