网络爬虫进化史,原来你是这样的爬虫:第1期
本文最后更新于:2022年7月21日 下午
网络爬虫进化史,原来你是这样的爬虫:第1期
导语
2020年的一个平淡的一天,累了一天的你打开手机,发现满朋友圈的“手把手教你写Python爬虫爬取小姐姐照片”广告,有没有疑惑过爬虫究竟是个啥?怎么突然就这么火了?
接下来这个系列的文章将会告诉你,爬虫是如何从一只小虫,变成布满整个互联网、在所有人面前张牙舞爪的可怕巨虫的。
出生之前
我们的故事要从1989年的瑞士开始。在瑞士日内瓦西部与德国的边境处有一片荒野,在这片荒野里,一群智商高达250的精英们躲在这偷偷研究世界上最小的物质——这里建立着世界上最大的粒子物理学实验室:欧洲核子研究委员会(CERN)。八十年代,切尔诺贝利事故的阴影笼罩在整个欧洲上空,然而年轻的**蒂姆·伯纳斯·李(Timothy John Berners-Lee)**和其他CERN的科学家们却没有停下脚步,仍然在继续研究。
话说这蒂姆并不是很有名气的资深教授,CERN的研究也轮不上他,但是Boss也不能让他闲着,看蒂姆的爸妈都参与了第一台商业电脑**曼切斯特1型(Manchester Mark I)**的发明,就让他开发个计算机软件,目的能让CERN与其他国家的研究室更加便捷地交流。
蒂姆虽然拿到了牛津的荣誉物理学士学位,本该研究物理,但是他还是接了这项工作。令人出乎意料的是,不久之后,在1989年的夏夜,世界上第一个Web服务器和客户端出现在了CERN的一台NeXT计算机上。他将这项技术命名为World Wide Web,也就是www,或者叫做万维网,从此,互联网的青春开始了。

等等,你不是要讲爬虫吗,怎么讲起万维网来了?
别急,蒂姆发明万维网的同时,还带来了三项关键的技术,这三项技术为爬虫的诞生构建了温床,那就是URI、HTML和HTTP。
先说最基础的http吧,这个大家应该不陌生,你打开浏览器访问任何网页的时候,看网址开头都是http://。爬虫说到底还是一堆0和1,它们靠着http在万维网中伸展拳脚。
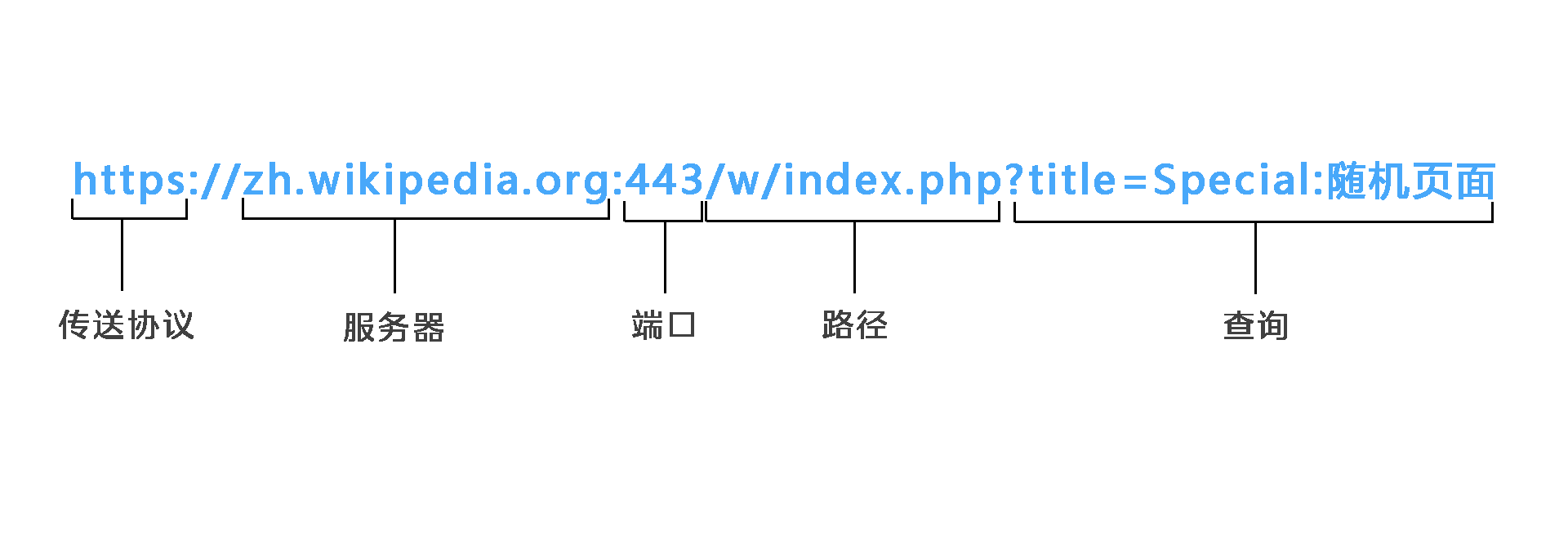
之后就是URI,用来精确定位互联网上的资源,简单说就是咱们说的网址,网址各部分的意思如图所示,通过一堆字符确定了服务器、端口、路径、内容和传送的方式,爬虫靠着他提供的“地址”敲响每个服务器的门。
最后就是HTML,这是与爬虫联系最精密的一项技术。HTML是超文本标记语言,作家写文章的时候可能会给编辑留下一些非正文的消息,比如
作家:
……我家门口有两棵树,其中一棵是枣树,另一棵也是枣树。(注:这两棵树品种不同)……
编辑:
把括号里的文字放在书的最下方,并用小号字体标注是注释,正文中删去括号中的话。
HTML就是作家写的原文,网页编写者通过<h></h>这样的标签对来标记文章的内容,然后咱们优秀的编辑——浏览器把这些标签解释出来,然后形成你现在正在看的这个网页。有了这些标签,你就能看见这些有粗体 斜体 大小颜色不同的字了。这让人们能把他们宝贵的知识放到网上共享,也能让你天天在微信发各种各样的朋友圈,而这些有用的数据就是爬虫的最终目标。
值得一提的是,HTML有一种特殊的标签<a>,被这个标签标记的文本会被认为是一个超链接,超链接的发明,让阅览网页与阅读书籍产生的本质上的区别,这是一种**“所见即所得”**的体验,比如这篇推送的“阅读原文”,你只要动动手指点一下阅读原文就能跳转页面过去,而不是从书架上翻一本新的书。超链接就像虫洞一样,爬虫靠着这个完美的交通工具,在万维网上爬来爬去。
万维网需要爬虫
之前我们说到那蒂姆发明了万维网,在1991年这项技术被公之于众之后,它可是成了当时的“网红”,1993年只有130个网站,1996年就有十万个了,1993年Web服务器占比1.5%,1996年就已经有50%的服务器是Web服务器了。如此快的增长速度,也伴随着巨量的数据,而数据一多,要找到特定的数据就尤为困难。假如你想知道爬虫是啥,你可能打开电脑首先就百度去,可是当时的人没有搜索引擎,他们使用一种类似黄页的东西,要查询到爬虫是啥,他们可能会选择从厚厚的书中找到某生物研究机构的主页,然后在控制台敲上网址,然后访问(虽然结果还是无功而返)。

其实在万维网发布之前就出现了第一个搜索引擎——Archie,不过它与百度谷歌相差甚远,它只是一个搜索匿名ftp下载服务器的脚本。ftp是文件传输协议,在万维网出现之前就已经流行起来,即使是当下也有很多文件是通过ftp协议下载的。Archie虽然叫做搜索引擎,但是搜索功能很蛋疼,用户搜索的每个字都必须要精确符合标题才可以搜索到结果,但即使功能如此简陋,但是在其巅峰时期,使用这个引擎的流量占据蒙特利尔总带宽的50%。
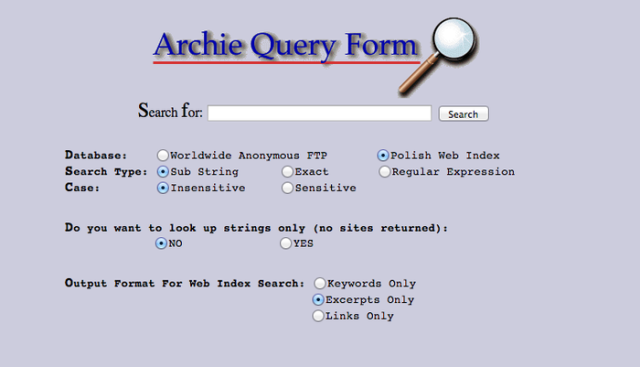
Archie体现了搜索引擎的需求,而开发者们选择了两种方式来开发搜索引擎:
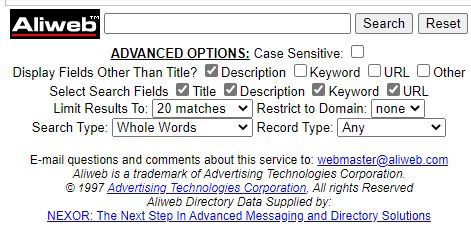
马丁·科斯特(Martijn Koster)的尝试是ALIWEB,这是最早的万维网搜索引擎之一,于1993年12月发布,ALIWEB的数据来源是用户的主动提交,它允许网站站长上传他们网站的URL,并手动添加描述,之后用户就可以通过ALIWEB查询到对应的网站。然而,来提交网站的站长并没有马丁想象的那么多,有的可能不知道如何提交,有的可能懒得提交,有的可能根本就不知道这个网站,所以ALIWEB就这样慢慢的消失在了互联网的发展长河中。
而另一波开发者选择了一个更聪明的数据获取方式,他们准备发明一个能够自动环游万维网的探索者,主动去探索万维网,获取网站的信息,再通过算法索引它们来建立搜索引擎,这样就不需要被动的等待站长们来提交网页了。
然而他们都没有想到,这是一个潘多拉宝盒,这个探索者转眼间就变成了依附于万维网上的爬虫。在三十年后的今天,这些爬虫密密麻麻地分布在网络上,互联网的每个角落都有爬虫的身影,即使是冰山底下的暗网也被特殊的爬虫涉足,据传言,互联网上50%的流量都是爬虫创造的,也许人们称这项技术为“爬虫”时就已经潜意识认为这项技术像爬虫一样,虽然无害甚至有益,但总是让人恐惧。
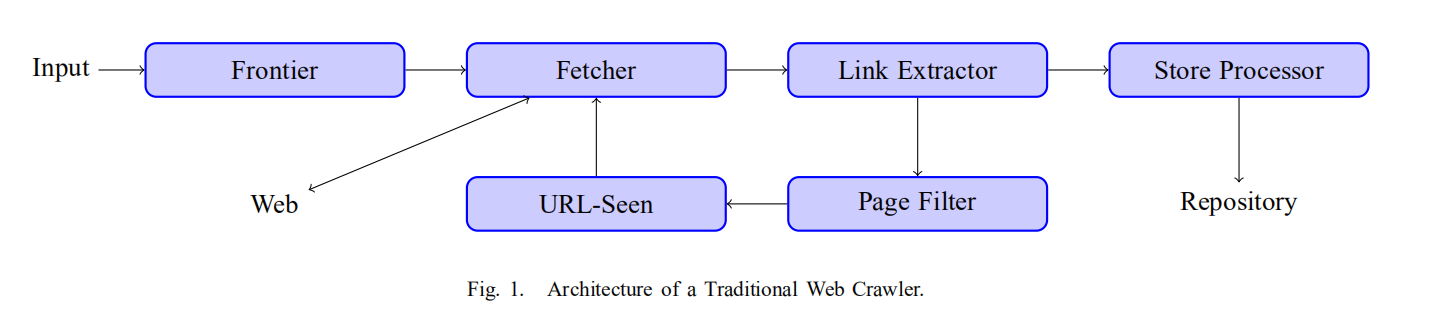
工程师们最初设计的传统爬虫的结构由图中这几部分组成,这是一个很简单的架构,简单来说就是获取网页->提取网页的数据和连接->从新获取的连接中获取新网页。
我们可以把爬虫想象为一位攻城掠地的常胜将军,他带着初始的补给去攻打一个个城池,每攻下一个城池就能获得新的补给,然后他就带着新的补给去攻打新的城池……直到他征服了全世界。
然而,有的将军脑子不是那么灵光,他走到一个城池地下,在脑子里想半天才能回忆起来这个城池是否已经攻略,还有的将军的战略不太好,攻下一个城池的时间过于久,以至于他一辈子也征服不了世界。这些都是常胜将军的训练员——爬虫工程师们将要解决的问题。
初露锋芒
虽然爬虫的需求是依附于搜索引擎的,但是世界上第一个爬虫程序并不是用于搜索引擎的。
在万维网成为“网红”并展示其惊人的发展速度后,MIT的一位学生,马修·格雷(Matthew Gray),决定研究一下万维网的拓张速度,于是他在1993年写下了历史上第一个爬虫——World Wide Web Wanderer。
马修使用了当时热门的Perl语言来编写这个爬虫,爬虫会生成一个叫做Wandex的Web数据库,这个数据库里存储着爬取到的所有URL和服务器,只要稍加改进,这个数据库就能成为搜索引擎,比雅虎和谷歌早了好多年。然而马修只想着他的课题——研究万维网的拓张速度,并没有兴趣开发搜索引擎。

马修的爬虫引起了许多人的关注,早期的代码也在互联网上广泛流传,然而还是学生的马修写出的代码出现了严重的bug,再加上许多人同时运行这个爬虫,导致相同的一个页面一天被访问上百次,在带宽不高的当时,这样的访问直接让几个服务器宕机了。隔壁ALIWEB的马丁立刻在万维网开发者的讨论区——www-talk中喷了一波爬虫,并且提议设立机器人排除标准(Robots Exclusion Standard),又叫做robots.txt。这是历史最悠久并存在至今的反爬虫技术。
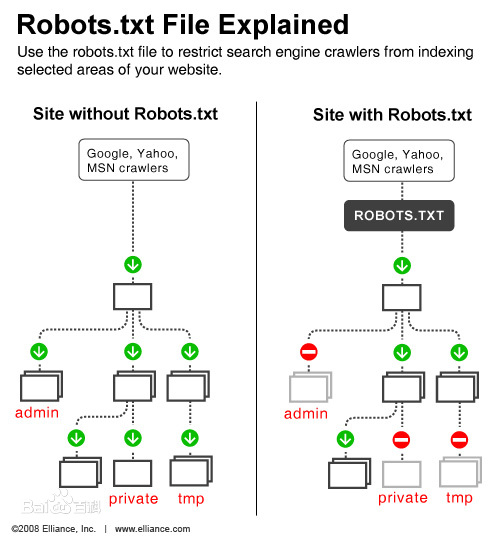
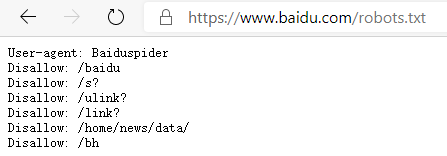
可怜的爬虫技术,自其一出生就遇见了死对头,爬虫与反爬虫从此开始了道高一尺魔高一丈的斗争。爬虫的合法性常常被人质疑,俗话说“爬虫写得好,牢饭吃得早”,由于反爬虫技术越来越强,反反爬虫技术也一直革新,而反反爬虫有被认为是非法盗取信息以及侵犯隐私的嫌疑,于是许多爬虫开发者都游走在灰色区域。在国外非常著名的案件有eBay VS. Bidder’s Edge案,在国内有百度起诉360搜索案,然而这都是后话……
robots.txt是什么呢,其实并不是什么高级的技术,只是在网站的根目录下的一个普通txt文档而已。与其说它是网站的高大城墙,不如说它是酒店房间门口挂的“请勿打扰”,站长可以通过编辑robots.txt来指定爬虫能爬取哪些页面,或者指定哪些不道德的爬虫不允许来爬取这个网站,但是这些规则都不是强制性的,爬虫技术上完全可以无视这些规则。
接下来?
1993年和1994年是爬虫发展最为迅速的两年,许多爬虫的开发都是同时进行的,几乎每个月都能有新的爬虫出现,一张大网已经为织好,接下来,就有请它们闪亮登场吧……
这篇文章也发布在下面这个公众号数媒极客,公众号里面有其他很有趣的文章,可以扫码看一看~

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!